Text functions¶
Text functions perform operations on text, such as extracting part of it, removing the start/end of a word.
The following functions are available:
Warning
All the functions reported in this page, work only on nominal attribute. If an attribute with type different from nominal is provided, it will be automatically cast to nominal before executing the desired operation. Therefore if you are using one of these functions directly on continuous attributes, it will be cast to nominal retaining a fixed precision, controlled by the Flow Execution Parameters.
charReplace¶
The charReplace function replaces fonts with new ones.
Parameters
charReplace(column, oldchar, newchar, unchanged, charforothers, considersequence)
Parameter |
Description |
|---|---|
column |
The nominal attribute from which you extract the substring. The column parameter is mandatory. |
oldchar |
The string or list of strings (it can be even a word, but every letter of it will be considered as a separate font) which contain all the fonts that have to be replaced with the newchar value. The oldchar parameter is mandatory.The oldchar parameter is case-sensitive. |
newchar |
The string or list of strings which replace all the fonts in oldchar. The newchar parameter is mandatory. The newchar parameter is case-sensitive. |
unchanged |
The string which contains all the fonts that must not be replaced. By default, all the fonts which are not included in oldchar are included in this list. |
charforothers |
The string which replaces all the other fonts. The default value is “X”. |
considersequence |
It is set as |
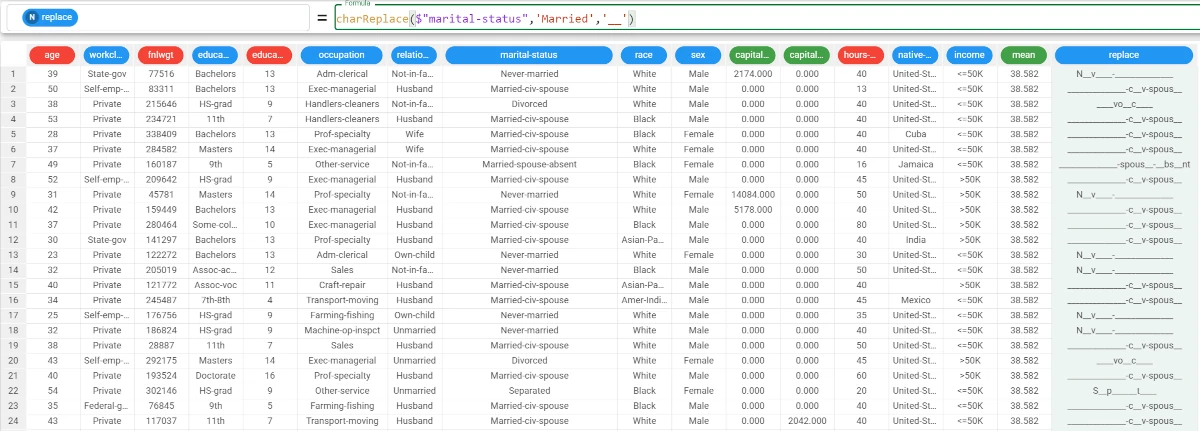
Example - charReplace(column, oldchar, newchar)
The following example uses the Adult dataset.
In this example, we want to replace the ‘married’ string (that are the ‘m’, ‘a’, ‘r’, ‘r’, ‘i’, ‘e’, ‘d’ fonts) with a ‘_’: add a new attribute, called replace, and type the following formula:
charReplace($"marital-status",'married','_')and the ‘m’, ‘a’, ‘r’, ‘r’, ‘i’, ‘e’, ‘d’ strings will be replaced by a ‘_’.As you can see, all these letters are missing in the new values.
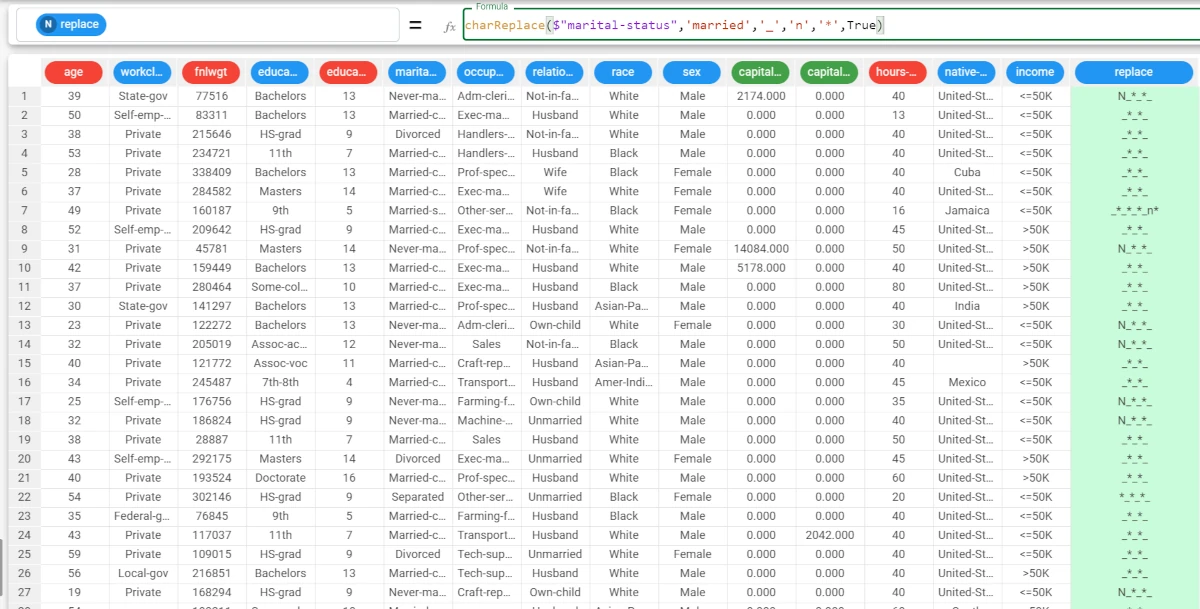
Example - charReplace(column, oldchar, newchar, unchanged, charforothers, considersequence)
The following example uses the Adult dataset.
If we want to add more complexity to the function, and we want to edit all the string and also define which fonts must not be changed, we need to specify the optional parameters.
In this example, we want to keep the ‘N’ unchanged, and replace all the other fonts which have not been specified in the oldchar parameter with an ‘*’, which will be the charforothers parameter.
Specify
Trueas the considersequence parameter, so that there will be only one occurrence of that font.The function will become:
charReplace($"marital-status",'married','_','n','*',True)
distance¶
The distance function computes the distance between the values of two columns, column1, column2, according to one of the following methods:
levenshtein (
l)damerau-levenshtein (
dl)lcs (
lcs)hamming (
hamming)
Parameters
distance(column1, column2, method)
Parameter |
Description |
|---|---|
column1 |
The first attribute used to evaluate the distance. If it is not nominal, it will be cast to nominal upon function’s computation. The column1 parameter is mandatory. |
column2 |
The second attribute used to evaluate the distance. If it is not nominal, it will be cast to nominal upon function’s computation. The column2 parameter is mandatory. |
method |
The algorithm (”levenshtein“, “damerau-levenshtein“, “lcs“, “hamming“) used to evaluate the string distance. Each method is associated to a string: The method parameter is mandatory.
|
See also
The distance method algorithms:
The Levenshtein algorithm measures the difference between two different strings. (e.g. from the string ‘like’ and ‘likely’ the Levenshtein value is 2, as we need to perform two operations, that are adding a ‘l’ and a ‘y’ to ‘like’ to transform the ‘like’ string into the ‘likely’ string).
The Damerau-Levenshtein algorithm measures the edit distance between two different strings. It includes transpositions among its allowable operations in addition to the three classical single-character edit operations (insertions, deletions and substitutions) typical of the Levenshtein algorithm.
The lcs algorithm finds the longest subsequence common to a set of them. Subsequences are not required to occupy consecutive positions within the original sequences.
The hamming algorithm finds errors in a sequence of code-words. If its value is 0 or 1, then the word sequence is reliable.
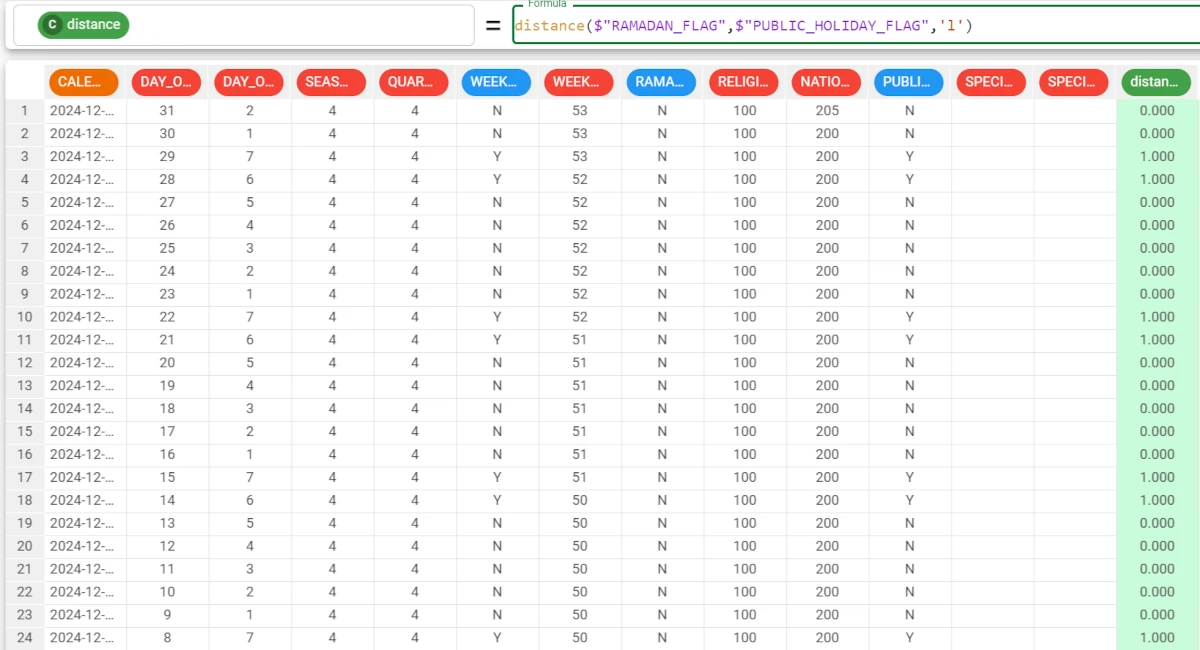
Example - distance(column1, column2, method)
The following example uses the Turkish calendar dataset.
In this example, we want to calculate the distance between the RAMADAN_FLAG attribute and the PUBLIC_HOLIDAY_FLAG attributes using the Levenshtein algorithm.
Add a new attribute, called distance, and type the following formula:
distance($"RAMADAN_FLAG",$"PUBLIC_HOLIDAY_FLAG",'l').The function has returned 0, when the value in both attributes is the same, so no changes has to be made to make them equal.
It has returned 1 when the values were not equal, indicating the operations to perform to make the values equal.
find¶
The find function looks for a value within a column and returns True or False.
Parameters
find(column, value, binary, ischarlist, charpos)
Parameter |
Description |
|---|---|
column |
The nominal attribute where the value will be searched. If it is not nominal, it will be cast to nominal upon function’s computation. The column parameter is mandatory. |
value |
The value to be searched in the column. If it is not nominal, it will be cast to nominal upon function’s computation. The value parameter is mandatory.The value parameter is case-sensitive. |
binary |
If it is |
ischarlist |
If it is |
charpos |
If it is =0, True is returned if the value is present in the column. If |
Example - find(column, value, charpos=charpos)
The following example uses the Adult dataset.
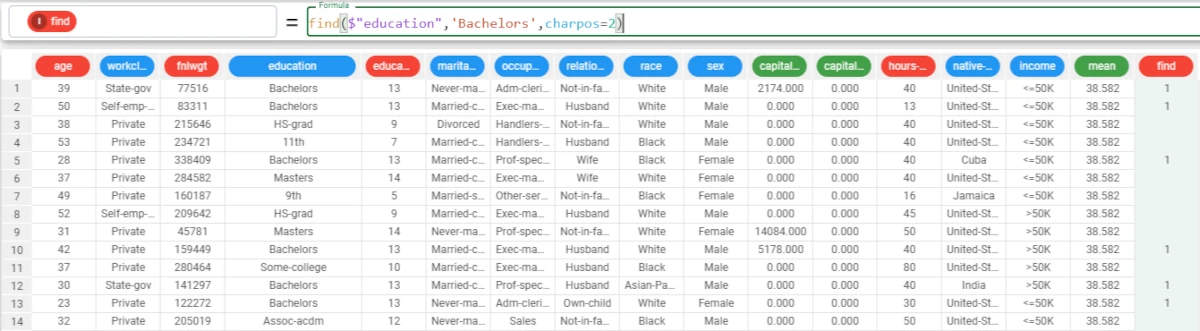
In this example, we want to find the Bachelors value in the Education attribute.
Add a new attribute, called find, and type the following formula:
find($"education",'Bachelors',charpos=2).As we didn’t specify the binary and ischarlist parameters (we want to keep the default options), we needed to write
charpos=2.If the binary and is charlist parameters would have been specified, we should have written only 2 in the formula.
The function returns a 1 when the Bachelors value is found, or an empty cell when the value is not present in the corresponding row.
head¶
The head function returns in each row the first n letters of the corresponding value in the column.
Parameters
head(column, nchar)
Parameter |
Description |
|---|---|
column |
The nominal attribute containing the strings. If the column is not nominal, it will be cast to nominal upon function’s computation. The column parameter is mandatory. |
nchar |
The number of letters we want to select for each string in the column. It can be either a specified value or an integer attribute. The nchar parameter is mandatory. |
Example - head(column, nchar)
The following example uses the Adult dataset.
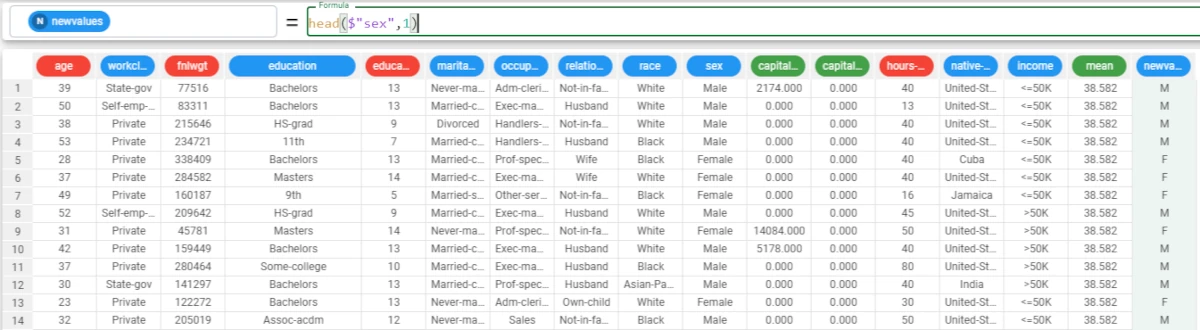
In this example, we want to transform the Sex attribute values into their initial.
Add a new attribute, called newvalues, and write the following formula:
head($"sex",1).The function has returned the first letter of each value in the corresponding row.
isPrefix¶
The isPrefix function checks whether a string is a prefix or not, and returns True in the rows of the column starting with the string value; otherwise the function returns False.
Parameters
isPrefix(column, value, binary)
Parameter |
Description |
|---|---|
column |
The nominal attribute in which the value will be checked. If it is not nominal, it will be cast to nominal upon function’s computation. The column parameter is mandatory. |
value |
The value to be checked in the column. If it is not nominal, it will be cast to nominal upon function’s computation. The value parameter is mandatory.The value parameter is case-sensitive. |
binary |
If it is |
Example - isPrefix(column, value)
The following example uses the HR-Employee-Attrition dataset.
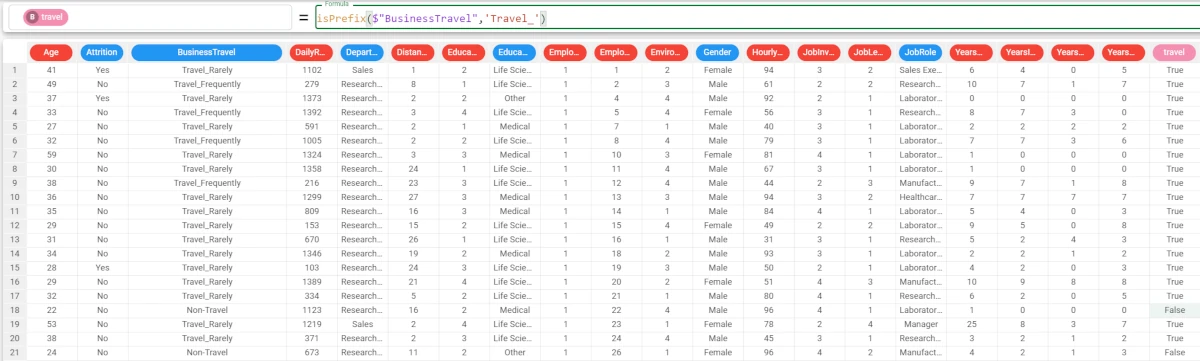
In this example, we want to identify if the string ‘Travel’ is a prefix for the values in the BusinessTravel attribute.
Add a new attribute, which we have called travel, and type the following formula:
isPrefix($"BusinessTravel",'Travel_').The results are provided as boolean values, as we didn’t specify the binary parameter.
isSuffix¶
The isSuffix function checks whether a string is a suffix or not, and returns True in the rows of the column ending with the string value; otherwise False is returned.
Parameters
isSuffix(column, value, binary)
Parameter |
Description |
|---|---|
column |
The nominal attribute in which the value will be checked. If it is not nominal, it will be cast to nominal upon function’s computation. The column parameter is mandatory. |
value |
The value to be checked in the column. If it is not nominal, it will be cast to nominal upon function’s computation. The value parameter is mandatory.The value parameter is case-sensitive. |
binary |
If it is |
Example - isSuffix(column, value, binary)
The following example uses the Adult dataset.
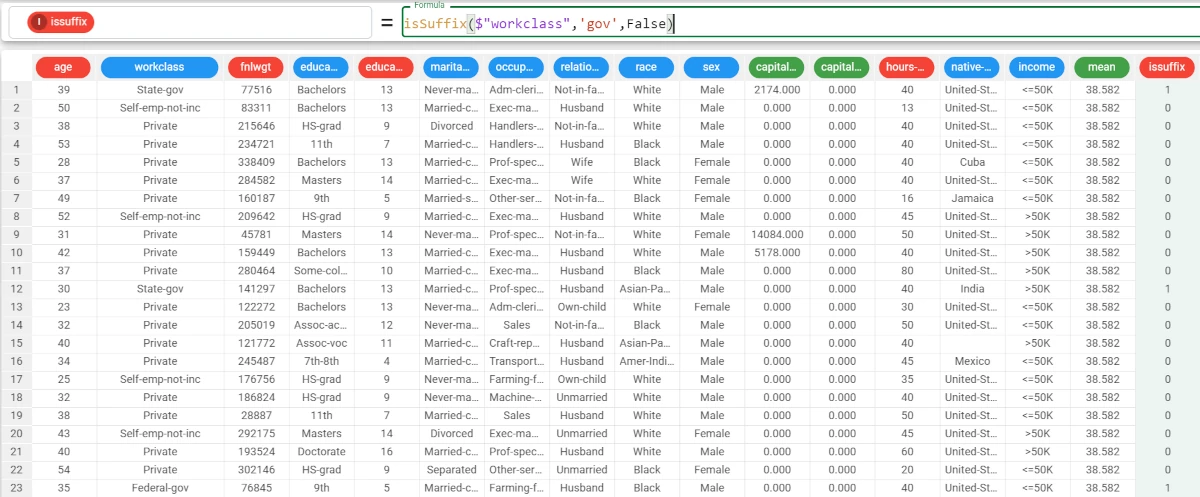
In this example, we want to know if the string ‘gov’ is a suffix for all the values of the occupation attribute.
Add a new attribute, which we have called suffix, and type the following formula:
isSuffix($"workclass",'gov',False).As we have specified the binary parameter as
False, the results will be provided in binary form (1/0), where 1 meansTrue, and 0False.
isWord¶
The isWord function checks whether a string (which can have a delimiter) is contained in an attribute or not.
Parameters
isWord(column, substring, delimiter, binary)
Parameter |
Description |
|---|---|
column |
The nominal attribute in which the substring will be checked. If it is not nominal, it will be cast to nominal upon function’s computation. The column parameter is mandatory. |
substring |
The substring to be checked in the column. If it is not nominal, it will be cast to nominal upon function’s computation. The substring parameter is mandatory.The substring parameter is case-sensitive. |
delimiter |
The delimiter of the substring. If it is not specified, the delimiter is (space) as default. |
binary |
If it is |
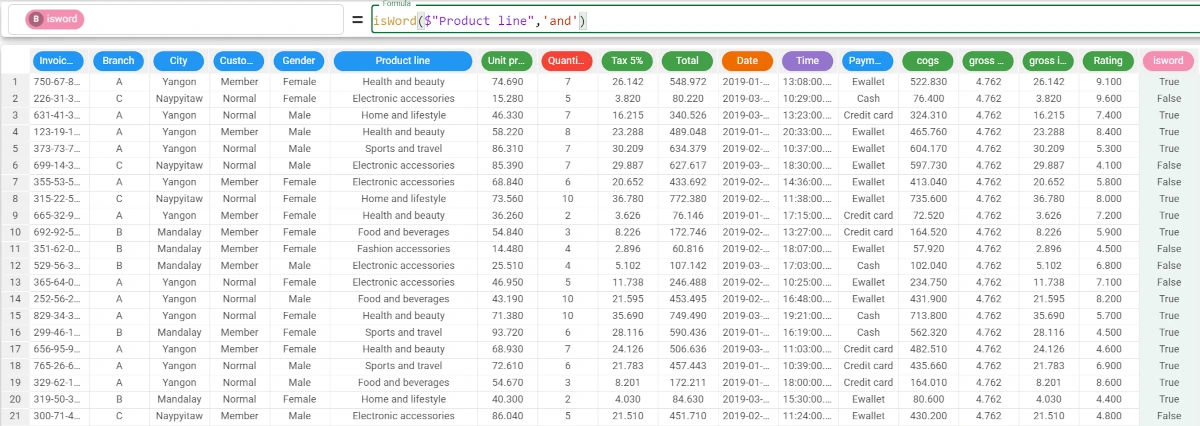
Example - isWord(column, substring)
The following example uses the supermarket_sales dataset.
In this example, we want to check if the string ‘and’ is present in the Product line attribute.
Add a new attribute, which we have called isword, and type the following formula:
isWord($"Product line",'and').As we didn’t specify the binary parameter, the results are provided as boolean values. The delimiter parameter hasn’t been specified.
numExt¶
The numExt function returns a string containing only the numerical characters of the input string. If more than one number is present, numbers are delimited by a separator decided by the user (by default “-“).
Parameters
numExt(column, onlyint, separator)
Parameter |
Description |
|---|---|
column |
The nominal attribute used to evaluate the numeric extraction. If it is not nominal, it will be cast to nominal upon function’s computation. The column parameter is mandatory. |
onlyint |
If it is |
separator |
The separator used in case of multiple number extraction. It is ‘-’ as default. |
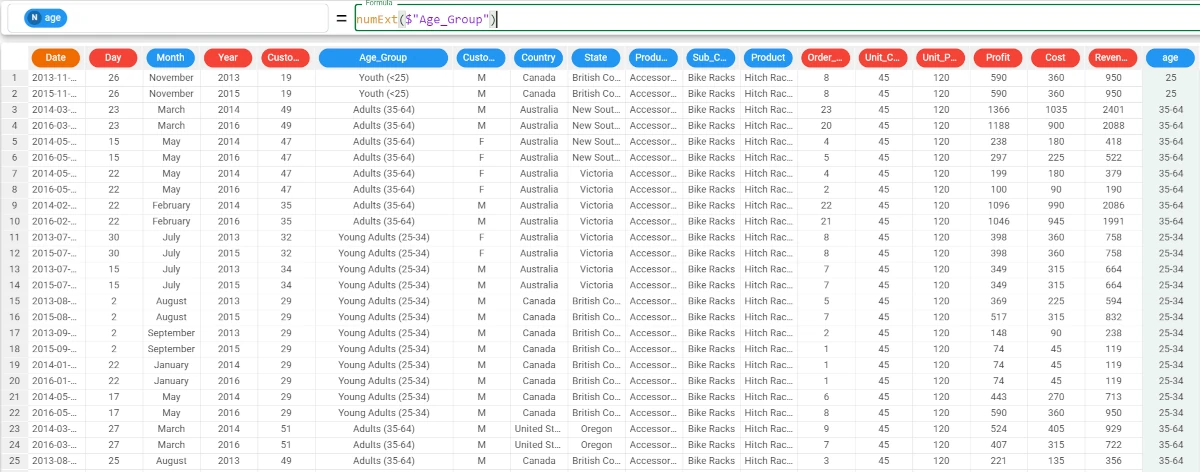
Example - numExt(column)
The following example uses the Bike sales dataset.
In this example, we want to create a new attribute, filled with the ages of the Age_Group attribute.
Add a new attribute, which we have called age, and type the following formula:
numExt($"Age_Group")and the attribute will be filled with the numbers only.
pad¶
The pad function returns in each row of the result, the values of the column, filled (padded) with the padstring value to reach the specified length. The string can be added at the beginning (where = “begin” or by default) or at the end (where = “end”) of the string, according to the value of the parameter where.
Parameters
pad(column, len, value, where)
Parameter |
Description |
|---|---|
column |
The nominal attribute used to compute the text lengths. If it is not nominal, it will be cast to nominal upon function’s computation. The column parameter is mandatory. |
len |
The length (number of letters) of the resulting words. The len parameter is mandatory. |
value |
The padstring to be added to fill the desired length, if the original word is shorter than the len. It is set to 0 as default. If the padstring is not nominal, it will be cast to nominal upon function’s computation. |
where |
It controls the position where the padstring is added. If it is ‘begin’, the padstring will be added at the beginning of the word, while if it is ‘end’, the padstring will be added at the end. |
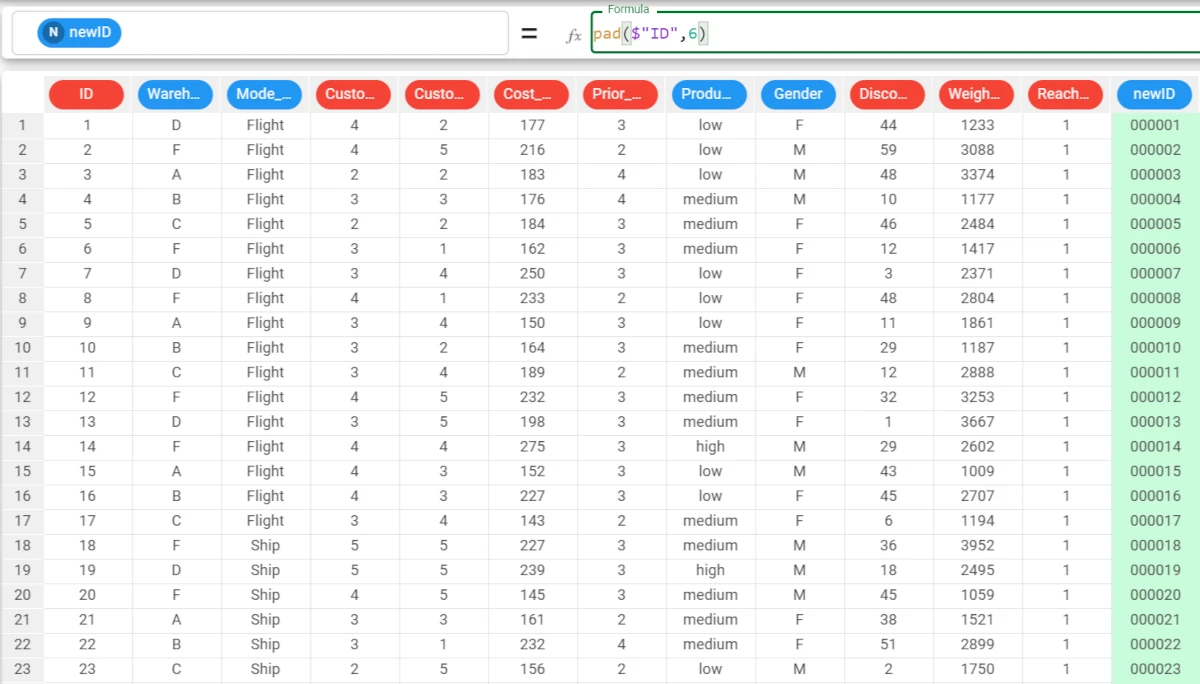
Example - pad(column, len)
The following example uses the E-commerce shipping data dataset.
In this example, we want the ID attribute values to have the same length, which is 6 for administrative reasons.
Add a new attribute, called newID and type the following formula:
pad($"ID",6).As we didn’t specify any value parameters, 0 is added to reach the len.
As we didn’t specify any where parameters, the values are added at the beginning of the word.
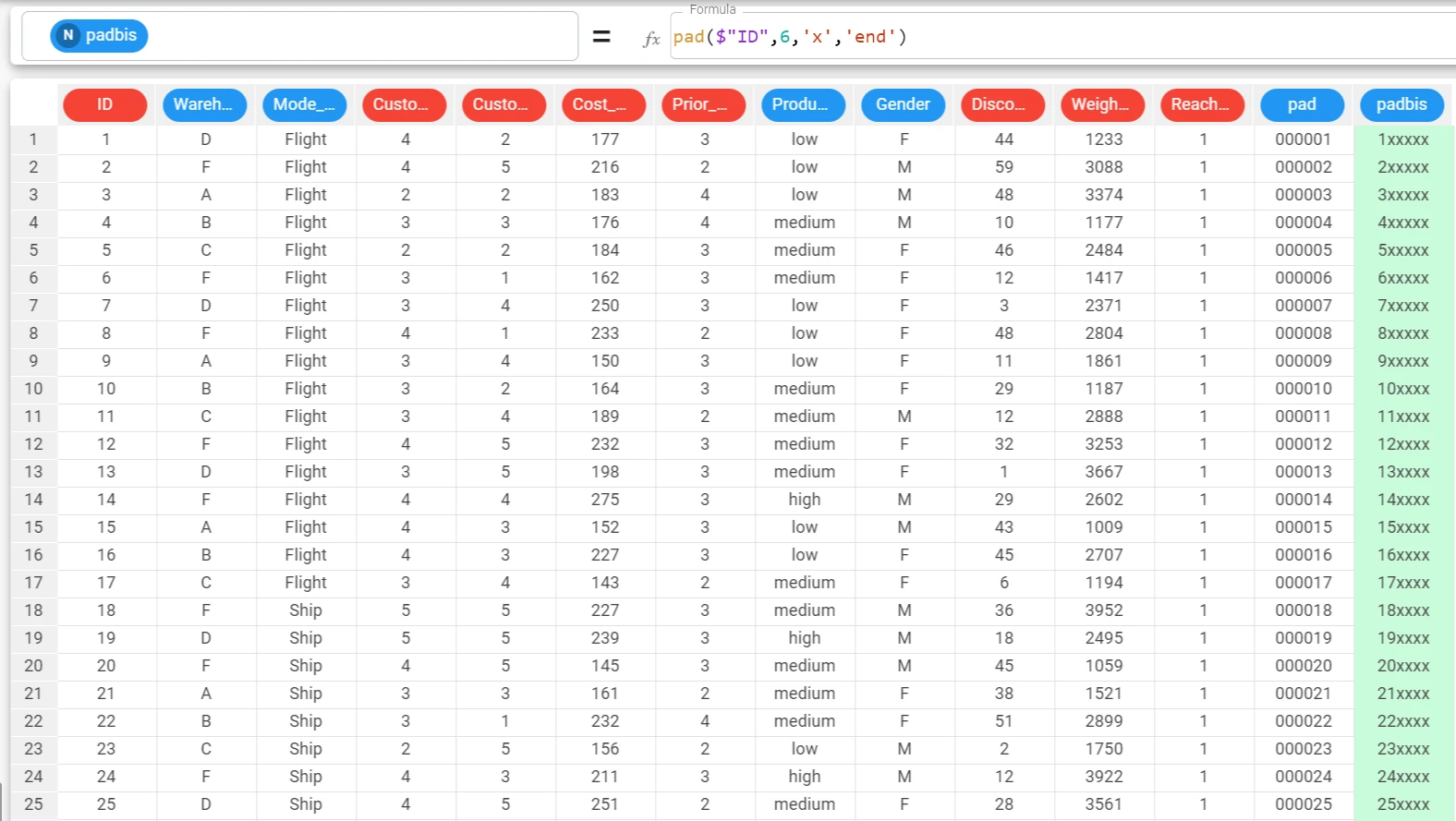
Example - pad(column, len, value, where)
The following example uses the E-commerce shipping data dataset.
If we want to add specific values (x) at the end of the ID attribute’s strings, we need to add the value and where parameters to the function.
The function becomes:
pad($"ID",6,'x','end').
phonetic¶
The phonetic function returns the phonetic encoding of the strings contained in the column using the Metaphone algorithm. Phonetic may return the primary Metaphone component (component = “Primary” or component = “P”) or the secondary component (component = “Secondary” or component = “S”). By default, the primary component is returned.
Note
The Metaphone algorithm is a phonetic algorithm for indexing words by their English pronunciation. Its features are the as follows:
Drop duplicate adjacent letters, except for C.
If the word begins with ‘KN’, ‘GN’, ‘PN’, ‘AE’, ‘WR’, drop the first letter.
Drop ‘B’ if after ‘M’ at the end of the word.
‘C’ transforms to ‘X’ if followed by ‘IA’ or ‘H’ (unless in latter case, it is part of ‘-SCH-’, in which case it transforms to ‘K’). ‘C’ transforms to ‘S’ if followed by ‘I’, ‘E’, or ‘Y’. Otherwise, ‘C’ transforms to ‘K’.
‘D’ transforms to ‘J’ if followed by ‘GE’, ‘GY’, or ‘GI’. Otherwise, ‘D’ transforms to ‘T’.
Drop ‘G’ if followed by ‘H’ and ‘H’ is not at the end or before a vowel. Drop ‘G’ if followed by ‘N’ or ‘NED’ and is at the end.
‘G’ transforms to ‘J’ if before ‘I’, ‘E’, or ‘Y’, and it is not in ‘GG’. Otherwise, ‘G’ transforms to ‘K’.
Drop ‘H’ if after vowel and not before a vowel.
‘CK’ transforms to ‘K’.
‘PH’ transforms to ‘F’.
‘Q’ transforms to ‘K’.
‘S’ transforms to ‘X’ if followed by ‘H’, ‘IO’, or ‘IA’.
‘T’ transforms to ‘X’ if followed by ‘IA’ or ‘IO’. ‘TH’ transforms to ‘0’. Drop ‘T’ if followed by ‘CH’.
‘V’ transforms to ‘F’.
‘WH’ transforms to ‘W’ if at the beginning. Drop ‘W’ if not followed by a vowel.
‘X’ transforms to ‘S’ if at the beginning. Otherwise, ‘X’ transforms to ‘KS’.
Drop ‘Y’ if not followed by a vowel.
‘Z’ transforms to ‘S’.
Drop all vowels unless it is the beginning.
Parameters
phonetic(column, component)
Parameter |
Description |
|---|---|
column |
The nominal attribute used to evaluate the phonetic encoding. If it is not nominal, it will be cast to nominal upon function’s computation. The column parameter is mandatory. |
component |
If Primary, P or not specified, the function returns the primary component. If Secondary or S, the secondary component is returned. |
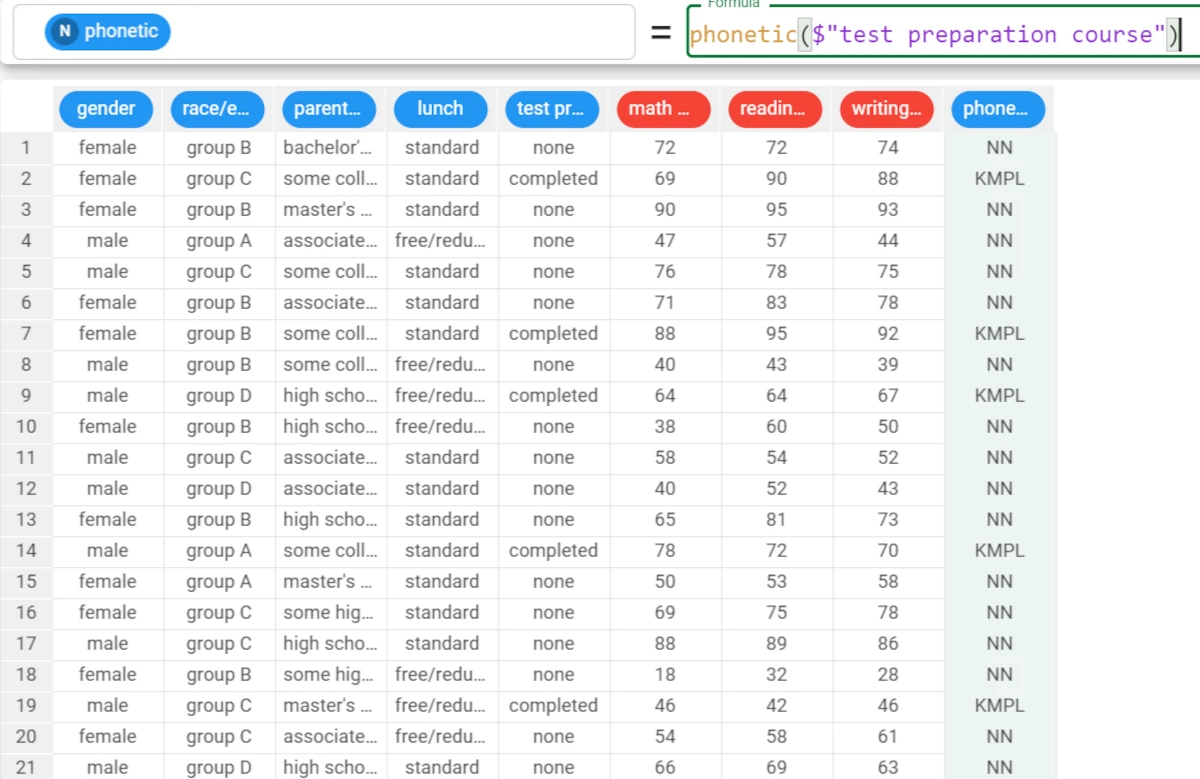
Example - phonetic(column)
The following example uses the Students_performance dataset.
In this example, we want to retrieve the pronunciation of the test preparation course attribute.
Add a new attribute, called phonetic, and type the following formula:
phonetic($"test preparation course")and the attribute is filled with the primary component, as the component parameter hasn’t been specified.
prefix¶
The prefix function considers the chosen value as prefix and returns the preceding characters.
Parameters
prefix(column, value, last)
Parameter |
Description |
|---|---|
column |
The nominal attribute containing the strings. If it is not nominal, it will be cast to nominal upon function’s computation. The column parameter is mandatory. |
value |
The substring value to be searched into the strings of the column. The value parameter is mandatory.The value parameter is case-sensitive. |
last |
If |
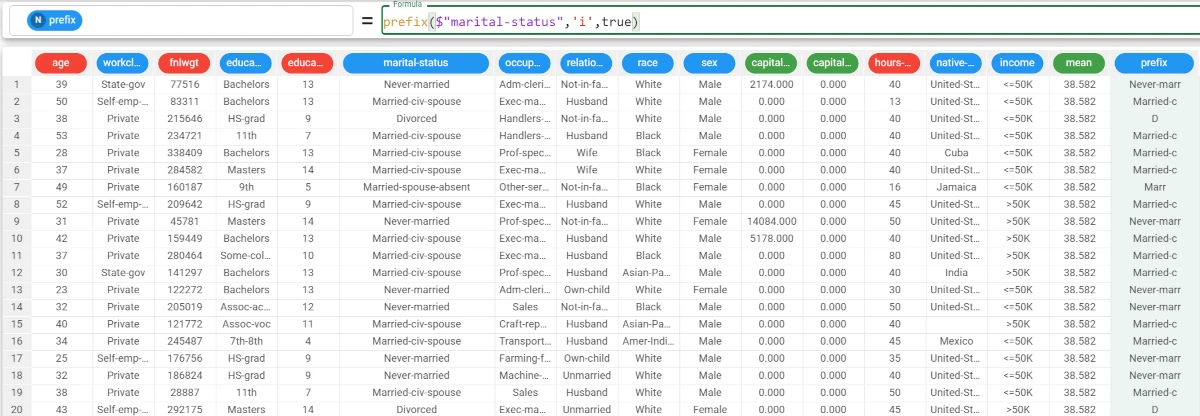
Example - prefix(column, value, last)
The following example uses the Adult dataset.
In this example, we want to retrieve as prefixes the characters before the i in the marital-status attribute.
Add a new attribute, called prefix, and type the following formula:
prefix($"marital-status",'i',true).As we have specified
Truein the last parameter, the function will consider the last occurrence of the value: as we can see in row 2, Married-civ-spouse becomes Married-c, as the function considers the last occurrence of the value.
replace¶
The replace function replaces the current strings of the values in the column with the new ones.
Parameters
replace(column, oldvalue, newvalue, ntimes)
Parameters |
Description |
|---|---|
column |
The nominal attribute containing the strings of the values to be replaced. If it is not nominal, it will be cast to nominal upon function’s computation. The column parameter is mandatory. |
oldvalue |
The value to be replaced within the column. The oldvalue parameter is mandatory. |
newvalue |
The new value which replaces the oldvalue. The newvalue parameter is mandatory. The newvalue parameter is case-sensitive. |
ntimes |
If 0, or not specified, all the occurrences of the oldvalue within all the attribute’s values will be replaced. If a positive number is specified, it indicates the number of times the newvalue will replace the oldvalue starting from the beginning of all the values within the attribute. If a negative number is specified, it indicates the number of times the newvalue will replace the oldvalue starting from the end of all the values within the attribute. |
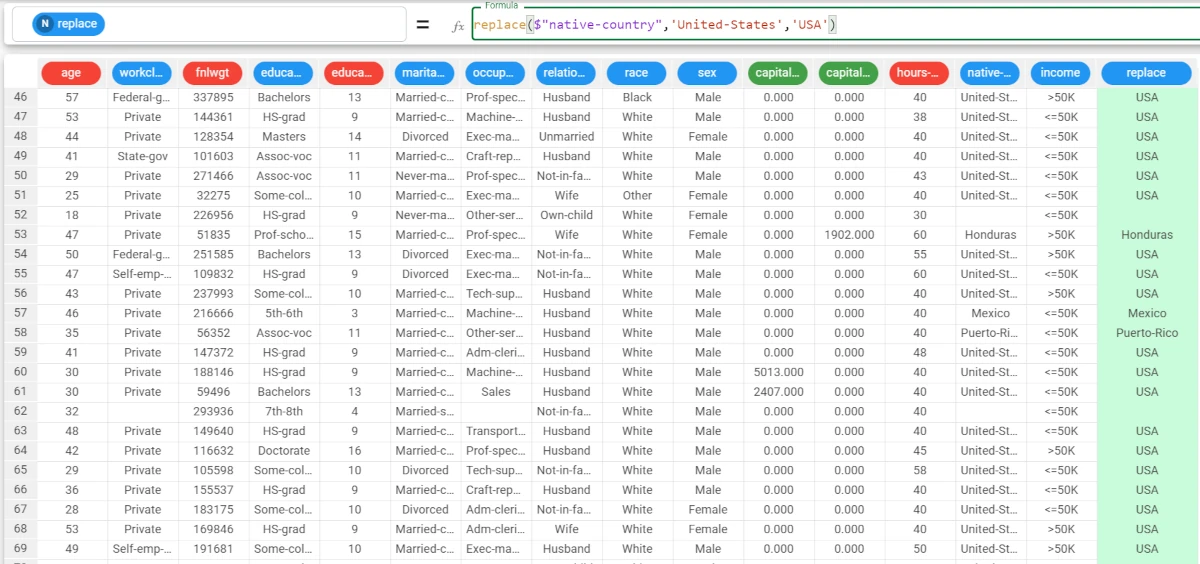
Example - replace(column, oldvalue, newvalue)
The following example uses the Adult dataset.
In this example, we want to replace the Female values of the sex attribute with F, and the Male values of the sex attribute with M.
Add a new attribute, called replace, and type the following formula first:
replace($"native-country",'United-States','USA').As we didn’t specify the ntimes parameter, all the Female values of the column are replaced.
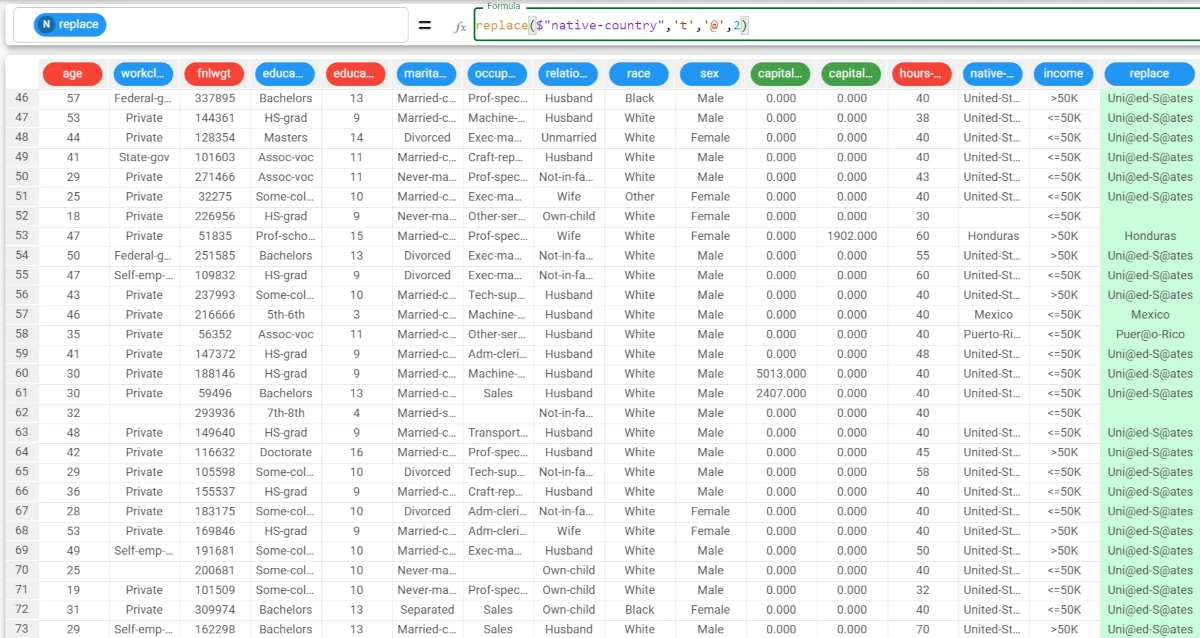
Example - replace(column, oldvalue, newvalue, ntimes)
The following example uses the Adult dataset.
In this example, we want to replace the Female values of the sex attribute with F, and the Male values of the sex attribute with M but only in the first two occurrences.
Then, type:
replace($"native-country",'t','@',2).As you can see, for each occurrence of the ‘United-States’ value the first two occurrences of the ‘t’ are replaced by the @.
strip¶
The strip function returns the value without the specified characters or list of characters located at the beginning, at the end or on both sides of the value.
Parameters
strip(column, value, where, ischarlist)
Parameter |
Description |
|---|---|
column |
The nominal attribute containing the original values. If it is not nominal, it will be cast to nominal upon function’s computation. The column parameter is mandatory. |
value |
The value containing the string or the list of characters to be removed. If it is not nominal, it will be cast to nominal upon function’s computation. The value parameter is mandatory.The value parameter is case-sensitive. |
where |
If it is begin, or not specified, the value will be removed from the beginning of the word. If it is end, the value will be removed at the end of the word. If it is both, the value will be removed both at the end and the beginning of the word. |
ischarlist |
If it is |
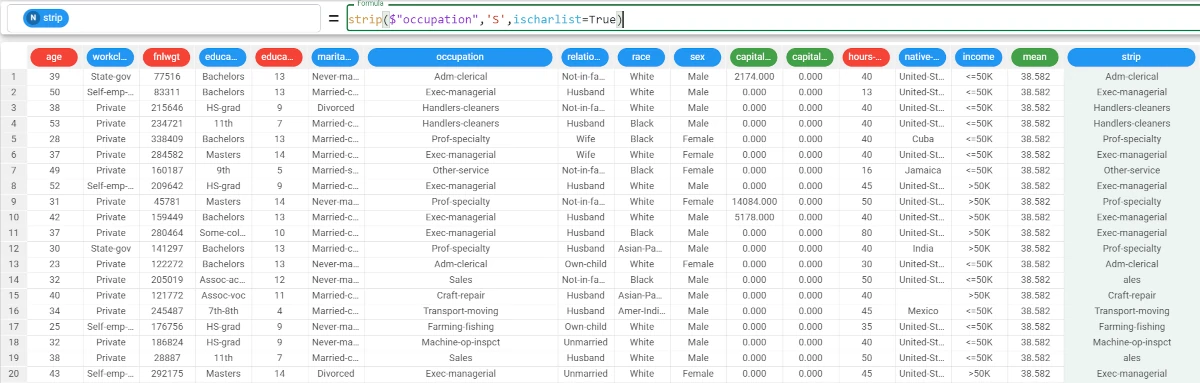
Example - strip(column, value, ischarlist=ischarlist)
The following example uses the Adult dataset.
In this example, we want to cancel the ‘S’ not only as a block, but also as a list of characters from the occupation attribute.
Add a new attribute, which we will call strip, and type the following formula:
strip($"occupation",'S',ischarlist=True).As we didn’t specify the where parameter, we needed to specify the parameter name in the formula.
suffix¶
The suffix function considers the chosen value as suffix and returns the subsequent characters.
Parameters
suffix(column, value, last)
Parameter |
Description |
|---|---|
column |
The nominal attribute containing the strings. If it is not nominal, it will be cast to nominal upon function’s computation. The column parameter is mandatory. |
value |
The substring value to be searched into the strings of the column. The value parameter is mandatory. The value parameter is case-sensitive. |
last |
If |
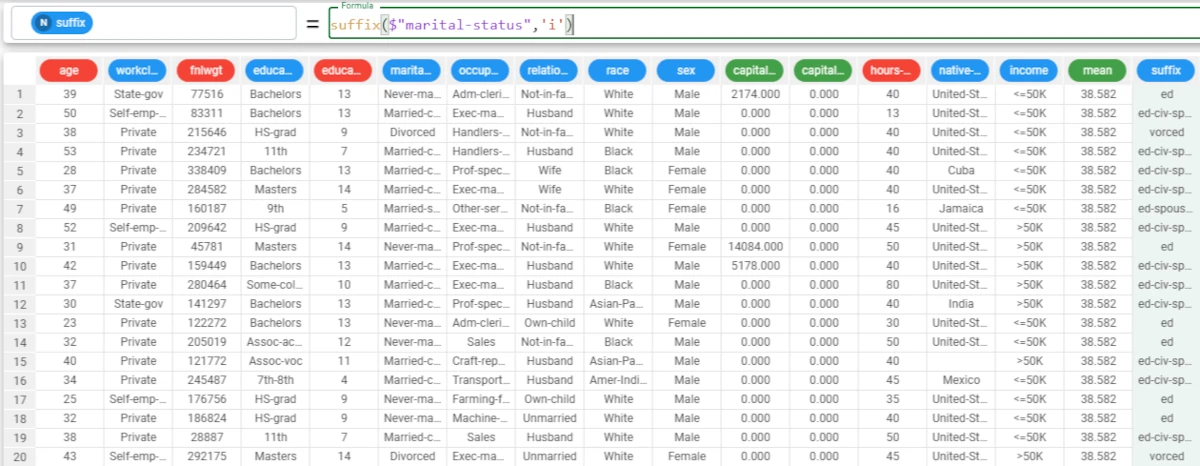
Example - suffix(column, value, last)
The following example uses the Adult dataset.
In this example, we want to retrieve as suffixes the characters after the i in the marital-status attribute.
Add a new attribute, which we have called suffix, and type the following formula:
suffix($"marital-status",'i').As we didn’t specify the last parameter, the function considers as suffix all the characters after the first value (i in this example) occurrence.
tail¶
The tail function returns the last n letters of the corresponding value in the column.
Parameters
tail(column, nchar)
Parameter |
Description |
|---|---|
column |
The nominal attribute containing the strings. If it is not nominal, it will be cast to nominal upon function’s computation. The column parameter is mandatory. |
nchar |
Number of characters we want to select at the end of the string. It can be either a specified value or an integer attribute. The nchar parameter is mandatory. |
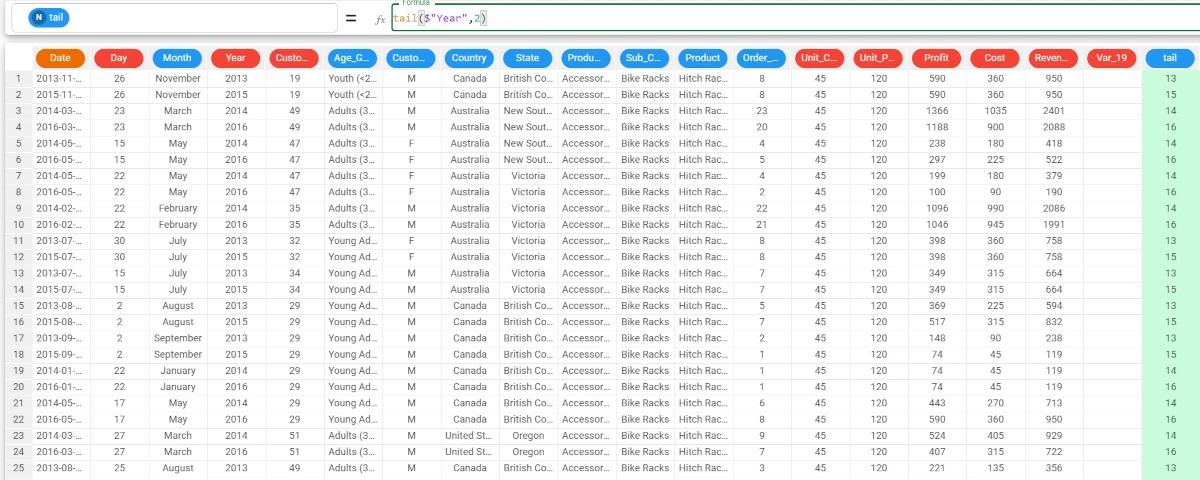
Example - tail(column, nchar)
The following example uses the Bike sales dataset.
In this example, we want to retrieve the tail of the values of the Year attribute.
Select the Year attribute and type the following formula:
tail($"Year",2).As Year is an integer attribute, the function cast it to nominal.
textConcat¶
The textConcat function returns the concatenation of all the strings in a column.
Parameters
textConcat(column,separator,group)
Parameter |
Description |
|---|---|
column |
The nominal attribute used to evaluate the text concatenation. The column parameter is mandatory.It can also be defined as a list, and in this case the function returns per each row the concatenated strings of the attributes listed. If it is not nominal, it will be cast to nominal upon function’s computation. |
separator |
The customized separator to be used in the concatenation. |
group |
The attribute used to group results; The group parameter can also be defined as a list. If the column parameter is defined as a list, then the group parameter is ignored. |
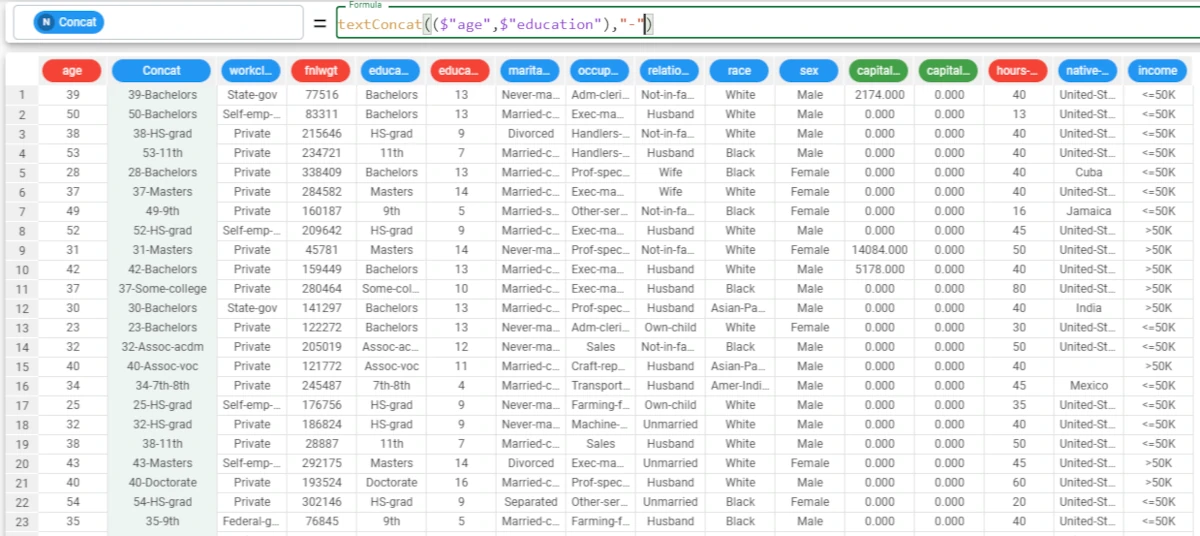
Example - textConcat(column, separator)
The following example uses the Adult dataset.
In this example, we want to concatenate the strings of 2 attributes, and separated by a dash.
To achieve this goal we’re going to use the following formula:
textConcat(($"age","education"),"-").If you only define the education attribute as column parameter, all the strings contained in that column will be concatenated in each row.
textExtract¶
The textExtract function returns the string ranging from a defined starting position to defined ending position.
Parameters
textExtract(column,startpos,endpos)
Parameter |
Description |
|---|---|
column |
The nominal attribute used to extract the substring. The column parameter is mandatory.If it is not nominal, it will be cast to nominal upon function’s computation. |
startpos |
The position of the letter where the extraction starts (the first letter is 1). It can be either a specified value or an integer attribute. The startpos parameter is mandatory. |
endpos |
The position of the letter where the extraction ends. It can be either a specified value or an integer attribute. The endpos parameter is mandatory. |
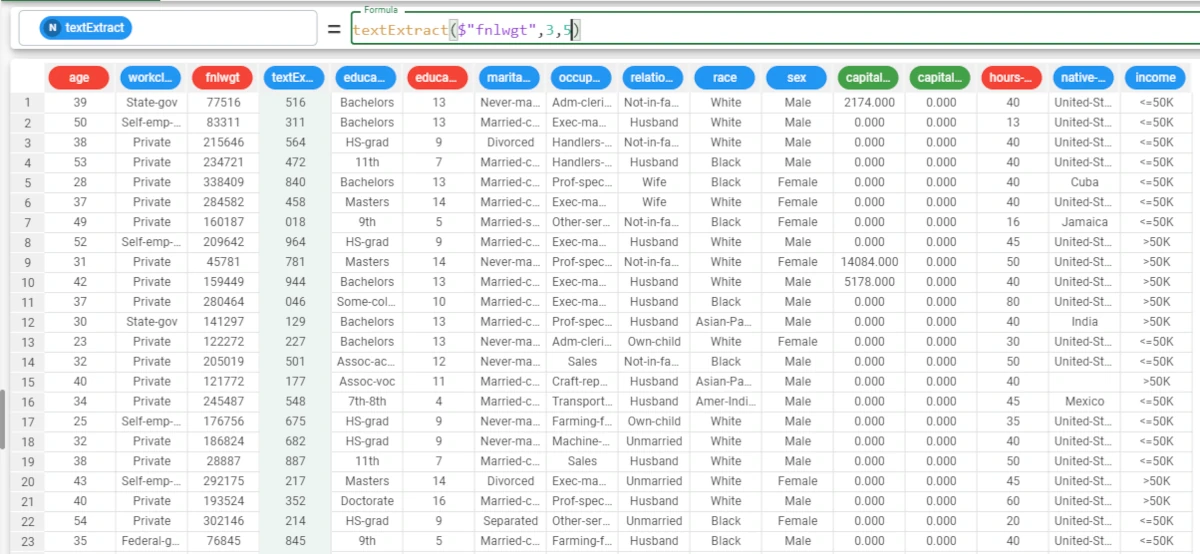
Example - textExtract(column, startpos, endpos)
The following example uses the Adult dataset.
In this example, we want to retrieve a subset of the string contained in the fnlwgt attribute.
To achieve this goal we’re going to use the following formula:
textExtract($"fnlwgt",3,5).3 is the starting position of the string we need, and 5 is the ending.
textFormat¶
The textFormat function returns the type of the strings in each row of the column.
Parameters
textFormat(column)
Parameter |
Description |
|---|---|
column |
The attribute from which we want to retrieve the type of each string. Its type must be nominal. The column parameter is mandatory. |
Example - textFormat(column)
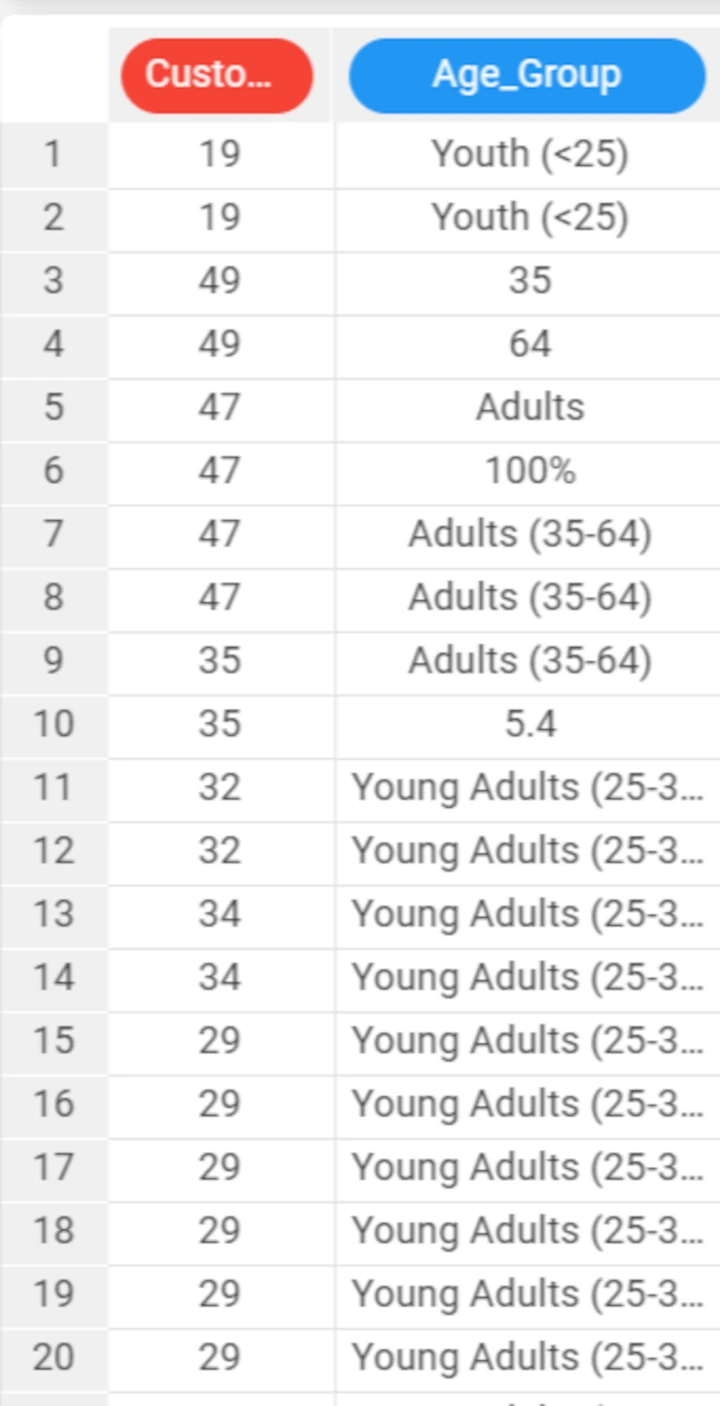
The following example uses the Bike sales dataset.
In this example, we have manually updated certain values within the Age Group attribute.
We have added: * 35 in row 3; * 64 in row 4; * 100% in row 6; * 5.4 in row 10.
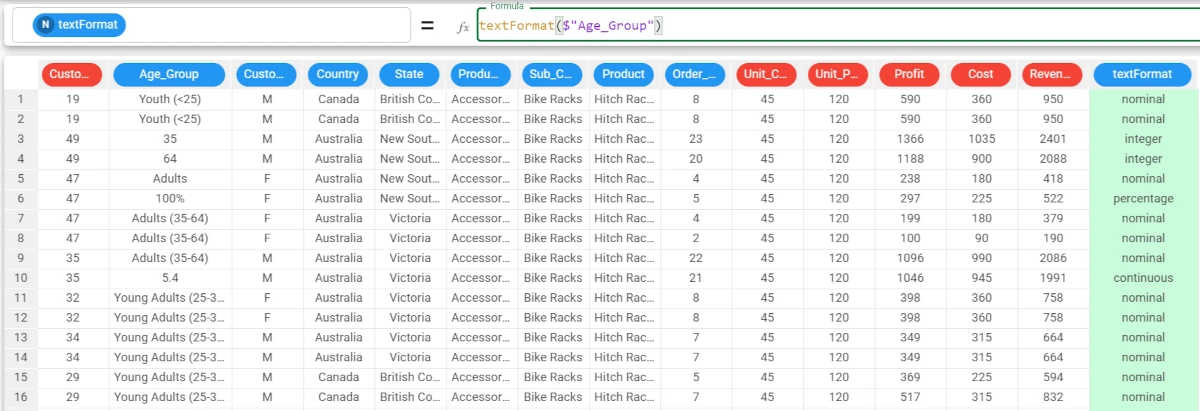
Rename the Var_19 attribute to textFormat, then type the following formula:
textFormat($"Age_Group").As you can see, the function has returned ‘nominal’ for all the values except: * row 3, which is ‘integer’; * row 4, which is ‘integer’; * row 6, which is ‘percentage’; * row 10, which is ‘continuous’.
textLen¶
The textLen function returns the length of the string contained in each row of the column.
Parameters
textLen(column,mode,leaveother)
Parameter |
Description |
|---|---|
column |
The attribute used to count the string length. The column parameter is mandatory.If it is not nominal, it will be cast to nominal upon function’s computation. |
Example - textLen(column)
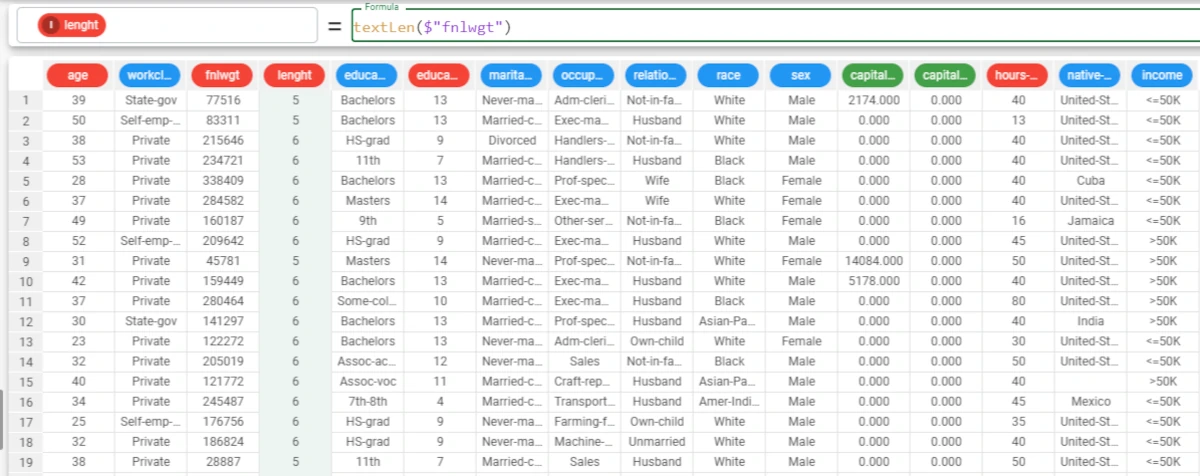
The following example uses the Adult dataset.
In this example, we want to count the length of the strings contained in each row of an attribute.
To achieve this goal we’re going to use the following formula:
textLen($"fnlwgt").Here we can see that the formula has counted the number of characters each row contains.
textLower¶
The textLower function changes uppercase fonts of a nominal attribute to lowercase fonts.
Parameters
textLower(column,mode,leaveother)
Parameter |
Description |
column |
The nominal attribute to which modify the fonts to lowercase. The *column* parameter is mandatory. |
mode |
By default the textLower function changes all fonts to lowercase, and the following are the permitted parameters: |
leaveother |
If left empty or not specified, the default leaveother parameter is |
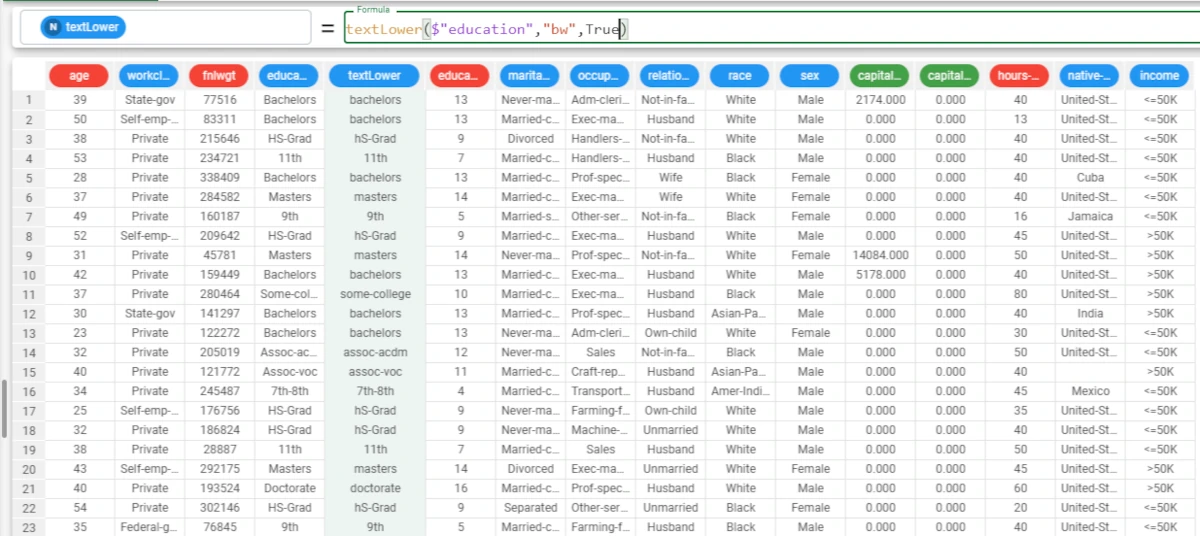
Example - textLower(column, mode, leaveother)
The following example uses the Adult dataset.
In this example, we want to change the uppercase fonts of a nominal attribute to lowercase.
But we want to change only the first font of each string to lower case, and leave to lowercase fonts that are already lowercase.
To achieve this goal we’re going to use the following formula:
textLower($"education","bw",True)
textSort¶
The textSort function sorts in ascending order the strings contained in each cell of a nominal attribute.
Parameters
textSort(column,ascending)
Parameter |
Description |
|---|---|
column |
The nominal attribute whose strings you want to sort. The column parameter is mandatory. |
ascending |
Sets the order of the sort according to the following parameters:if it’s set as |
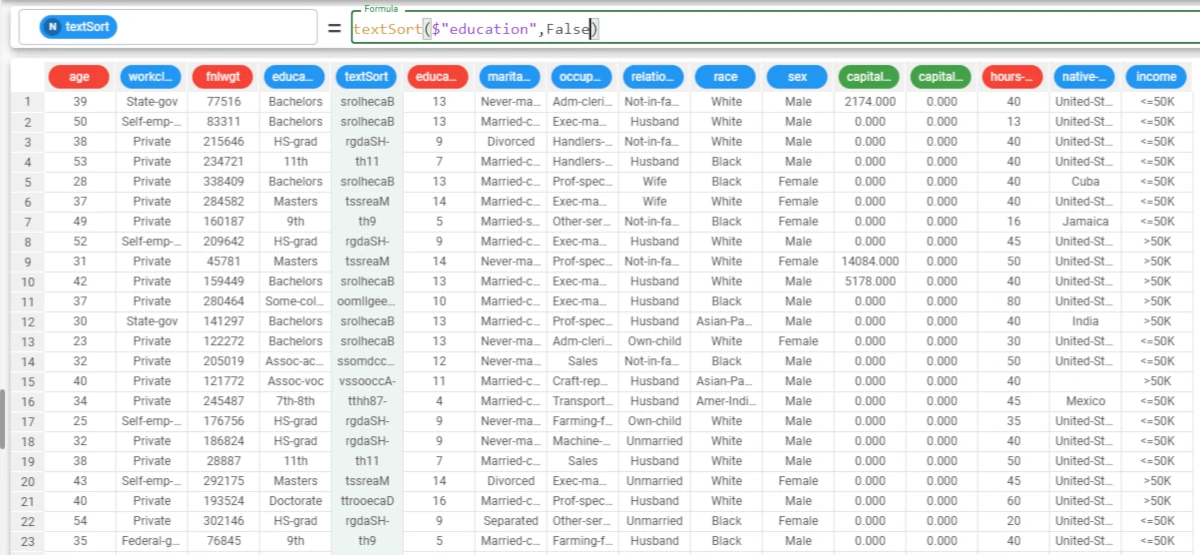
Example - textSort(column, ascending)
The following example uses the Adult dataset.
In this example, we want to sort the characters of a nominal attribute in descending order.
To achieve this goal we’re going to use the following formula:
textSort($"education",False).And, in the screenshot we can see the results obtained, now in each cell of the education attribute letters have been sorted in descending order.
textUpper¶
The textUpper function changes lowercase fonts of a nominal attribute to uppercase fonts.
Parameters
textUpper(column,mode,leaveother)
Parameter |
Description |
|---|---|
column |
The nominal attribute to which you want to change the fonts to uppercase. The column parameter is mandatory. |
mode |
By default the textUpper function changes all fonts to uppercase, and the following are the permitted parameters: |
leaveother |
If left empty or not specified, the default leaveother parameter is |
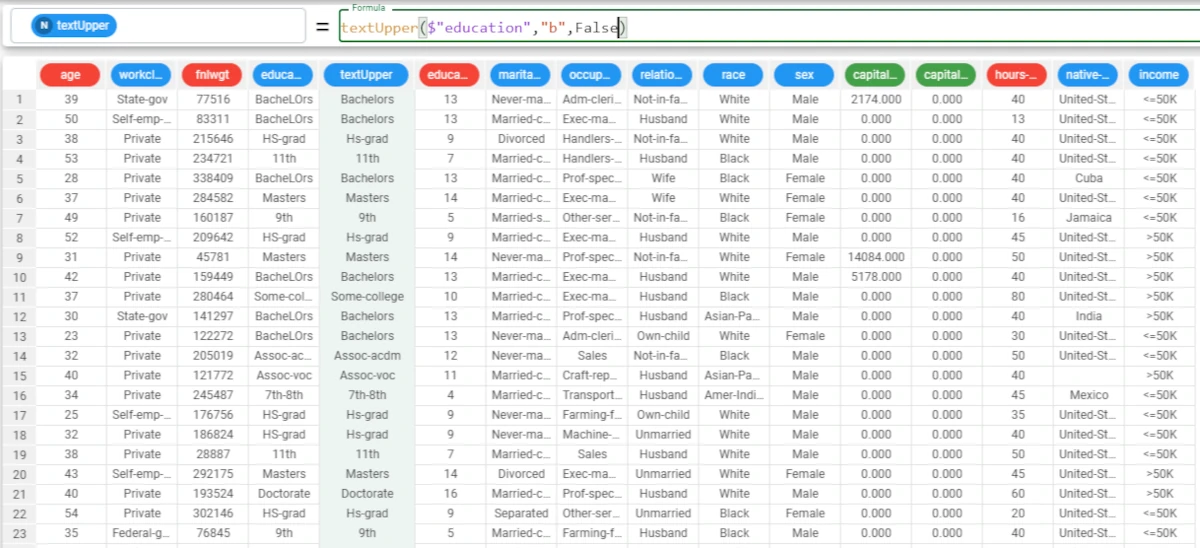
Example - textUpper(column, mode, leaveother)
The following example uses the Adult dataset.
In this example, we want to change the lowercase fonts of a nominal attribute to uppercase.
We want to change only the first font, and convert any other uppercase font to lowercase.
To achieve this goal we’re going to use the following formula:
textUpper($"education","b",False).