Reshape to Wide¶
The reshape to wide pivoting operation reshapes a dataset by:
transforming a key attribute into a new set of attributes for each row
creating a new column for each distinct value of the transformed key attribute.
Consequently, the number of keys in the dataset will be decreased, which is often a prerequisite for merging datasets.
The Options tab¶
The Options tab is divided into two main areas:
The Available attributes list (for more information see the corresponding page).
The configuration area where you will find all the following configuration options:
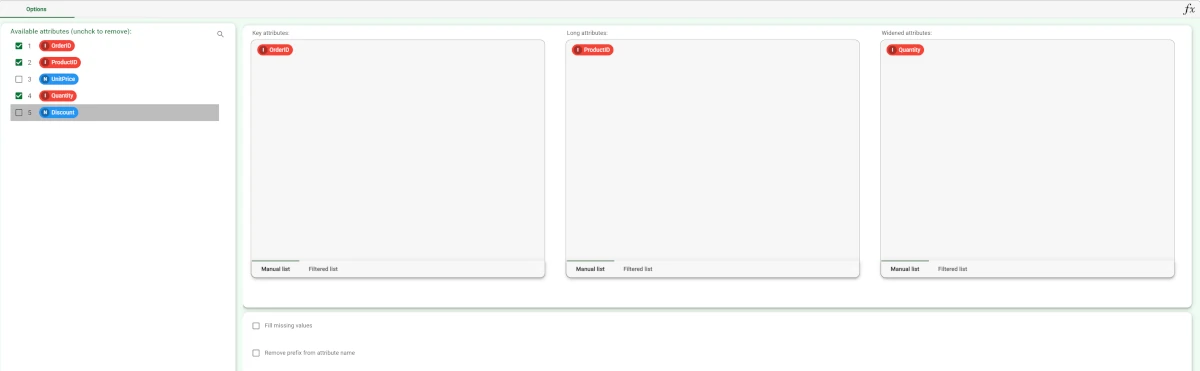
Key attributes: drag and drop the attributes that will be used as a key to identify each group of records. A record/row will be created for each distinct set of values of the key attributes. Instead of manually dragging and dropping attributes, they can be defined via a filtered list.
Long attributes: drag and drop the attributes that will be become column headers in the wide format. Instead of manually dragging and dropping attributes, they can be defined via a filtered list. Note that the combination of Key attributes and Long attributes should be a unique key in the original table. If this is not the case, you have to group according to Key attributes and Long attributes in a Data Manager before applying the Reshape To Wide. They will become the values in the new columns in the dataset.
Widened attributes: drag and drop the attributes that will become column values in the resulting data table. Instead of manually dragging and dropping attributes, they can be defined via a filtered list.
Fill missing values: if selected, zeros will be inserted in every empty cell of the wide columns in the new reshaped table (empty cells in the final table correspond to the combinations of key/long attributes not present in the long dataset).
Remove prefix from widened attribute name: if selected, the prefix “Value” is removed from widened attributes to avoid having the same initial attribute name repeated for every new column in the table. By default, the new columns are named Value(long_value) where long_value is a possible value for the long attribute.
Distribute attributes in sparse way (backward compatibility): if not checked, the distribution of the attributes in the Widened attributes area will be in blocks, so the first block of the newly created attributes will refer to all the first widened attribute’s values, then to all the second widened attribute’s values and so on.
Smart type recognition on widened attributes: if selected, the attribute type of the new columns is recognized automatically.
Example¶
The following example uses the Northwind orders dataset.
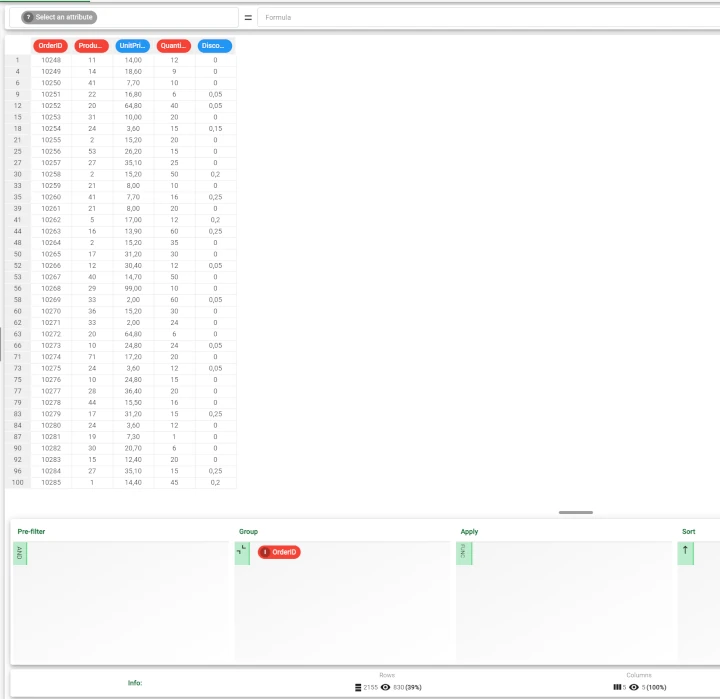
After having imported the file onto the stage, drag a Data Manager task onto the stage to check the imported data. Our goal is to reshape the Order ID attribute to wide and to have all the corresponding values in one row. If we temporarily group the Order ID values, we will notice that we have 830 different IDs. Now, compute the Data Manager task and add a Reshape to Long task onto the stage.
Double-click on the task to open it and set the reshaping parameters. In the example here, we want our dataset to be reshaped in order to have a row with each order and its quantity. Drag the OrderID attribute onto the Key attribute box. Drag the ProductID attribute onto the Long attribute box and finally, drag the Quantity attribute onto the Widened attribute box. Uncheck the Unit Price and Discount attributes, as they are not necessary for our analysis. Save and compute the task.
Drag another Data Manager onto the stage and link it to the Reshape to Wide task. Double-click on the Data Manager to open it and see the results. As we can see, the new datasets will contain 830 records, one for each Order ID.