Linear¶
The Linear task solves regression problems where the output value is estimated to be a linear combination of the input variables using the Ordinary Least Squares (OLS) method.
The Linear task is divided into three tabs:
The Options tab, where users can choose the attribute they will work on and with.
The Coefficients tab, where users can see a visual representation in a spreadsheet format of the coefficients generated by the analysis.
The Results tab, where users can visualize a summary of the computation.
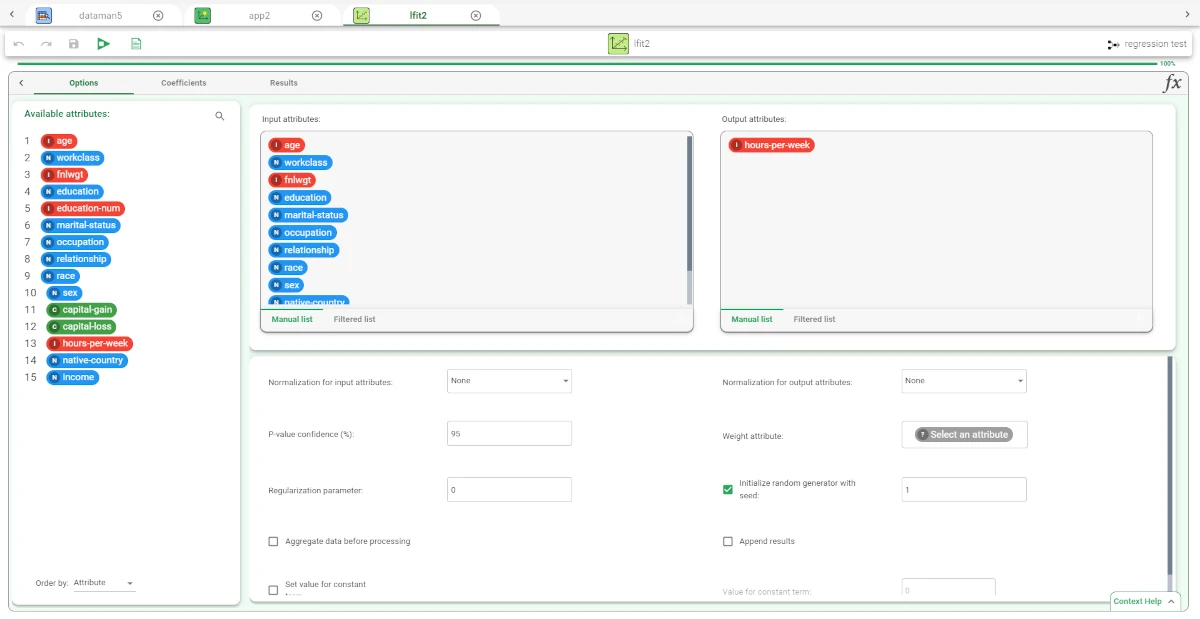
The Options tab¶
The Options tab presents the following structure:
Available attributes, where users will find the dataset’s attributes.
Attributes drop area, where users can drag the chosen attributes.
Customization pane, where users are able to customize different options.
Available Attributes
Within this section, users will find a list of all the dataset’s attributes. To search for a specific attribute, use the lens icon at the top right of the panel.
Users can also sort the attributes according to their preferences.
They can choose from a drop-down list of the Order by option:
Attribute
Name
Type
Ignored
Role
Attributes Drop Area
The Attribute drop area is divided into two panes:
The Input attributes, where users can drag and drop the input attributes they want to use to create rules for classifying data. This operation can be done via a Manual list (users need to manually drag & drop the selected attributes onto the pane) or via a Filtered list.
The Output attributes, where users can drag and drop the attributes they want to use to form the final classes into which the dataset will be divided. This operation can be done via a Manual list (users need to manually drag & drop the selected attributes onto the pane) or via a Filtered list.
Customization Pane
Within this pane, users can customize the available options, which are:
Normalization for input attributes: the type of normalization to use when treating ordered (discrete or continuous) variables. Available options are:
None
Attribute
Normal
Minmax [0.1]
Minmax [-1,1]
Normalization for output attributes: users can select which method should be adopted to normalize output variables. Available options are:
None
Attribute
Normal
Minmax [0.1]
Minmax [-1,1]
P-value confidence (%): users can set the value of the confidence coefficient.
Weight attribute: the attribute that represents the relevance (weight) of each sample.
Regularization parameter: the value of the regularization parameter that is added to the diagonal of the matrix.
Initialize random generator with seed: if selected, a seed is used to set the starting point in the sequence during random generation operations. Therefore, using the same seed each time will make each execution reproducible. Otherwise, running the same task (with identical options) may produce different outcomes due to different random numbers being generated at some stages of the process.
Aggregate data before processing: if selected, identical patterns are aggregated and considered as a single pattern during the training phase.
Append results: if selected, the results of this computation are appended to the dataset, otherwise they replace the results of previous computations.
Set value for constant term: users can enter a value, which will be used to compute coefficients.
Value for constant term: if the Set value for constant term checkbox has been selected, users can set a value for the constant term which will be used to compute the coefficient.
The Coefficients tab¶
This tab gives users a visual representation in a spreadsheet format of the coefficients generated by the analysis.
The Results tab¶
Within this tab, users can visualize a summary of the computation.
This tab is divided into two panes:
General Info
Within this pane, users can find the following information:
Task Label
Elapsed time
Result Quantities
Within this pane, users can visualize the following options:
None
Maximum coefficient (absolute value)
Number of input attributes
Number of samples
This checkbox is checked by default.
Example¶
This example uses the Adult dataset.
After having imported the dataset, split the dataset into test and training sets (add 30% test and 70% training) with the Split Data task.
Add a Linear task, and define the following attributes:
drag the hours-per-week attribute onto the output attributes drop area.
drag all the other attributes - except for income - onto the input attributes drop area.
Save and compute the Linear task.
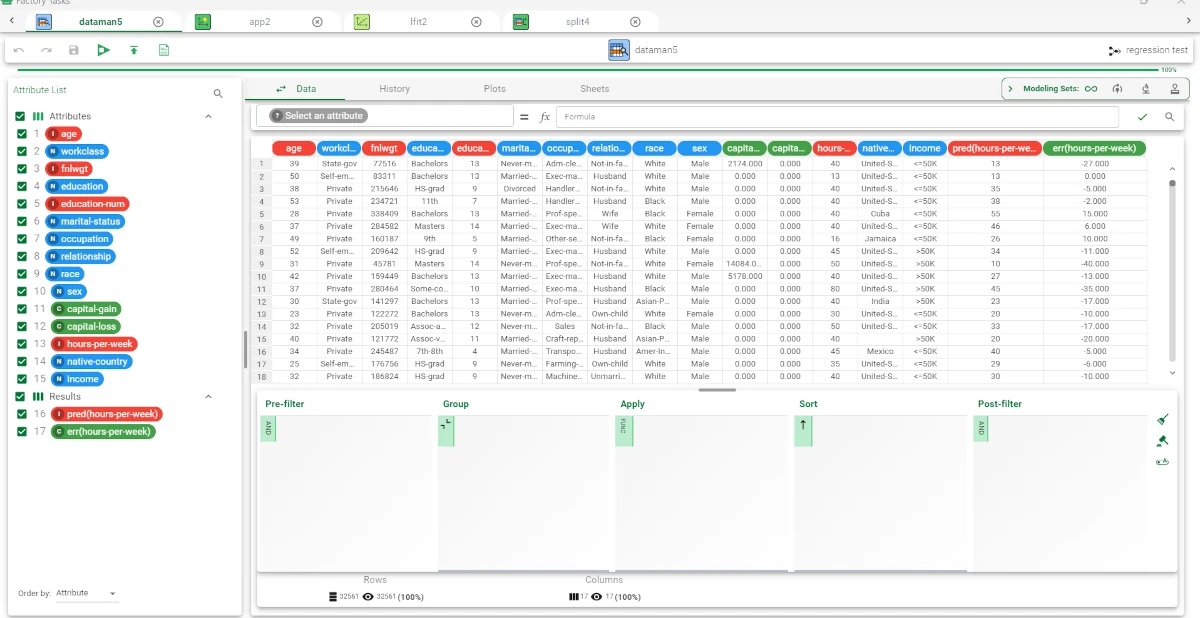
Add an Apply Model task to visualize the results.
Add a Data Manger task to the flow to visualize and check how the model built has been applied to the dataset.
Two more columns have been added by the Apply Model task:
The pred(hours-per-week) column contains the output forecast.
The err(hours-per-week) column contains the error.