Apply Model¶
The Apply Model task applies the models generated by classification, regression and clustering tasks to new datasets.
It is normally made of two tabs:
the Options tab
the Results tab
The Options tab¶
The Options tab contains all the options to customize how the created model can be applied to new data. The available options and the task’s layout vary according to the generated model.
The first panel, located on top of the screen, has the same layout in all the occurrences, and contains the following options:
- Available models: select the currently available input you want to apply from the drop-down list. The possible options are:
Rules (LLM and Decision Tree tasks)
Models (Regression and the other Classification tasks)
Clusters (Clustering tasks)
Save confusion matrix (if available): if selected, the confusion matrix (which is generated only if there were some classification problems) is saved in the execution information of the task. This information is displayed in the Results tab of the computed task. As this may result in a large amount of data, it may be preferable not to save it.
Use output to index previous clustering: if selected, the model will be applied in classification problems only, when possible.
Append results: if selected, the results of the current computation are appended to the dataset, otherwise they replace the results of the previous computations.
Model generated by classification tasks
When the Apply Model task is linked to a classification LLM or Decision Tree task, three panes are added to the model panel: the first one, located on the top part of the screen, contains the available models and their settings. The second one, located at the bottom-left part of the screen, contains the options defining the modality of application of the model and the output dataset’s characteristics. The third one is located at the bottom-right part of the screen, containing the weight settings for the output value.
The options available in the model settings area are listed in the paragraph above.
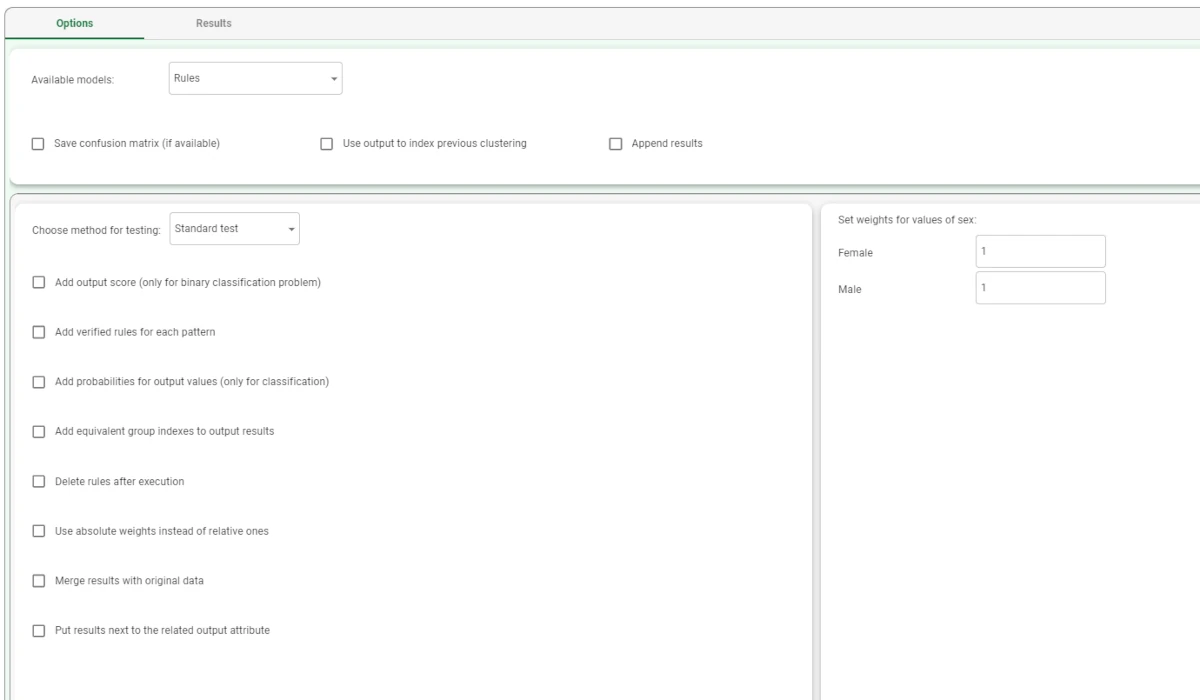
The options available in the testing method area (when the input tasks generate rules) are:
- Choose method for testing: select how to apply rules to the data. The possible values are:
Standard test: one output value is considered at a time and the relevances of all the rules pertaining to that value and satisfied by the input pattern are summed; it is then normalized using the sum of all the relevances of the rules of the corresponding class. The relevances obtained are then compared, and the output value associated with the greatest is assigned to the pattern. If the Use absolute weights instead than relative ones checkbox has been selected, the results are multiplied by the cardinality of the classes and then compared. If weights have been specified by the user in the Set weights for values of output pane, the score for each class is multiplied by the corresponding weight, as well.
Modified test: it is calculated in the same way as the standard test, except that it also considers rules that match except for one condition, assigning a weight of 0.1 to their relevance value.
AND-OR test: it sorts rules according to their relevance, from highest to lowest, and then assigns the output value associated with the first rule covering the input pattern.
Add output score (only for binary classification problems): if selected, a column is added, with a continuous value between -1 and +1, which represents the precision of the classification. For example, if the class “true” is +1, a score of 0.99 means the output almost certainly belongs to the class “true”.
Add verified rules for each pattern: if selected, all verified rules are displayed, instead of the most important rule only.
Add probabilities for output values (only for classification): if selected, a column is added, with a probability of the precision of the class prediction.
Add equivalent group indexes to output results: if selected, the index of the ambiguity group is added. An ambiguity group is a group of rows with the same input value.
Delete rules after execution: if selected, rules are deleted after they are applied. This is useful when you want to apply the rules once only.
Use absolute weights instead of relative ones: if selected, the frequency of the class within the training set is considered when calculating the weight associated with each rule.
Merge results with original data: if selected, once applied the attributes and results are saved in the same structure.
Put results next to the related output attribute: if selected, the results of each attribute are displayed next to the attribute itself. This option is available only if you have selected the previous option to merge results with previous data.
In the weight settings area, users can use the Set weights for values of the_output_attribute area to set weights for each possible output value of the specified attribute through a dedicated number field.
Weights indicate the importance of a value over the other ones: higher weight values will indicate higher importance of the corresponding value. For example, if the value True has a higher weight than False, the task will take into account that True is the preferred output value by the user, and errors on True are discouraged.
When the Apply Model task is linked to a KNN Classification task, only one option is available, which is the Number of points used option, where users can type the number of points which will be used in the model application.
Model generated by regression tasks
When the Apply Model task is linked to a regression task, to a Neural Newtorks Classification or to a SVM Classification task, the task contains the model panel only.
Model generated by clustering tasks
When the Apply Model task is linked to a clustering task, to a KNN Classification or to a KNN Regression task, the task contains the model panel and another panel, where the following options can be set:
- Distance method for evaluation: select the method required for distance, from the possible values: (more information on the values below can be found at the corresponding page)
Euclidean
Euclidean (normalized)
Manhattan
Manhattan (normalized)
Pearson
Replace output after forecast: if selected, during the execution the Apply Model task searches for a Cluster id column and turns it into an Output. Each row of this column is then filled with the index value of the corresponding cluster.
Use distance between profiles in Label Clustering: applies label clustering using profiles instead of labels, as if it was being a normal clustering system.
The Results tab¶
As the task’s settings vary according to the input they receive. So, also the results shown in this tab vary according to the input it receives.
It is divided into two panes: the General Info and the Result Quantities panels.
In the General Info panel, the following information is provided, no matter which input they receive:
Task Label: the task’s name on the interface.
Elapsed time (sec): it indicates how long it took to complete the computation.
The Result Quantities panel provides detailed result quantities, and the results shown vary according to the input received.
You can check or uncheck the quantities above to visualize them in the results list. You can visualize their specific values by clicking on the arrow next to them.
Note
For each result quantities, the results are divided in four groups: the Train (used to build the model), Test (used to assess the accuracy of the model), Valid (used for tuning the model parameters) and Whole groups, containing the corresponding counts.
Result Quantities for classification tasks
The Result Quantities provided by the Apply Model task when it is linked to a classification task are the following:
Accuracy
Correctness(%)
Coverage
F-measure
Matthews correlation coefficient
Negative predictive value | Negative reliability
Novelty
Number of samples
Precision | Positive predictive value
Relative negative reliability
Relative precision
Relative sensitivity
Relative specificity
Samples not covered by rules
Satisfaction
Sensitivity | Recall | True positive rate
Specificity | True negative rate
Support | Frequency
Total number of samples for each class
Result Quantities for regression tasks
The Result Quantities provided by the Apply Model task when it is linked to a regression task are the following:
Error on data samples
Number of samples
Relative error on training samples
Result Quantities for clustering tasks
The Result Quantities provided by the Apply Model task when it is linked to a clustering task are the following:
Davies-Bouldin index
Error on data samples
Error on remaining samples
Error on samples leading to a proper cluster
Number of clusters
Number of remaining samples
Number of samples
Number of samples leading to a proper cluster
PseudoF index (Calinski-Harabasz criterion)
Relative PseudoF index
Example¶
The following example uses the Adult dataset.
In this example, an LLM classification task has been used to generate rules.
Add an Apply Model task to the flow and link it to the LLM classification task.
Double-click the task to open it and leave the default settings.
Save and compute the task.
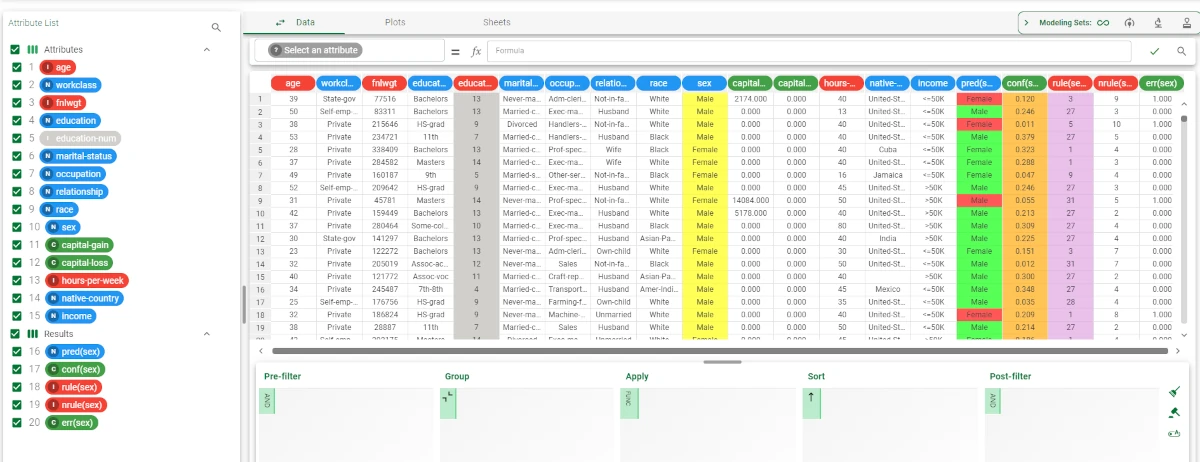
Right-click on the Apply Model task and select Take a look. Alternatively, you can add a Data Manager to the flow and link it to the Apply Model task.
The model has been applied to the source data, and new columns are added, according to the analysis performed.