Split Data¶
The Split Data task divides the dataset into three subsets of patterns:
the training set, used to build the model,
the test set, used to assess the accuracy of the model, and
the validation set, used for tuning the model parameters.
The task has a very simple layout, made of only one tab, the Options tab.
The Options tab¶
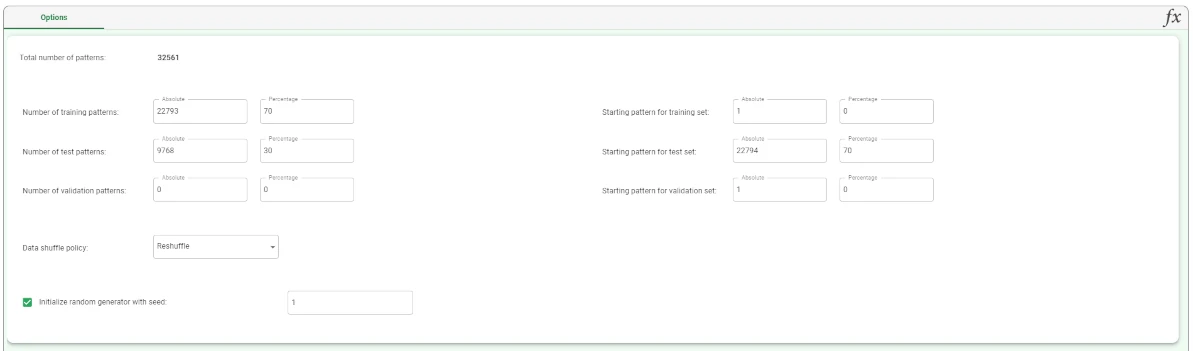
The Options tab allows users to customize their split operations, providing the following parameters:
Total number of patterns: it shows the total number of patterns in the dataset which is about to be split.
Number of training patterns: it indicates the number of training patterns, either as an absolute number of patterns or as a percentage of the overall dataset, which will be used to create the training set.
These patterns are used to build the model.Starting pattern for training set: it indicates the starting point for the training set pattern either as an absolute value, or as a percentage of the whole.
This option is valid only if No Shuffle is selected as the Data shuffle policy.Number of test patterns: it indicates the number of test patterns, either as an absolute number of patterns or as a percentage of the overall dataset, which will be used to create the test set.
These patterns are not used to build the model.Starting pattern for test set: it indicates the starting point for the test set pattern either as an absolute value, or as a percentage of the whole.
This option is valid only if No Shuffle is selected as the Data shuffle policy.Number of validation patterns: it indicates the number of validation patterns, either as an absolute number of patterns or as a percentage of the overall dataset, which will be used to create the validation set.
The validation patterns cannot be used to create or test the model and are not mandatory as they are used only for internal validation by some modeling methods.Starting pattern for validation set: it indicates the starting point for the validation set pattern either as an absolute value, or as a percentage of the whole.
This option is valid only if No Shuffle is selected as the Data shuffle policy.- Data shuffle policy: choose the required data shuffle policy from the drop-down list:
No shuffle, if you want to use the defined starting points only to define the training, test and validation patterns. Any previous shuffles are removed, and the natural pattern order is used.
Reshuffle, if you want the order of the patterns to be randomly shuffled before applying the starting pattern values to the respective set. The shuffle procedure is only used to create the three subsets, and it does not affect the real data order. A random choice usually ensures better results by improving the statistical representation of the training set. The resulting analysis cannot be identically reproduced as different Split Data tasks can produce dissimilar training sets, unless a seed is set for initialization.
Keep shuffle, if you want to preserve any previous shuffles.
Initialize random generator with seed: select this option if you want to set the seed for the random generator. This may be useful to make each execution reproducible. Otherwise, each execution of the same task (with same options) may produce dissimilar results due to the different random numbers generated to define training/test/validation sets.
Hint
When setting the Number of training patterns, the Number of test patterns updates accordingly, leaving the Number of validation patterns to 0.
If a validation set is required, just modify the Number of validation patterns option, and the Number of test patterns updates accordingly. The Number of training patterns won’t vary.
See also
All the options listed above, apart from the Data shuffle policy and the Initialize random generator with seed are number fields. To know more about number fields, go to the corresponding page.
Example¶
After having imported the dataset, it is required to split it into a training and a test set, as a classification analysis is needed.
Add a Split Data task to the flow and link it to the source dataset.
- Set the following options:
Number of training patterns - Percentage : 70%
The test set updates accordingly.
Leave the other options as default.
Save and compute the task.