Array functions¶
Array functions are functions which perform operations on the whole column, and not on the single values in each cell.
The following functions are available:
enum¶
The enum function enumerates the rows in a dataset, in ascending order, optionally grouped by a selected attribute.
Parameters
enum(group)
Parameter |
Description |
|---|---|
group |
If provided, each row will be numbered according to the value of the specified column. More than one column can be specified for grouping, as long as all columns are contained in double brackets, e.g. enum((column1, column2)). If no parameters are specified, a unique number for each row in the dataset, in ascending order, will be provided. |
Example - enum(group)
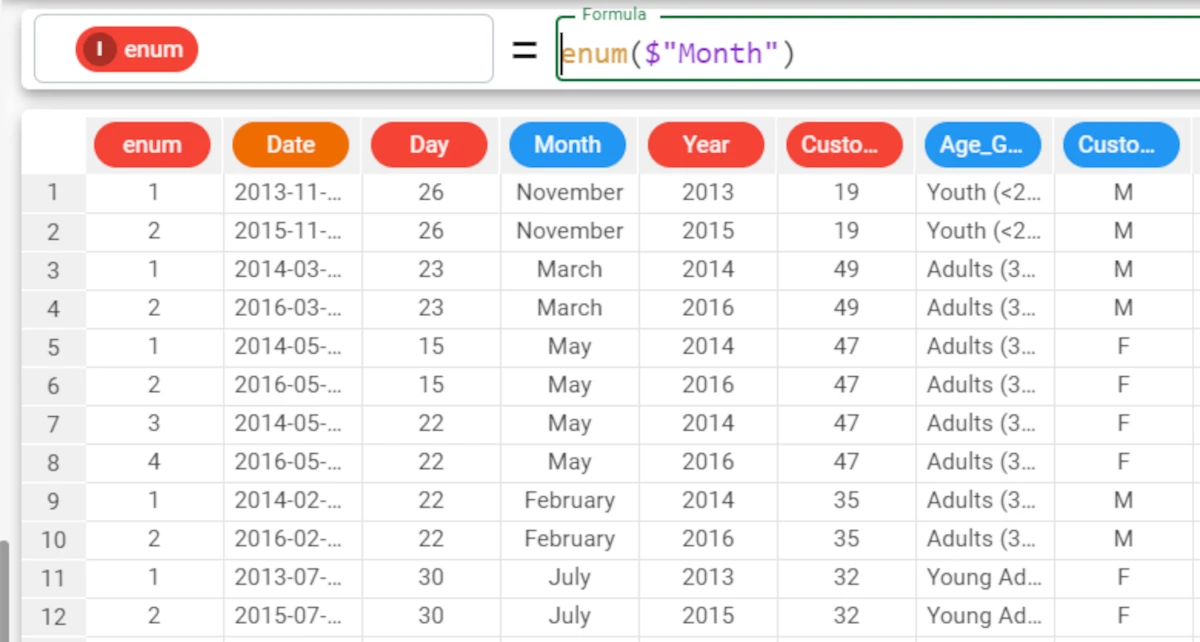
The following example uses the Bike Sales dataset.
In the first example, we will enumerate each row in the dataset, in ascending order, according to the value of the month attribute, by defining the enum attribute with the following formula:
enum($"Month").There is a separate enumeration for each distinct value of the Month attribute. So the enumeration restarts at line 3, as the Month value changes to March, and so on.
Example - enum((column1, column2))
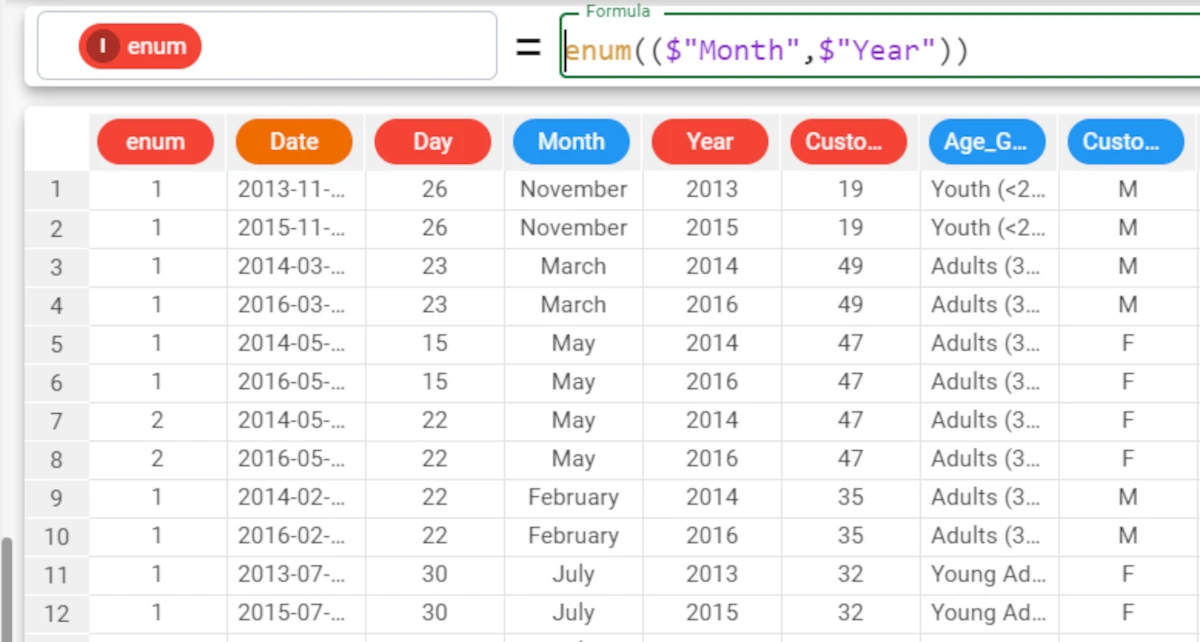
The following example uses the Bike Sales dataset.
In the final example, we want to enumerate each row in the dataset, in ascending order, according to two attributes, Month and Year, by defining the enum attribute with the formula
enum(($"Month",$"Year")).There is a separate enumeration for each distinct value of the Month attribute, AND each distinct value of the Year attribute.
It is important to enclose the attributes in double brackets, to specify that both attributes need to be considered within the column parameter.
fillDown¶
The fillDown function returns a copy of the specified column, filling all the missing values with the last valid value, optionally grouped by selected attributes. If there are rows which remain empty, as they do not have a previous valid value, a fillUp operation can then be performed, using the next valid value.
Parameters
fillDown(column, group, fillall)
Parameter |
Description |
|---|---|
column |
The values of the specified column will be copied, and all missing values will be filled with the last valid value. Column is a mandatory parameter. |
group |
The last valid value can optionally be selected from a specified group. For example, the last valid cost for a specific product. |
fillall |
A Boolean parameter, which, if set to |
Example - fillDown(column)
The following example uses the Bike Sales dataset.
In the first example, we have a series of missing values in the Day attribute in our dataset, which we want to fill.
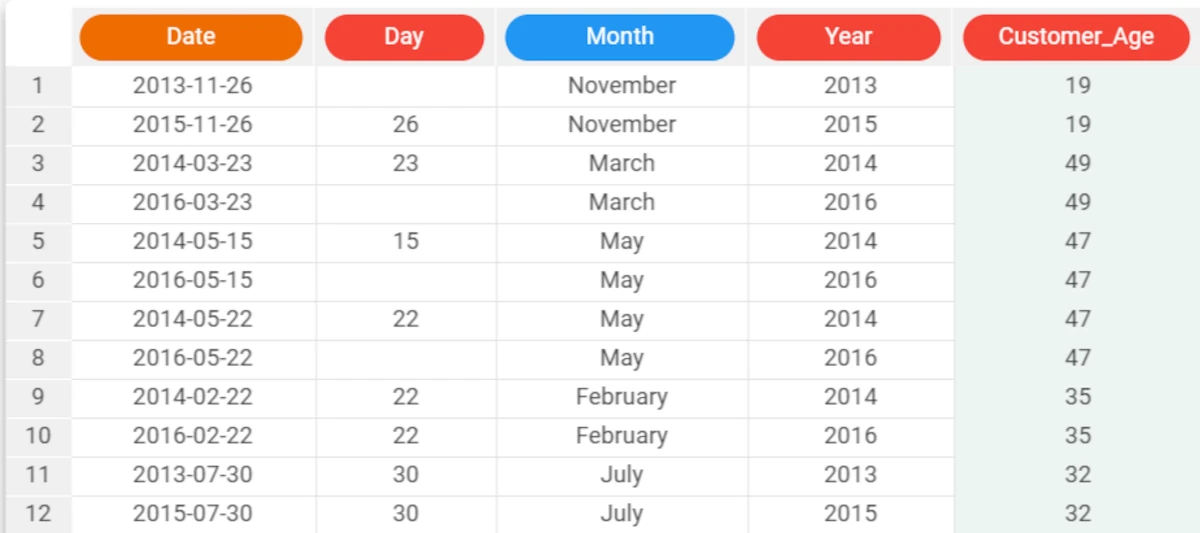
Here we have inserted a simple formula, whereby each missing value is filled with the previous value available in the Day attribute.
The formula to enter this case is:
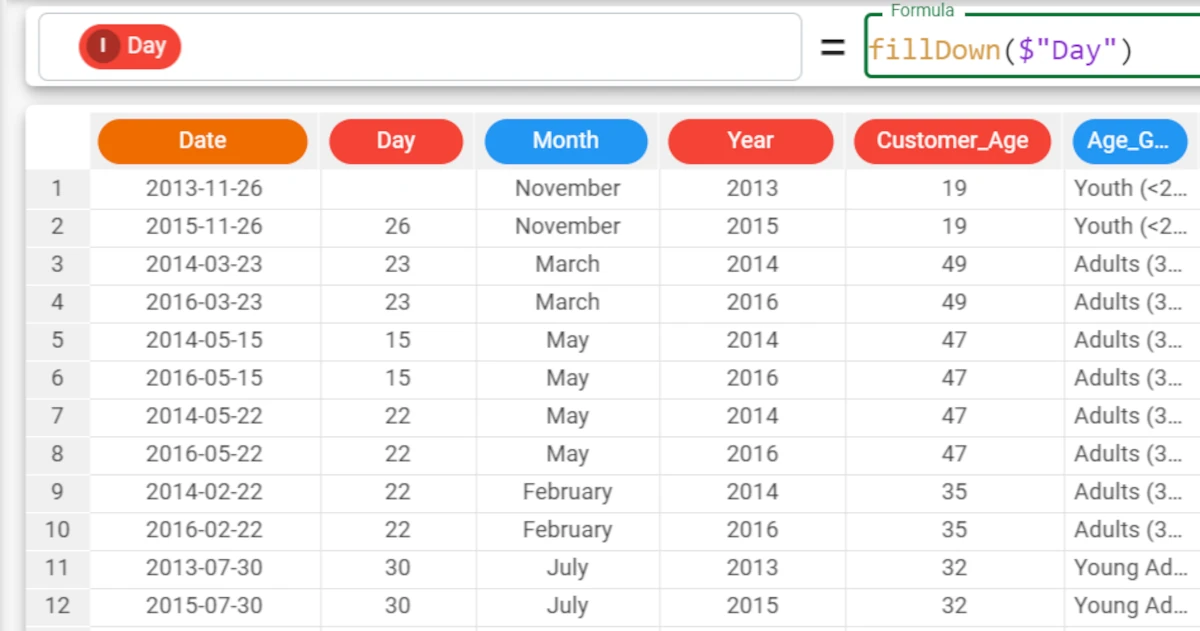
fillDown($"Day"). The first row is empty because there is no previous value to use.This problem can be solved by setting the fillall parameter to
Trueas we will do in a subsequent example.
Example - fillDown(column, group)
The following example uses the Bike Sales dataset.
In this second example, we want to fill missing values considering the Year value, so each value will be inserted with a previous value for the same year.
The formula to enter, in this occurrence, is:
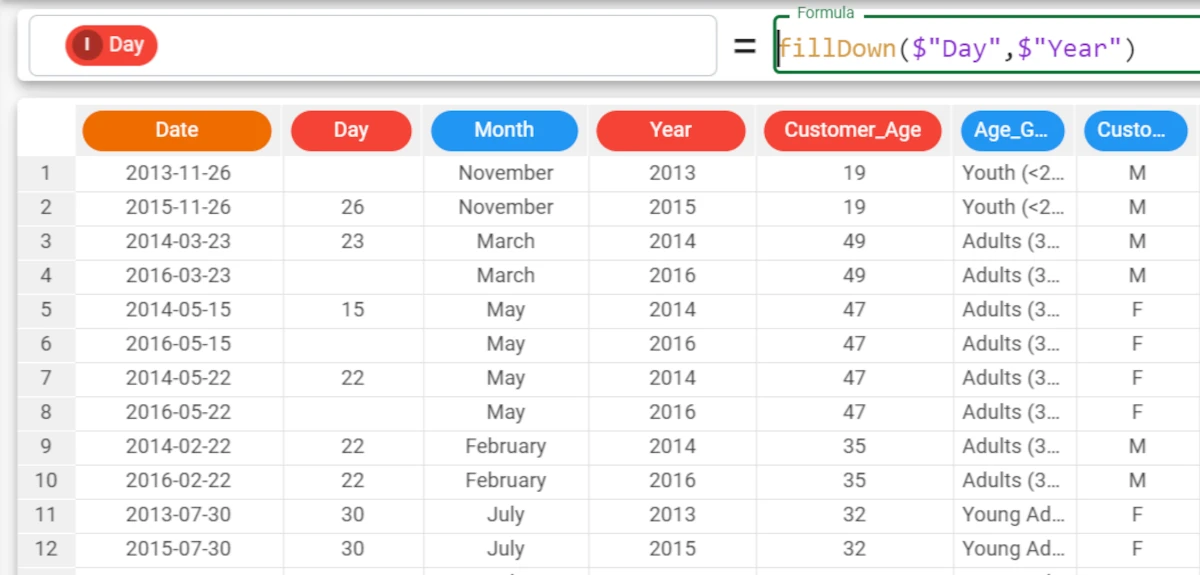
fillDown($"Day", $"Year"). As you can see, there are still numerous missing values, as there aren’t previous values with corresponding years in the dataset. We will solve this problem in the next step, by using the fillall parameter.
Example - fillDown(column, fillall)
The following example uses the Bike Sales dataset.
In this final example, we want to fill missing values considering the Year value, as before, and then fill the missing values with the fillUp function, which will then search for values with the same value for the year attribute from following rows.
The formula to enter this case is:
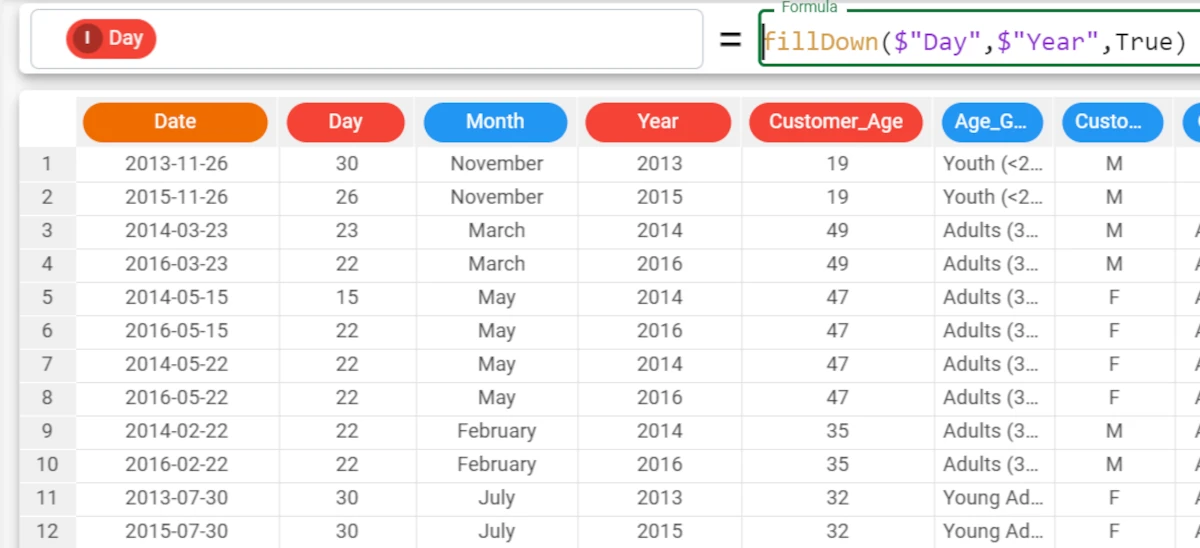
fillDown($"Day", $"Year", True). As you can see, the missing values have now been filled.
fillLinear¶
The fillLinear function fills any missing values for a specified attribute with a value, based on the other values present in the attribute, using a linear interpolation method.
The linear interpolation links two adjacent values with a straight line, graphically: this means that the gap is filled with values with equal distance one to the other.
Parameters
fillLinear(column, group)
Parameter |
Description |
|---|---|
column |
The attribute whose missing values will be filled with an average value. The column parameter is mandatory. |
group |
The attribute used to group results. |
Example - fillLinear(column)
The following example uses the Bike Sales dataset.
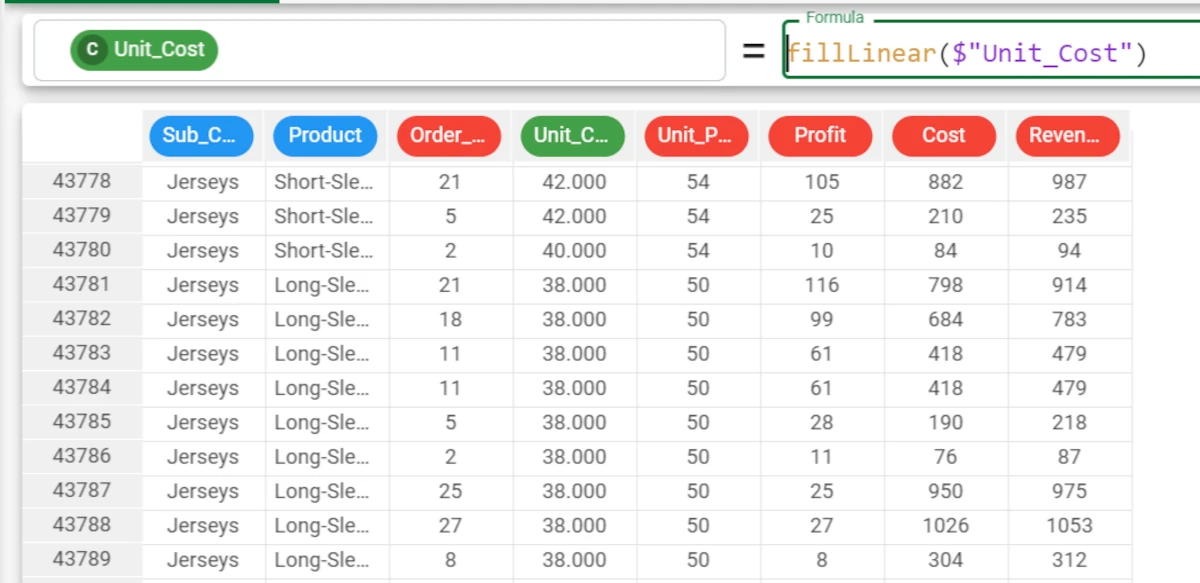
In the first example, we have a series of missing values in the Unit_Cost attribute in our dataset, which we want to fill.
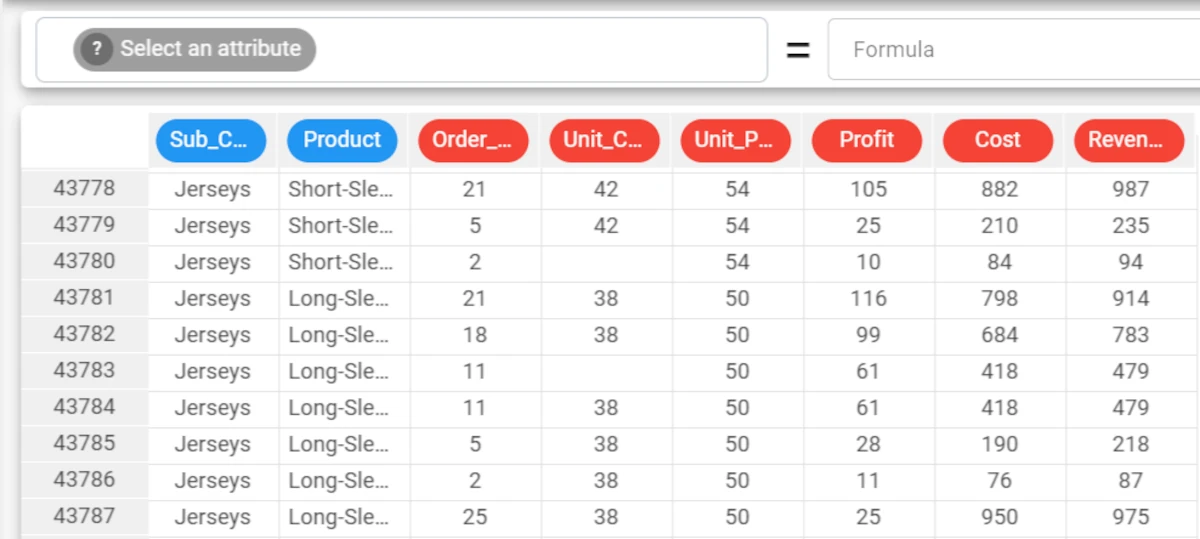
Here we have inserted a formula, whereby each missing value in the Unit_Cost attribute is filled with an appropriate value, based on the linear interpolation of the other values present in the Unit_Cost attribute. The formula to enter this case is:
fillLinear($"Unit_Cost"). The results are displayed as continuous values. The first missing value has been filled with the value 40, while the second missing value has been filled with the value 38.
The following example uses the Bike Sales dataset.
Example - fillLinear(column, group)
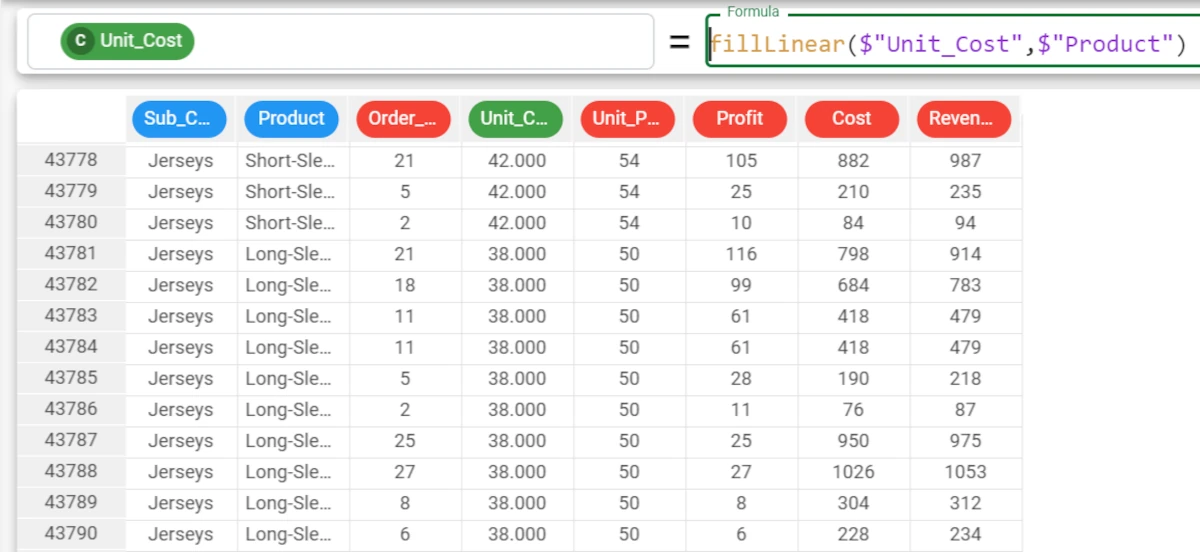
In the second example, we will again configure the Unit_Cost attribute to fill its missing values, but this time the new values will be calculated based also on the corresponding Product attribute, as specified as the group parameter, with the formula
fillLinear($"Unit_Cost", $"Product"). The two values entered are 42 and 38, which are actually more precise (the costs should have been exactly 42 and 38).
fillUp¶
The fillUp function returns a copy of the specified column, filling all the missing values with the next valid value.
Parameters
fillUp(column, group, fillall)
Parameter |
Description |
|---|---|
column |
The values of the specified column will be copied, and all missing values will be filled with the next valid value. Column is a mandatory parameter. |
group |
The next valid value can optionally be selected from a specified group. For example, the next valid cost for a specific product. |
fillall |
A Boolean parameter, which, if set to |
Example - fillUp(column)
The following example uses the Bike Sales dataset.
In the first example, we have a series of missing values in the Day attribute in our dataset, which we want to fill.
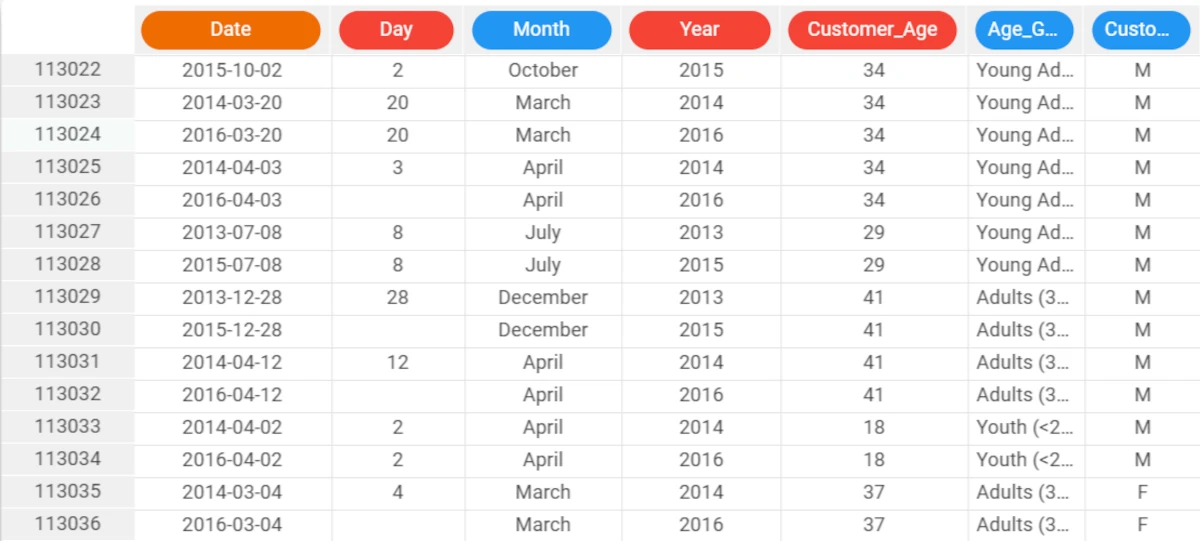
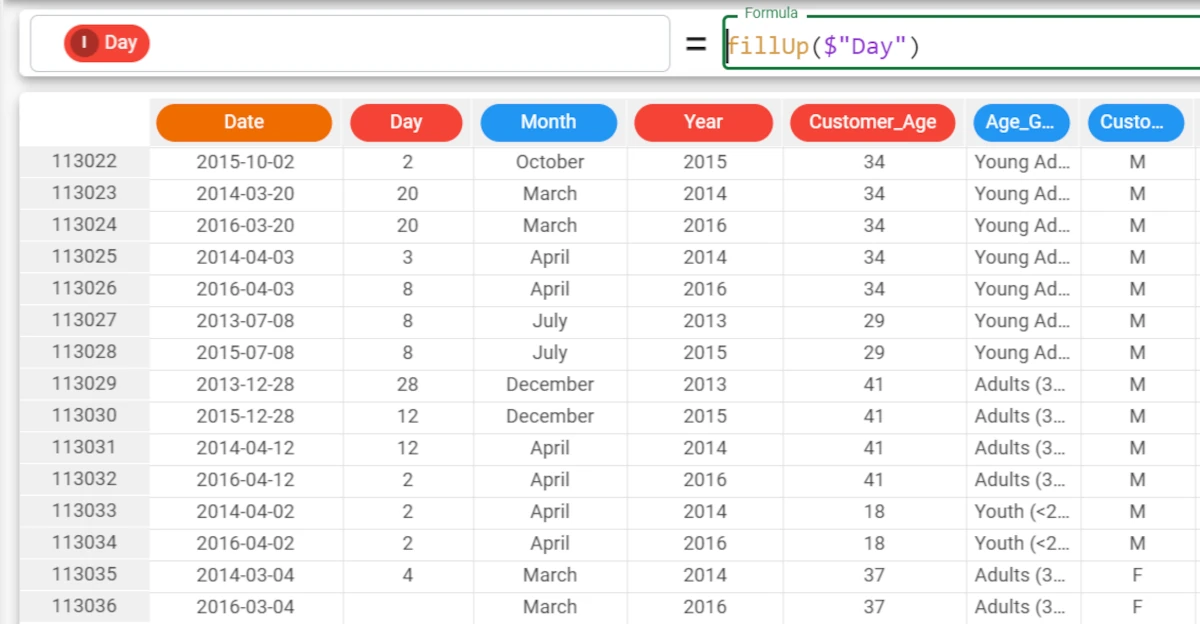
Here we have inserted a simple formula, whereby each missing value is filled with the previous value available in the Day attribute. The formula to enter this case is:
fillUp($"Day"). The last row is empty because there is no successive value to use. This problem can be solved by setting the fillall parameter toTrueas we will do in a subsequent example.
Example - fillUp(column, group)
The following example uses the Bike Sales dataset.
In this second example, we want to fill missing values considering the Year value, as before, so each value will be inserted with a successive value for the same year. The formula to enter this case is:
fillUp($"Day", $"Year"). As you can see, there are numerous missing values still, as there aren’t successive values with corresponding years in the dataset. We will solve this problem in the next step, by using the fillall parameter.
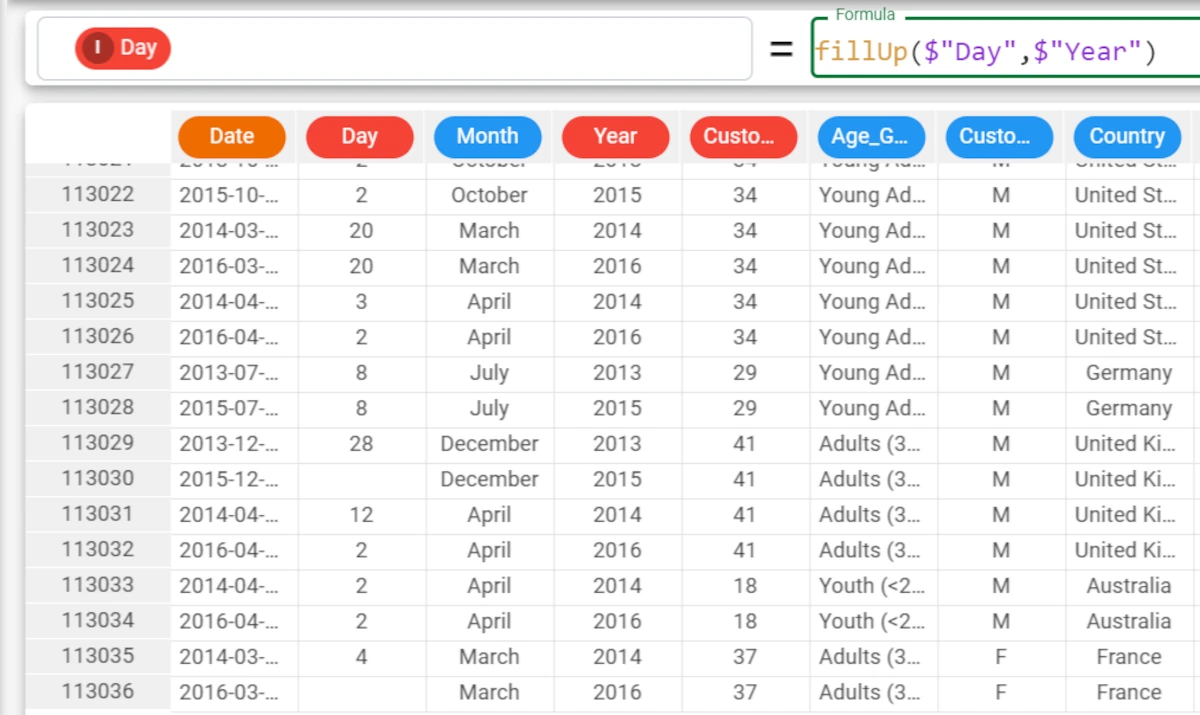
Example - fillUp(column, fillall)
The following example uses the Bike Sales dataset.
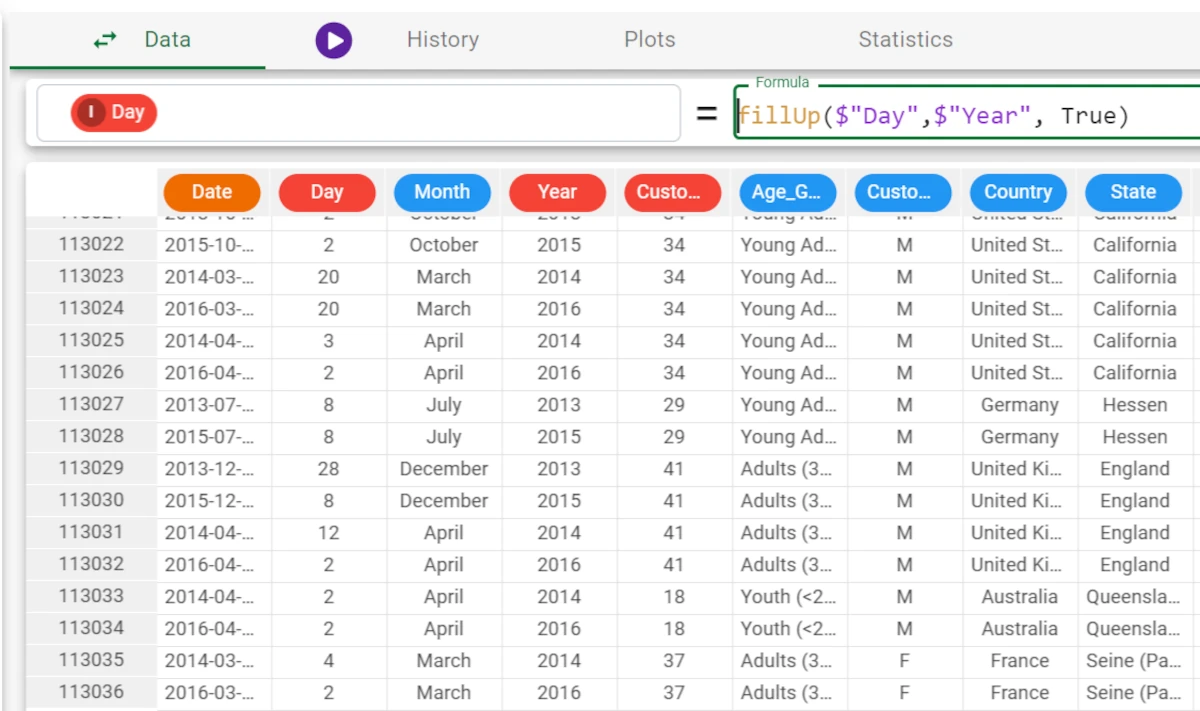
In this final example, we want to fill missing values considering the Year value, as before, and then fill the missing values with the fillDown function, which will then search for values with the same value for the year attribute from previous rows. The formula to enter this case is:
fillUp($"Day", $"Year", True). As you can see, the missing values have now been filled.
integer¶
The integer function returns the values of the specified attribute cast to the integer data type.
Parameters
integer(column)
Parameter |
Description |
|---|---|
column |
The attribute whose values will be cast to the integer data type. The column parameter is mandatory. |
Example - integer(column)
The following example uses the Sales 2017 dataset.
In this example, the Sales attribute is expressed as a continuous value, with two decimal places.
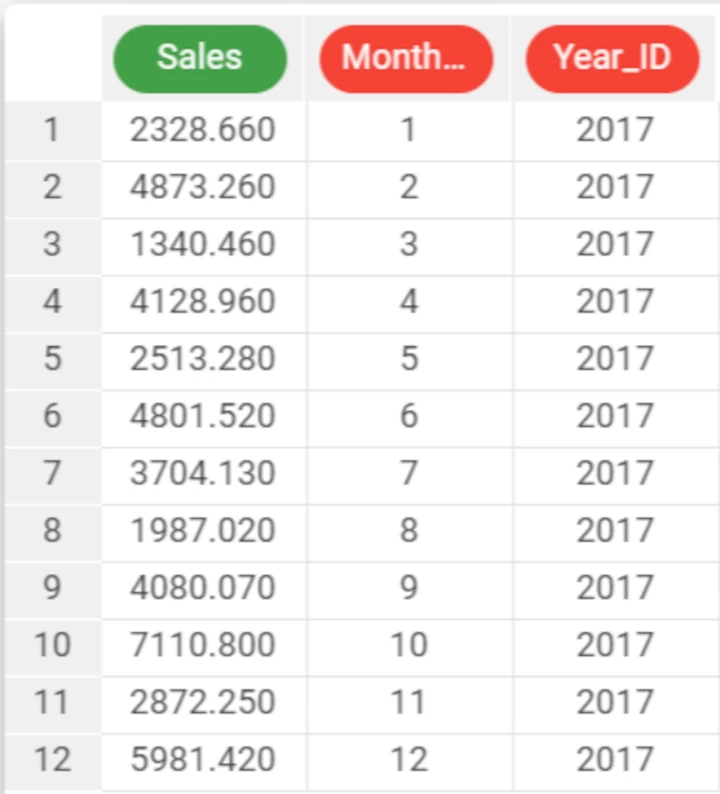
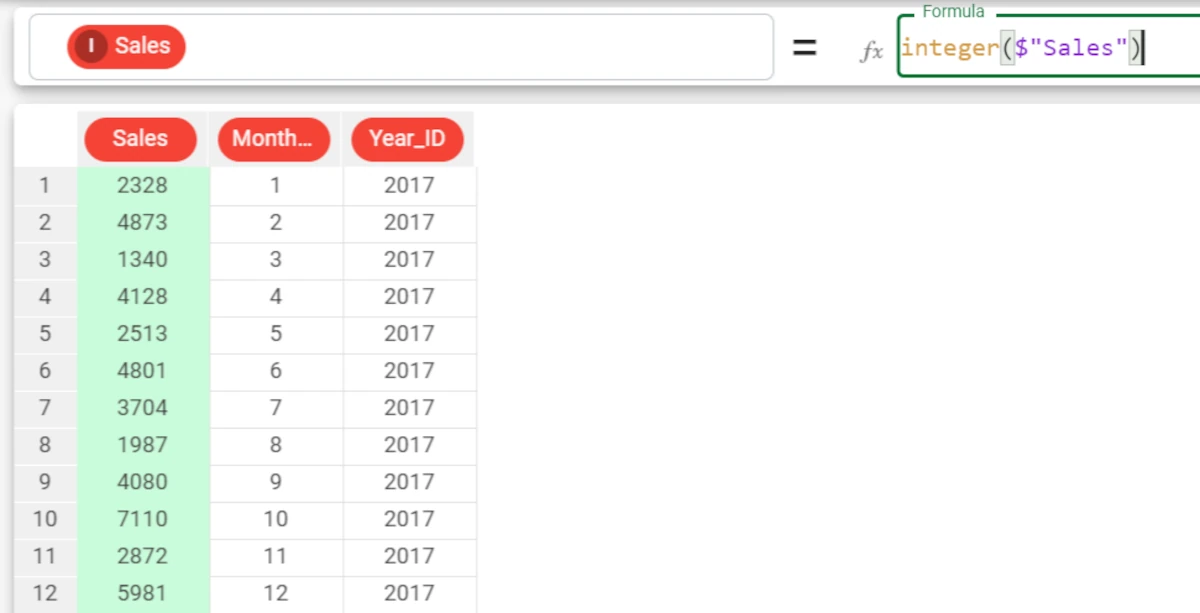
We have used the integer function to round off this continuous value to an integer, using the formula
integer($"Sales").
len¶
The len function returns the number of values present in the attribute, including missing values.
Parameters
len(column)
Parameter |
Description |
|---|---|
column |
The attribute whose number of values you want to return. The column parameter is mandatory. |
Example - len(column)
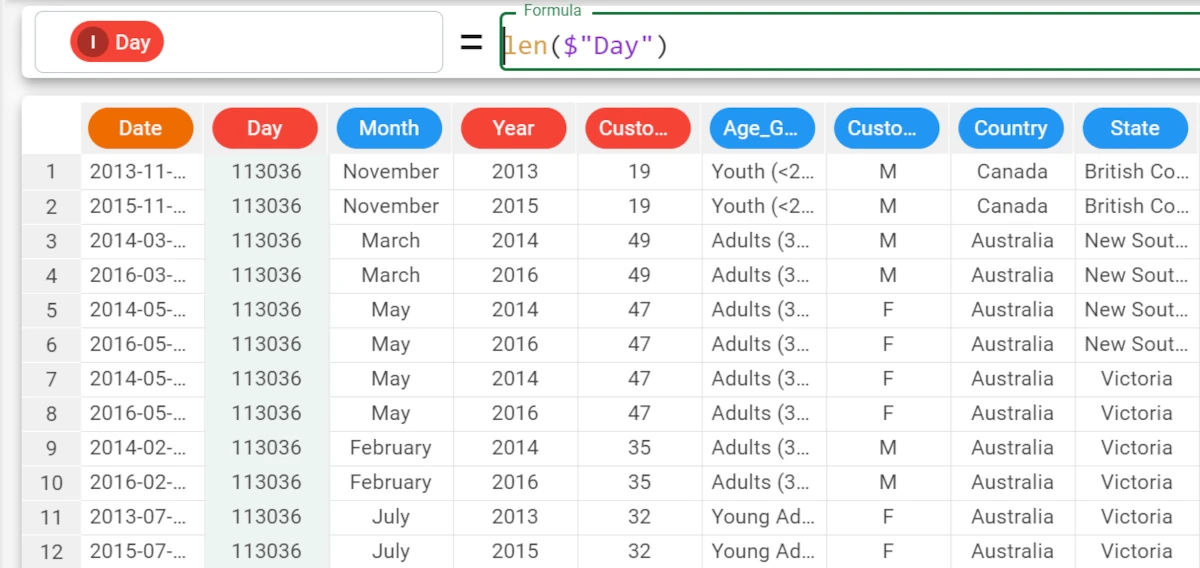
The following example uses the Bike Sales dataset.
In this example, we have configured the Day attribute to retrieve the number of values it contains, with the formula
len($"Day").
matchHeaders¶
The matchHeaders function returns the value in the corresponding row for the selected column.
Parameters
matchHeaders(column)
Parameter |
Description |
|---|---|
column |
Returns the value of the corresponding row of the specified column. Column is a mandatory parameter. |
Example - matchHeaders(column)
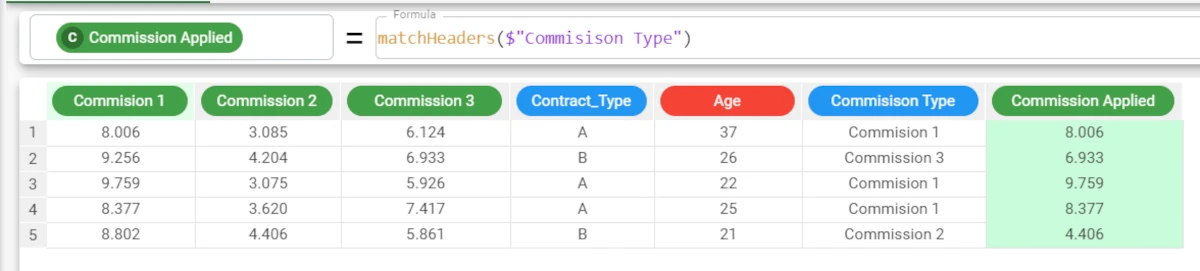
The following example uses the Commissions dataset.
In this simple example, there are three possible commission rates for our sales force, according to the contract selected by the client and their age group. The commission type to be applied is automatically applied in the Commission Type column with the formula:
ifelse($"Contract_Type"=="A","Commision 1",ifelse($"Age"<25,"Commission 2","Commission 3"))

We can now use the matchHeaders function to apply the correct commission percentage, according to the selected type. To do this we simply create a new column called Commission Applied, and enter the formula
matchheaders($"Commision Type). The formula has retrieved the corresponding commission rate from the correct column, according to the type identified in the Commission Type attribute. The advantage of working in this way is that if commission rates change, or vary according to the day or sales person, or the conditions change, it’s really quick to retrieve the new values for each sale.
nominal¶
The nominal function returns the values of the specified attribute cast to the nominal data type.
Parameters
nominal(column)
Parameter |
Description |
|---|---|
column |
The attribute whose values will be cast to the nominal data type. The column parameter is mandatory. |
Example - nominal(column)
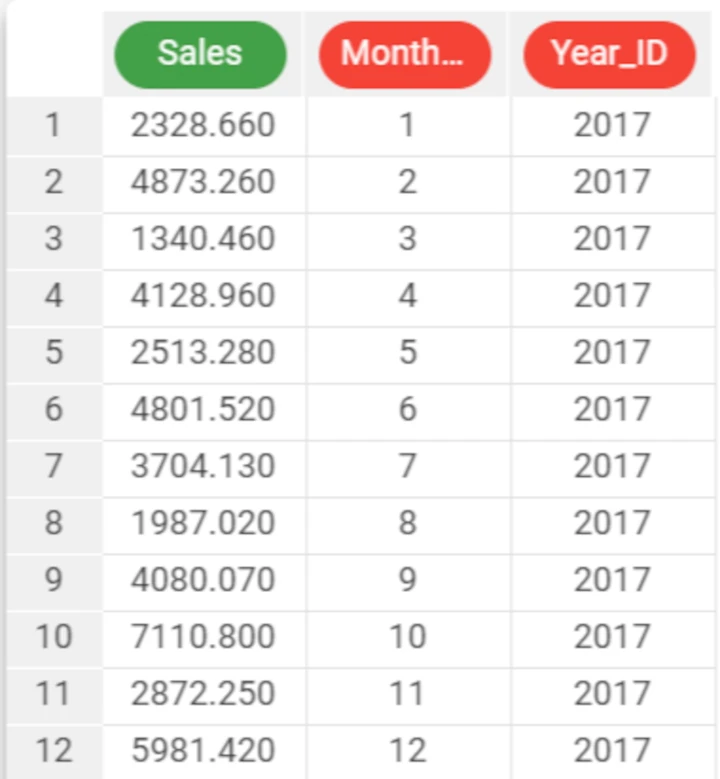
The following example uses the Sales 2017 dataset.
In this example, the Month_ID attribute is expressed as an integer value.
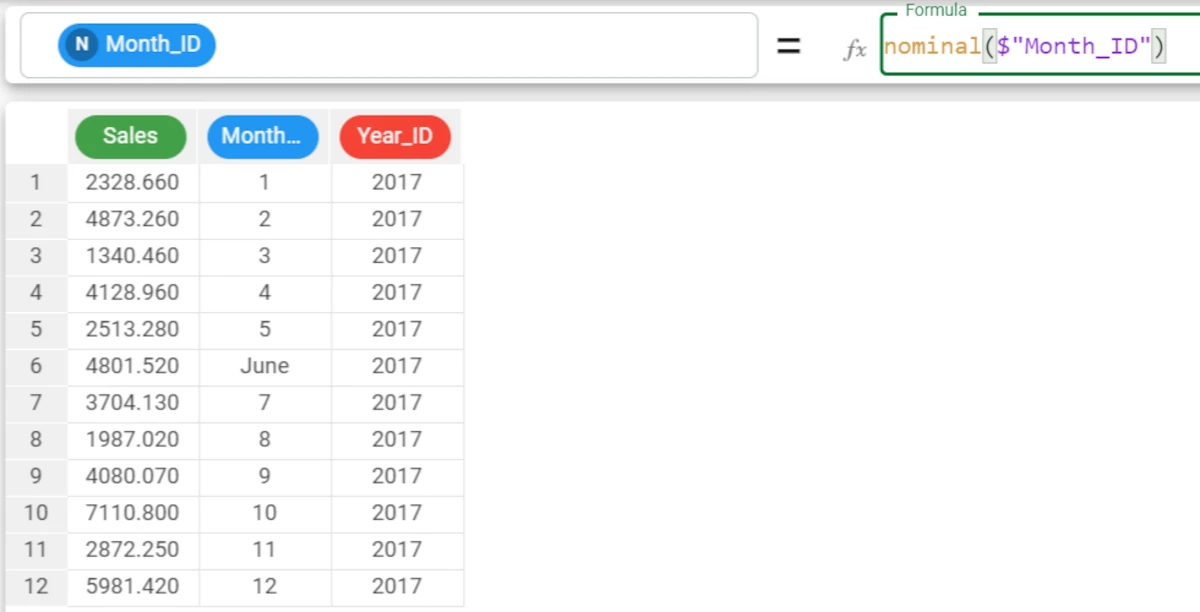
We can use the nominal function to convert the data type to nominal, so it will also accept months written as days (e.g. June) and not just as an integer. The required formula is
nominal($"Month_ID").
perm¶
The perm function returns the values of a specified attribute in a random order.
Parameters
perm(column)
Parameter |
Description |
|---|---|
column |
The attribute whose values will be returned randomly. The column parameter is mandatory. |
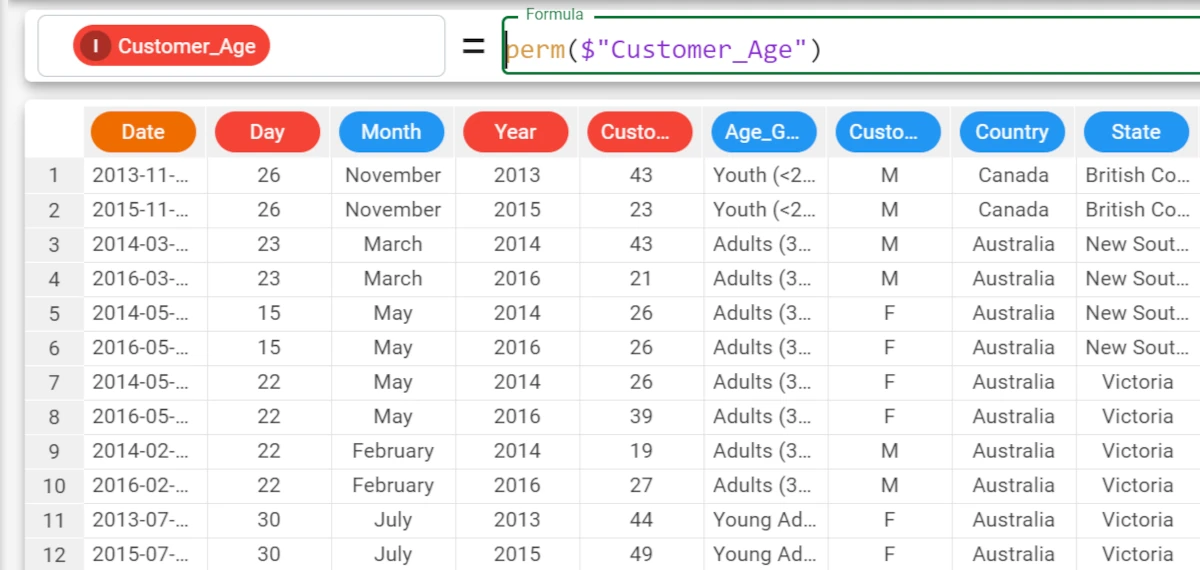
Example - perm(column)
The following example uses the Bike Sales dataset.
In this example, we have configured the Customer_Age attribute to return its values in a random order, with the formula
perm($"Customer_Age").
rank¶
The rank function returns the values of a column in ascending alphabetic order. By default, missing values are considered in the ranking.
Parameters
rank(column, usemissing)
Parameter |
Description |
|---|---|
column |
The values of the specified column will be placed in ascending order. Column is a mandatory parameter. |
usemissing |
To not consider missing values, this parameter can be set to False. By default, its value is True. |
Example - rank(column, usemissing)
The following example uses the Bike Sales dataset.
In the first example, we have a series of missing values in the Day attribute in our dataset, which we want to fill.
If we enter the formula
rank($"Sales")the rank of each Sales value, in alphabetic order will be displayed, with missing values placed at the top of the list.
If, however, we do not want to consider missing values in the ranking, the second parameter, usemissing, must be set to false with the formula
rank($"Sales", False).
shift¶
The shift function shifts values by a specified value.
Parameters
shift(column, shift, group, cyclic)
Parameter |
Description |
column |
Returns the value of the corresponding row of the specified column. Column is a mandatory parameter. |
shift |
The number of rows by which the value must be shifted downwards. Shift is a mandatory parameter. |
group |
The results can be grouped according to a specified attribute. |
cyclic |
If True, any missing initial rows will be filled with values taken from the end of the dataset in a cyclical manner. By default, this value is set to False. |
Example - shift(column, shift, group)
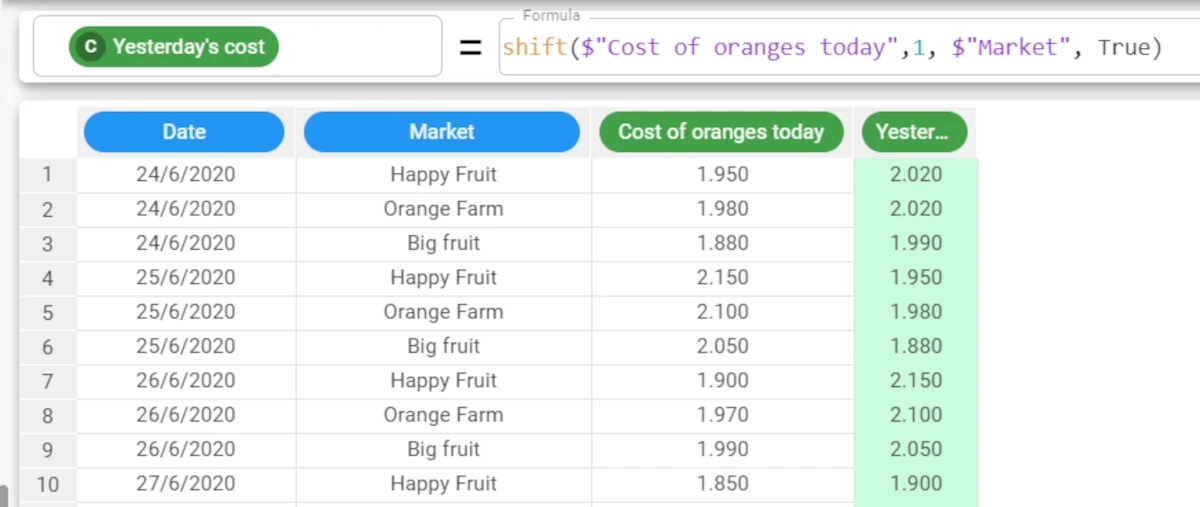
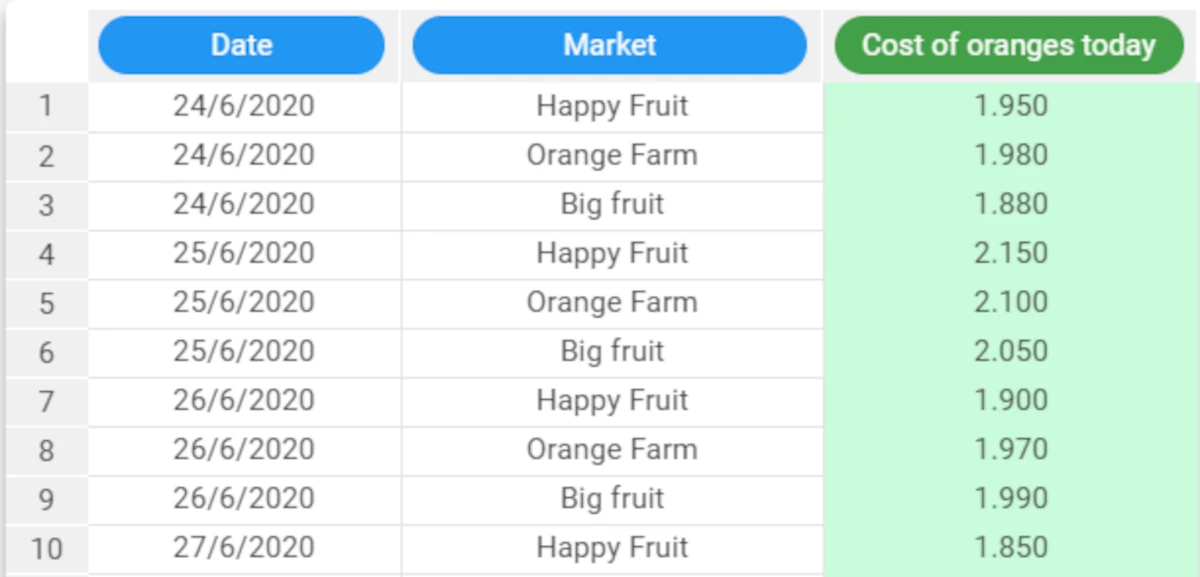
The following example uses the Oranges dataset.
Our dataset contains the prices of oranges on a daily basis in 3 different farmers markets.
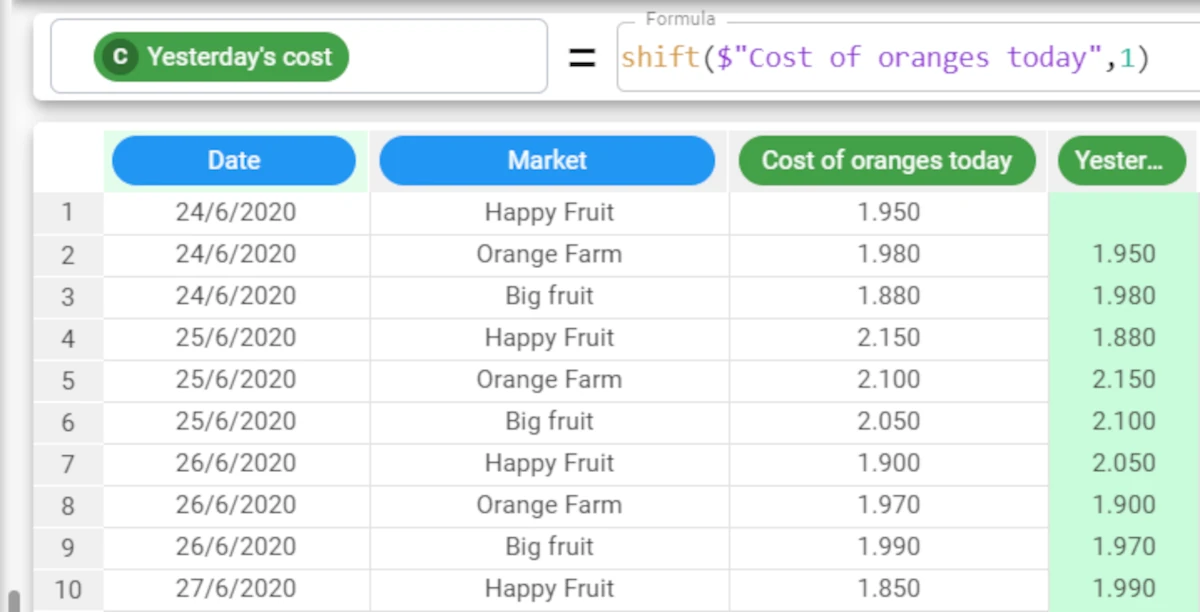
If we create a new attribute called Yesterday’s cost, and enter the formula
shift($"Cost of oranges today", 1)the cost of oranges from the previous row will be displayed.
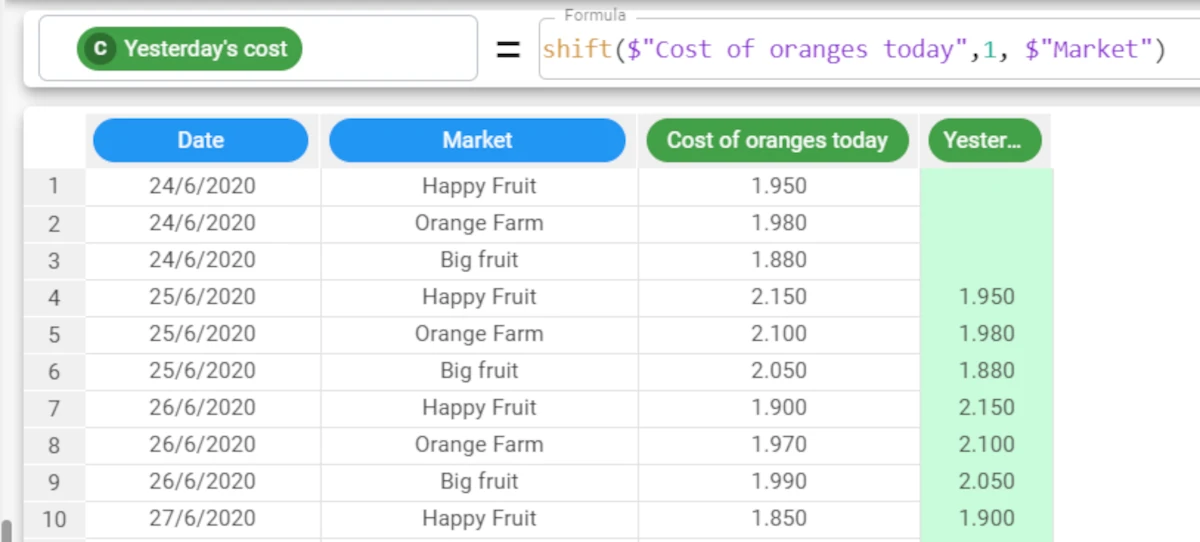
However, the results contain the values from the previous row, but not from the previous day, as there is an entry for every day for each farmer’s market, so if we need to take the results from the previous row for the same market, using the group parameter. So we’ll instead enter the formula
shift($"Cost of oranges today", 1, $"Market").
Example - shift(column, shift, group, cyclic)
The following example uses the Oranges dataset.
You’ll have noticed that there are missing values for the first rows in the dataset, as there are no previous rows to retrieve values from. If it makes sense logically, you can use retrieve values from the final rows of the dataset in a cyclical manner, so there are no missing values. To do this, you must set the Cyclic parameter to
True- by default it is False, so if not specified, the function will not automatically fill empty initial rows. The corresponding formula will be:shift($"Cost of oranges today", 1, $"Market), True)