Rule Viewer¶
The Rule Viewer is a task designed to visually explore rules through an interactive graphic that changes based on chosen parameters. It gives users comprehensive information about the most important rules, their attributes and the relationship between output and input attributes.
This task can be used to analyze set of rules.
Rule Viewer layout¶
The Rule Viewer task is made of only one tab, which takes its name from the output attribute, and it is divided into three areas:
The Output value area: it is located on the left side of the task, and contains information about how to read the rule chart, such as the value of the output attribute for classification problems, and the number of rules.
- The Rule chart area: it is located in the middle of the task, and users can find the chart displaying all the rules. It is divided into two separate parts:
Internal rules space which displays the rules.
External rules space which shows the attributes included in the rules.
- The Settings area: it is located on the right side of the task, where users can configure and visualize settings. Users will find:
an information icon, which displays a legend to help users reading of the rule chart. It contains graphical explanations for each characteristic of the circle.
a settings icon, from which users can customize the following options:
Nr. of attributes to show: users can define the number of attributes to display in the rule chart by moving the slider.
Relevance Threshold: users can define the relevance threshold by moving the slider.
Sort attributes by: users can define how to sort attributes in the plot chart by selecting one of the options below:
Absolute Relevance
Relevance for class
Export Rule Viewer: if users click on the PNG icon, they can choose to export the rule chart of the Rule Viewer task in PNG format.
Internal rules space
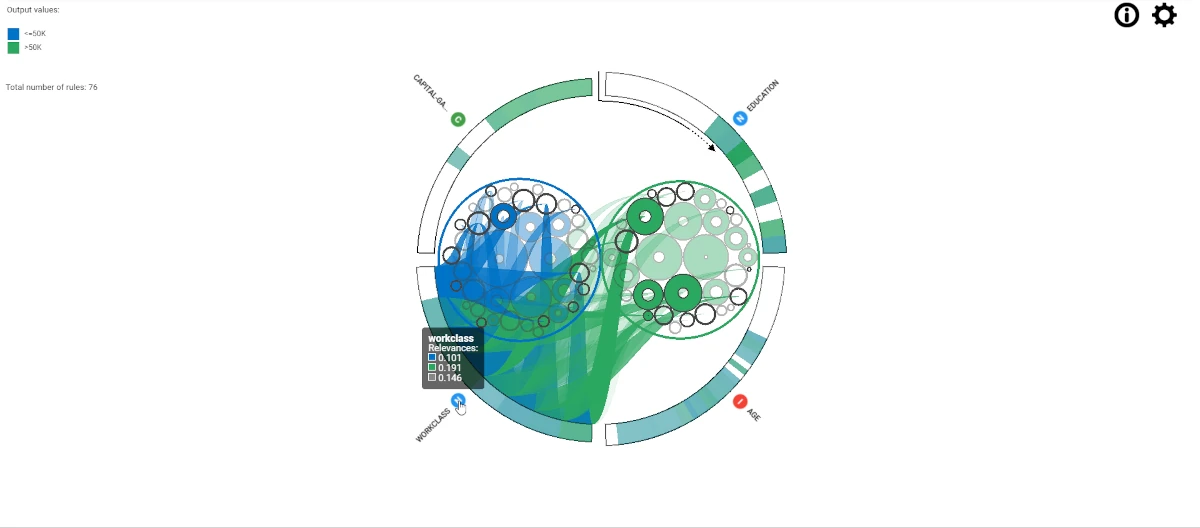
The internal rules space displays circles that correspond to specific rules.
Each circle represents the covering of a rule - the percentage that filtered rules must respect - with the size of the circle being proportional to the covering. The bigger the covering of the rule, the bigger the circle.
The hole inside the circle corresponds to the error committed by that rule. The bigger the hole, the higher its error percentage.
Moreover, the color of each circle matches the output class color as defined in the Output value area.
The ruleset is further organized into subsets of circles that contain rules with the same output class.
As mentioned above, the entire internal rules space is interactive.
Users can hover over the circle representing a subset of rules to view the number of rules in a class. When hovering over a circle, a corresponding legend is displayed on the left-side of the task containing the following information:
Output value
Covering
Error
Conditions
External rules space
The external rules space shows the attributes included in the rules.
The attribute ring is a pie chart in a specific order where each slice depicts an input attribute. A slice normally consists of several sections representing the different values that the attribute to which it belongs can take within the whole ruleset. The chart follows a clockwise order and begins with the attribute at the top of the chart (at 12 o’clock), with the most relevant attributes displayed first, starting at 1 o’clock. The attribute space is highly interactive: by clicking on an attribute name, users can open the slice and read all its individual values.
To view relevant information based on the classes defined in the legend, hover over an attribute name or its corresponding variable type icon. The highlighted rules indicate the attribute used in one of the rule conditions.
Hovering over a particular section of the slice will display information about that set of values for the attribute. The section’s color corresponds to the output class color of the rules it primarily satisfies. The level of transparency represents the relevance of the attribute itself. The highlighted rules are those where the attribute is used in at one of the rules’ conditions.
Example¶
The following example uses the Adult dataset.
After having imported the dataset via an Import from Text file task, randomly split the dataset into two subsets (test and training set; 30% test and 70% training) with a Split Data task.
Add a LLM Classification task and link it to the Split Data task.
Add a Rule Viewer task and link it to the LLM Classification task.
Open the Rule Viewer task. On the left of the stage, users can visualize the Output values and the Total number of rules. By hovering over the external space, users can see the Relevance of the corresponding point of the circle on which they are hovering.
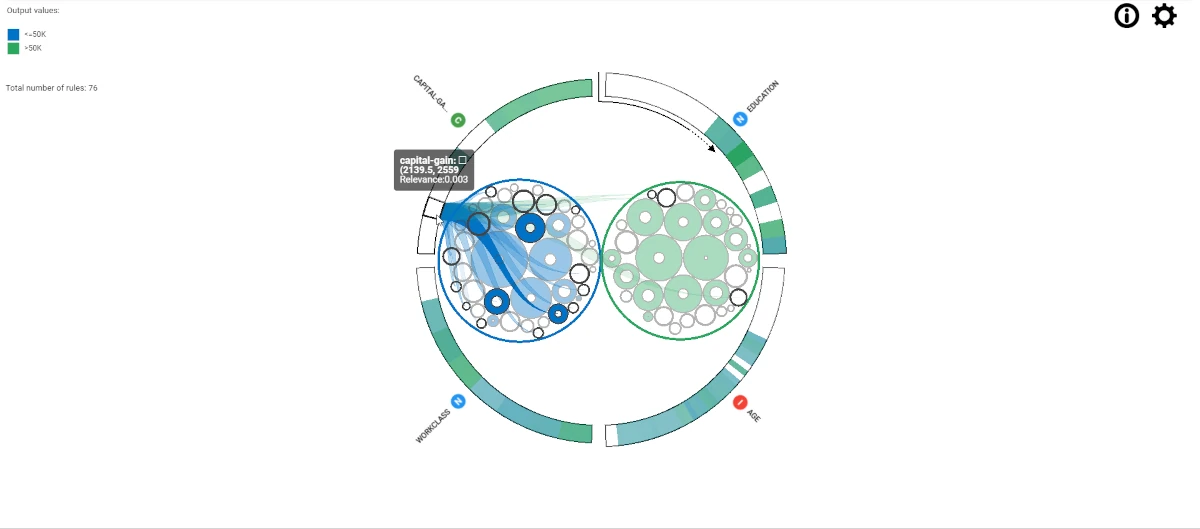
If users hover the mouse over a single rule circle, all the associated values will be highlighted and graphically linked to the circle. The Relevance of the condition can be seen through its transparency.

Hover over an attribute name or its variable type icon to view information about the relevance of the attribute according to the classes defined in the legend. The highlighted rules are those in which the attribute is used in one of the rule’s conditions.