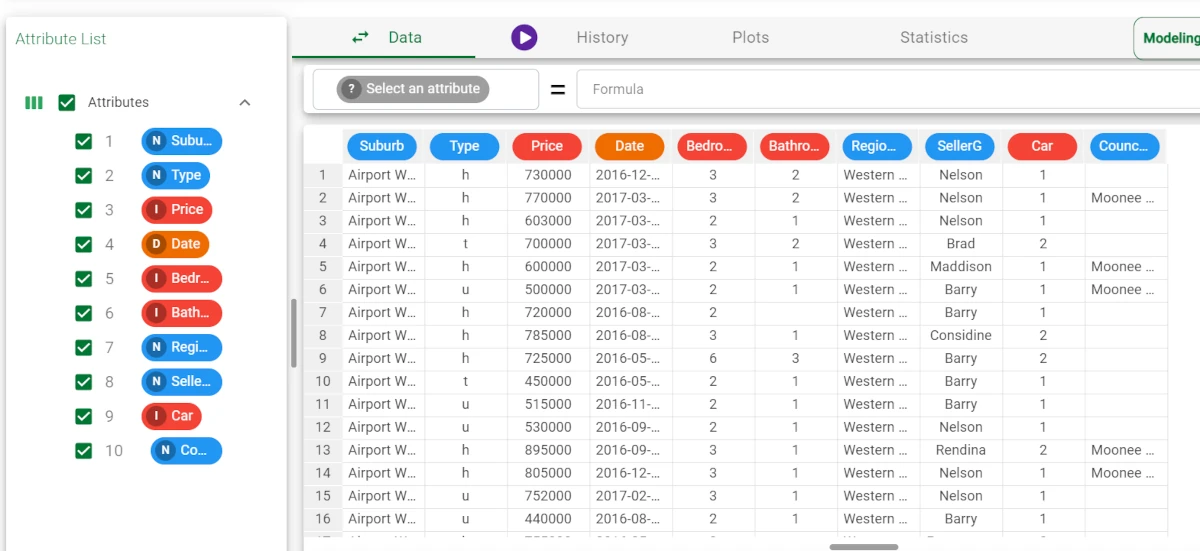
Fill Clean¶
The Fill/Clean task improves the quality of datasets by managing missing data in the Fill tab, and automatically removing unnecessary attributes in the Clean tab.
The task allows you to perform operations quickly on a data table, for example by dragging and dropping or filtering attributes to delete. This is particularly helpful when working with large amounts of data. These operations can also be performed in the Data Manager task, attribute by attribute, but it is more time-consuming.
Typical operations performed in this task are:
filling in missing values using:
fixed values,
min/max values, or
averages.
ignoring attributes:
which have too many missing values
where the mode ratio is too high (i.e. where a high percentage of values are identical)
which have too many different values, for example a different id for every row.
The Fill/Clean task is made of the Options tab only, which is divided into two main areas:
The Available attributes area, where you can uncheck the attributes you want to remove from the analysis (for more information see the corresponding page). Right-clicking this panel gives access to some additional options, such as checking/unchecking all attributes, inverting your selection, hiding ignored attributes, etc.
The configuration area, which is further divided into two tabs, the Fill tab and the Clean tab, which will be analyzed in the sections below.
The Fill tab¶
The Fill tab contains all the configuration options for the fill operations:
Attributes subject to filling operations: drag the attributes that can be modified by the selected filling operations. Attributes can also be defined via a filtered list.
Attributes to define calculation groups: drag here the attributes that define subgroups which will be used to calculate missing values. Attributes can also be defined via a filtered list.
Impute missing values for NOMINAL attributes with: if selected, you can define how missing nominal attributes will be filled, either by specifying a fixed value (nomimputetype = 0), and manually entering it (nomvalue), or by selecting how the value can be calculated, by calculating the mode of each attribute (nomimputetype = 1) according to the specified calculation groups.
Impute missing values for ORDERED attributes with: if selected, you can define how missing ordered attributes will be filled, either by specifying a fixed value (ordimptype = 0), and manually entering it (ordvalue), or by selecting how the value can be calculated, by selecting one of the available calculation types (nomimputetype) according to the specified calculation groups.
Possible methods are mean (1), median (2), mode (3), maximum (4) or minimum (5).Impute missing values for TEMPORAL attributes with: if selected, you can define how missing temporal attributes will be filled, either by specifying a fixed value (timeimptype = 0), and manually entering it (timevalue), or by selecting how the value can be calculated, by selecting one of the available calculation types (timeimputetype) according to the specified calculation groups.
Possible methods are mean (1), median (2), mode (3), maximum (4) or minimum (5).Consider the whole row to compute MODE: if selected, all attributes, and not just those added to the Key attributes list, will be used to calculate the mode for missing attributes. This applies only to missing value calculations that use the mode method, as selected above in the Impute missing attributes options.
Smart type recognition on attributes: if selected, the attribute type will be detected automatically, overwriting the types on the ones set in the previous tasks.
The Clean tab¶
The Clean tab contains all the configuration options for the clean operations:
Attributes subject to cleaning operations: drag the attributes that can be modified by the selected cleaning operations. Attributes can also be defined via a filtered list.
Attributes to be deleted: drag the attributes that can be modified by the selected cleaning operations. Attributes can also be defined via a filtered list.
Remove attributes with missing ratio above (%): if selected, removes attributes whose percentage of missing values exceeds the percentage specified for this option.
If you want to ignore, but not delete these attributes, select the Ignore attributes instead of deleting them option (selected by default).Remove attributes with number of mode values above (%): if selected, attributes where the mode ratio exceeds the specified value are removed. This may be useful, for example, where there is a high percentage of values are identical.
If you want to ignore, but not delete these attributes, select the Ignore attributes instead of deleting them option (selected by default).Remove nominal attributes with number of values above (%): if selected, attributes who have a higher number of values than the specified limit are removed.
This limit removes attributes which have, for example, a different id for every row.
If you want to ignore, but not delete these attributes, select the Ignore attributes instead of deleting them option.Standardize ordered attributes: if selected, ordered attributes will be normalized using the formula (x-mean)/stdev.
Ignore attributes instead of removing them: if selected, attributes you chose to remove in the following options are ignored, and consequently not used to create the model, but will remain in the dataset (greyed out): Remove attributes with missing ratio above, Remove attributes with number of mode values above, Remove nominal attributes with number of values above.
Example¶
After having imported the file and having checked through a Data Manager if it has been correctly imported and checked the missing values and outliers, drag a Fill/Clean task onto the stage and link it to the Data Manager.
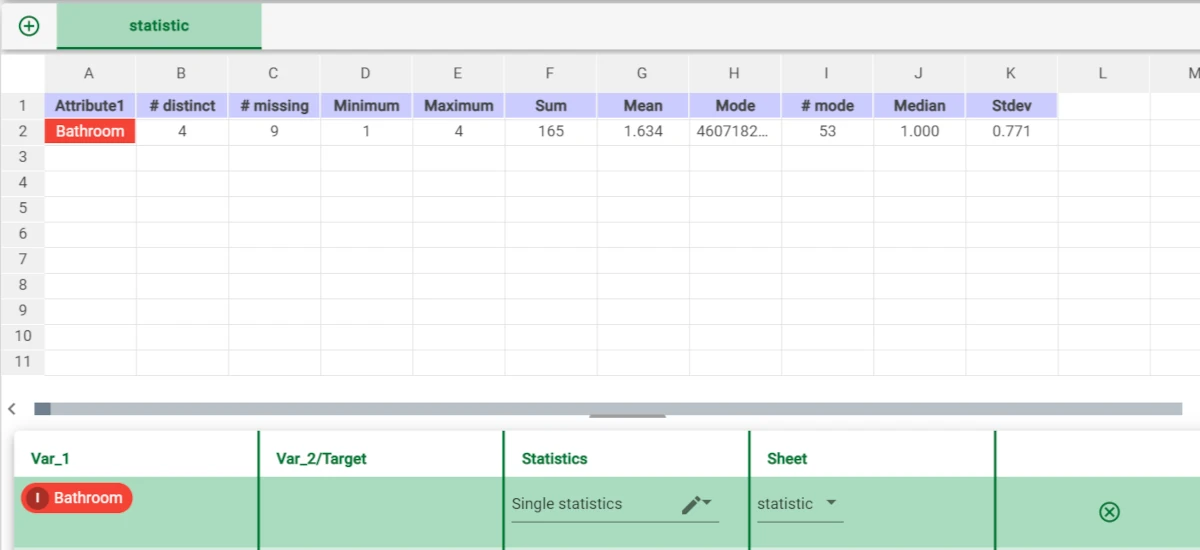
As we can see through the Statistics tab, the Bathroom attribute has 9 missing values.
Double-click the task to open it and apply the changes you deem necessary.
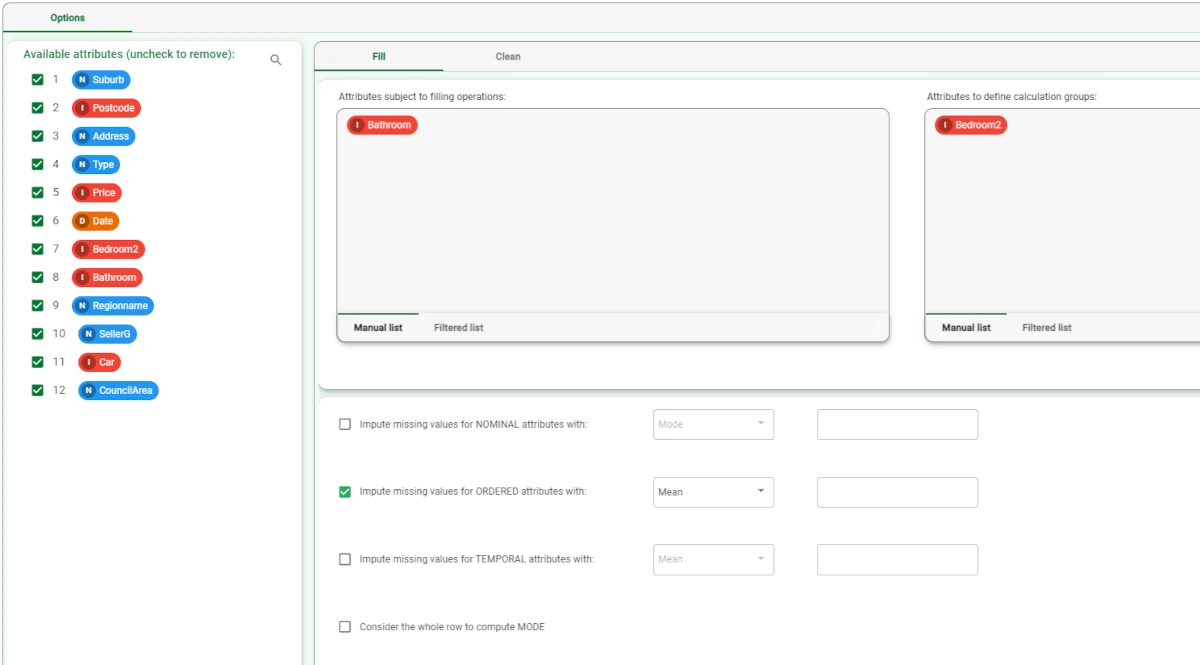
In the example here, we wanted to set the missing values for the Bathroom attribute, basing the values on the Bedroom2 attribute.
In the Fill tab, drag the Bathroom attribute onto the Attributes subject to filling operations area and the Bedroom 2 attribute onto the Attributes to define calculation groups area and check the Impute missing values for ORDERED attributes with: then, choose MEAN.
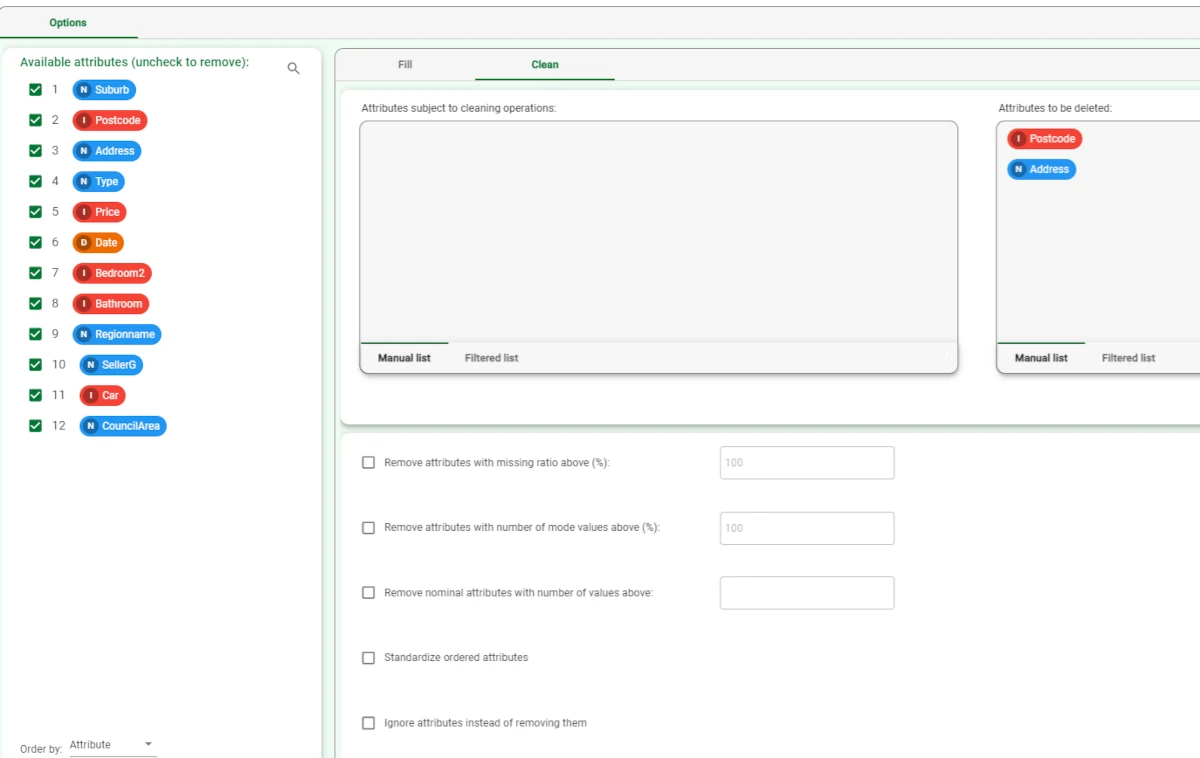
Then, we want to delete unnecessary information, like the Postcode and the Address attribute.
Open the Clean tab and drag the attributes listed above onto the Attributes to be deleted area.
Save and compute the task.
Drag another Data Manager and link it to the Fill/Clean task to see the results.
As you can see, the Postcode and Address attributes are not present anymore.
In the Statistic Manager, if you drag the Bathroom attribute, there are no missing values.