Import from Parquet File¶
The Import from Parquet File task allows users to import data stored in a Parquet file, whether they have a table layout or not. The Import from Parquet File task is divided into two tabs: the Options tab (please refer to the page Import Overview for further and more detailed information) and the Parquet configuration tab, whose characteristics and configuration will be explained in the next section.
The Parquet Configuration tab¶
The Parquet Configuration tab is divided into three panes:
Parsing Options, where users can find the parsing options.
Import Options, where users can find the import options.
Table Preview, where users can visualize a preview of their imported tables.
Parsing options
Within this pane, users can set and configure the following options:
Missing string: users can enter the word they want to remove from the dataset.
Text delimiter: users can select ‘ or “ if these symbols have been used as string delimiters. They will not be included in the imported file. For example, the string “apartment” will be imported as apartment. This option will remove all instances of text delimiters in the string, and not only the initial and closing symbols. The only exception to this rule will be if the symbol is preceded by a backslash. For example, “ad"cb” will be imported as ad”cb, while “ad”cb” will be imported as adcb. The data type for values with string delimiters is nominal, and this data type will not be altered by the removal of text delimiters. For example, “3” will be imported as 3, but will remain a nominal value, instead of being converted to an integer.
Import options
Within this pane, users can set and configure the following options:
Start importing from line: the number of the line from which the importing operations will start.
Stop importing at line: the number of the line where the importing operations will end. Leave the value 0 if you want the whole dataset to be imported.
Column to be imported (empty for all): the number of columns to be imported. If left empty, all the columns will be imported.
Remove empty rows: select the checkbox if you want to remove the empty rows from the imported dataset.
Add an attribute containing: select this option to add an extra column with the name, row group index or both of the file to the dataset.
Remove empty columns: select the checkbox if you want to remove the empty columns from the imported dataset.
Case sensitive: users can select this checkbox if they want uppercase letters values to be considered different from the lower cases ones.
Strip spaces: select this option if you want to remove spaces surrounding strings. For example, the string “ class “ will be imported as “class”.
Turn off smart type recognition: if selected, prevents automatic recognition of data types, leaving the generic nominal type. This option is useful when manual identification is preferable, for example when there is the risk of a code being misinterpreted as a date.
Compress white spaces: select it to remove extra consecutive spaces from within strings. For example the string “university program” would be imported as “university program”.
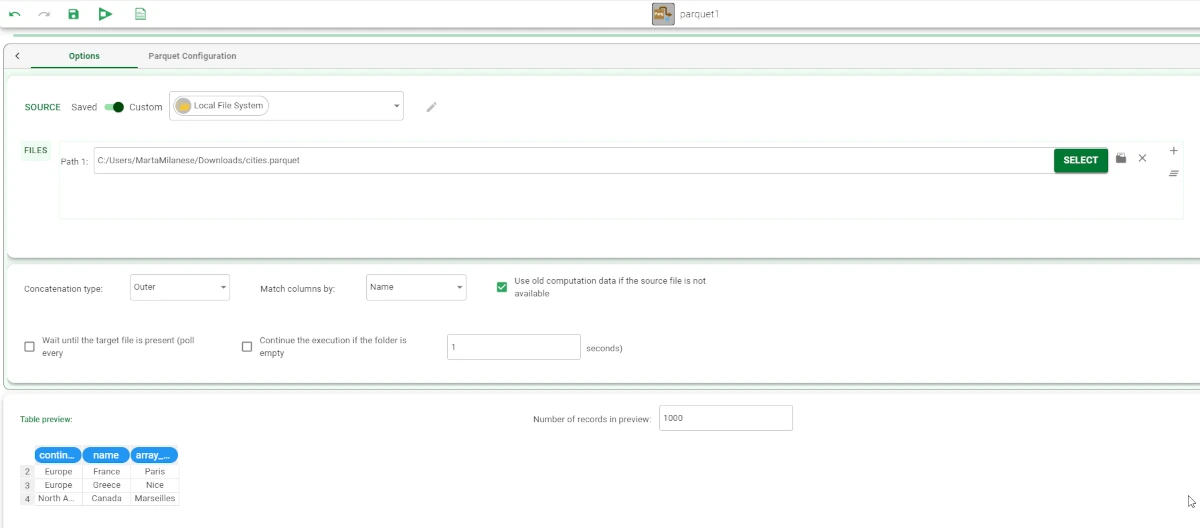
Table Preview
Within this pane, users will be able to visualize a preview of their imported tables.
On the right of the Table preview pane, users can find the Number of records in preview spin box.
Example¶
After having imported a Parquet file onto the stage, drag an Import from Parquet task onto the stage and link it to the source task.
Configure the selected task as explained in the Options tab configuration (refer to the Import Overview page) and the Parquet Configuration tab sections.
According to the selected Parquet file, your Import from Parquet task should look like the example provided below.