Rule Engine¶
Warning
This task is only available on specific request. Contact us for specific pricing.
The Rule Engine task can be used to apply validation rules to data, and it can be set so that it highlights anomalies or generates new columns.
The validation rules can be provided through a configuration file.
The Options tab¶
Once the Rule Engine task has been dragged onto the stage, it must receive two inputs:
the values to be verified
The task has a simple interface, made of only one tab, that is the Options tab.
The following configuration options are available:
Rule imported from task: specify the task containing the rules.
Data imported from task: specify the task containing the values which will be validated by the rules.
- Output format: select how the rule output will be displayed. Possible values are:
Wide: the output is shown with additional attributes, specified in the Attribute column of the configuration file.
Long: one row is shown for each verified rule for each entry on data.
Long compact: one row is shown for each verified rule for each entry on data, but entries which don’t verify any rule will not be shown.
Missing policy: choose from the drop-down list if the rules involving attributes with missing values should satisfy the rules or not.
Missing values always satisfy conditions
Missing values never satisfy conditions
Add columns for identify the most important rule: if selected, columns to identify the most important rule are added to the output file.
Add all verified rules (only when score is present): if selected, and only when the score is present, additional columns are displayed in the output dataset.
The configuration file¶
The configuration file must follow a strict configuration: it can have any format, (the most commonly used is MS Excel) but it can contain the following columns:
Attribute: the attribute which will be filled with the output of the rule on the corresponding row.
Rule: contains the rule written using the correct syntax. More information on it can be found in the paragraph below.
Priority (optional): defines when each rule is applied. If present, it must include integer values.
Description (optional): describes what the rule is checking.
Score (optional): the score associated to the rule. It must be a positive (>=0) integer or continuous value. If it is present, all the rules are evaluated for each row, each output value will have a score, and the value with the highest score will be displayed in the output file. All the outputs will be cast to nominal type.
Attention
If the Rule attribute contains formulas with a vectorial output, the rule’s Score value must be either 0 or missing.
Rule syntax
Rules written in the Rule column of the configuration file must follow specific constraints.
An example of how a rule is written in the configuration file can be:
when $"Age" >= 15 if $"City" in ['Washington'] then 'Football' else 'Baseball'
Users must follow the rules below to insert text strings, attribute names and so on in rules:
The rule must be built following the order: when cond1 if cond2 then value if the conditions are verified else value if the conditions aren’t satisfied.
The
whenkeyword introduces the first condition, which works as a filter. It is possible to use all the Data Manager conditions. If it is present in the rule, it must be placed at the beginning of it.The only format with which the rule can be written is if+then+else.
Only one rule is supported in each row.
Attributes must be written using the following format
$"attribute_name".Strings must be written enclosed in
' 'or" ".List of values in conditions or values after word operators must be written enclosed in square brackets.
Missing values must be written
"".Conditions can contain all the Data Manager’s functions.
The rules’ syntax follows GOLD language rules. To know more about GOLD, go to the corresponding page.
The output file¶
Depending on the chosen Output format, the task provides a proper dataset.
In any of the output formats, combined with the Add columns for identify the most important rule and the Add all verified rules (only when score is present) options, the following columns will be found:
Row_ID: the ID of the row in the source dataset.
In the following paragraphs, the output file structure is explained. In any of the formats all the attributes coming from the starting dataset are included.
Wide format
If the Wide format has been chosen as the output format, the following attributes are added to the output table:
output_name: for each output specified in the rules, a column is added, containing the predictions established by the rules.
If the Add columns for identify the most important rule option has been selected, for each output the following columns are added:
rule / rule(output_attribute_name): the rule index in the configuration file. (when the Score attribute is present or is not present in the rules configuration file)
desc(output_attribute_name): the description of the corresponding verified rule. (when the Score attribute is present or is not present in the rules configuration file)
priority(output_attribute_name): the priority of the corresponding verified rule. (when the Score attribute is present or is not present in the rules configuration file)
nrule(output_attribute_name): the number of rules satisfied by the row. (only when the Score attribute is present in the rules configuration file)
conf(output_attribute_name): the confidence on the result, included between 0 and 1, which is the normalized difference between the first two highest scores. The higher the value, the higher the confidence. (only when the Score attribute is present in the rules configuration file)
If the Add all verified rules (only when score is present) option has been selected in the task, the columns above, are replicated for each verified rule and the attributes’ names will contain an indexing suffix.
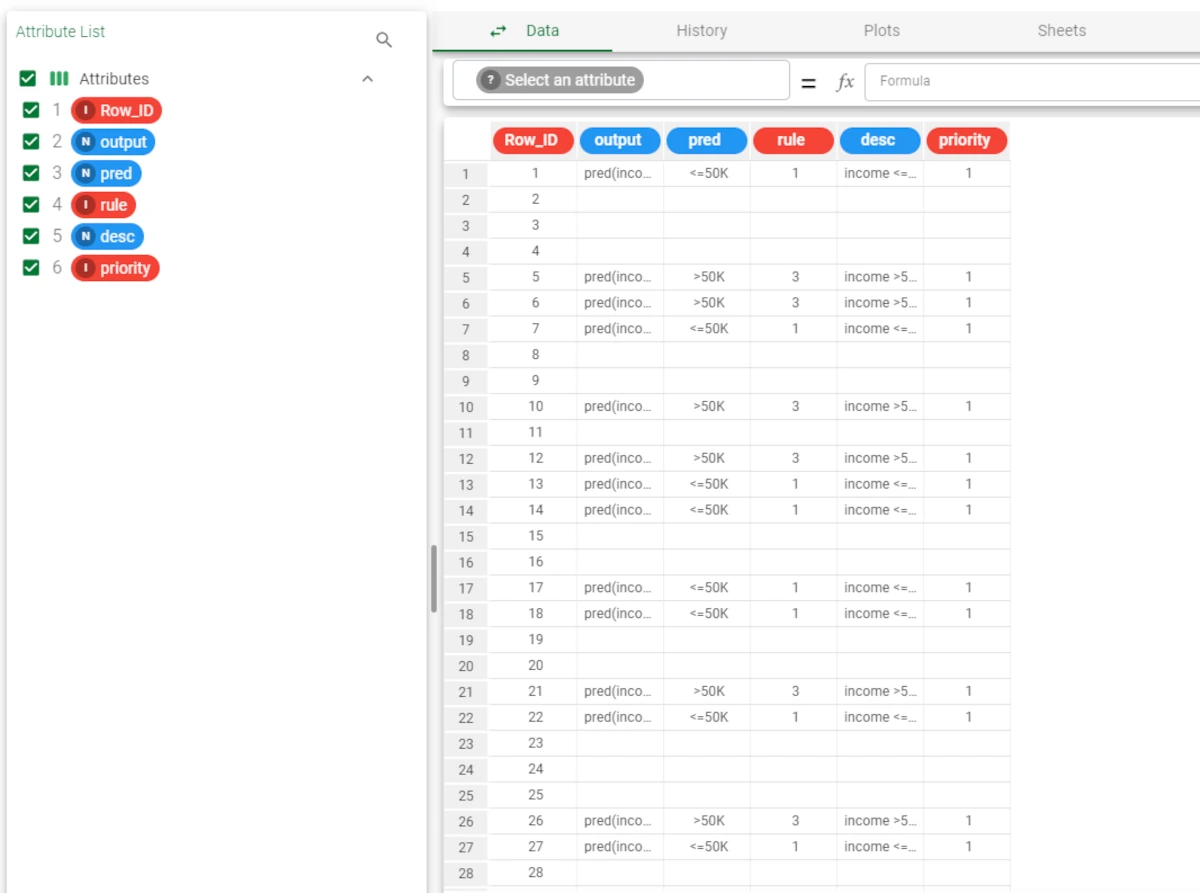
Long formats
If the Long or Long compact format have been chosen as the output format, the following attributes are added to the output file:
output: the attribute name to which the value specified the pred columns refers to.
pred : the output value of the corresponding rule.
If the Add columns for identify the most important rule option has been selected, the following columns are added:
rule: the rule index in the configuration file. (when the Score attribute is present or is not present in the rules configuration file)
desc: the description of the corresponding verified rule. (when the Score attribute is present or is not present in the rules configuration file)
priority: the priority of the corresponding verified rule. (when the Score attribute is present or is not present in the rules configuration file)
nrule: the number of rules satisfied by the row. (only when the Score attribute is present in the rules configuration file)
conf: the confidence on the result, included between 0 and 1, which is the normalized difference between the first two highest scores. The higher the value, the higher the confidence. (only when the Score attribute is present in the rules configuration file)
If the Add all verified rules (only when score is present) option has been selected in the task, the columns below are added:
pred-list: the output value of the corresponding rule in the corresponding row in the output table. (only when the Score attribute is present in the rules configuration file)
conf-list: the confidence value of the corresponding rule in the corresponding row in the output table. (only when the Score attribute is present in the rules configuration file)
rule-list: the index of the rule applied in the corresponding row located in the Row_ID. (only when the Score attribute is present in the rules configuration file)
desc-list: the description of the rule applied in the corresponding row. (only when the Score attribute is present in the rules configuration file)
priority-list: the priority of the rule applied in the corresponding row. (only when the Score attribute is present in the rules configuration file)
Example¶
Examples on Rule Engine have been divided into two parts: the first section refers to rules with scoring, while the second one refers to rules without scoring.
Scoring
The following example uses the Adult and the Rules datasets.
Import both the rule configuration file and the dataset into the flow by using two import tasks. The configuration file has been filled according to the rules listed above.
Add a Rule Engine task to the flow, and link the two source files to it. Then, double-click the Rule Engine task to open it.
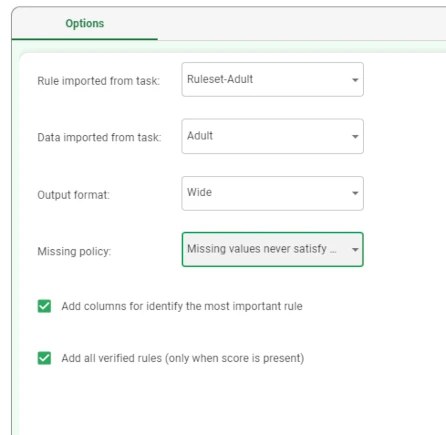
Configure the Rule Engine task as follows:
Rule imported from task: Ruleset-Adult
Data imported from task: Adult
Output format: Wide
Missing policy: Missing values never satisfy conditions
Select both the Add columns for identify the most important rule and the Add all verified rules (only when score is present) options.
Save and compute the task.
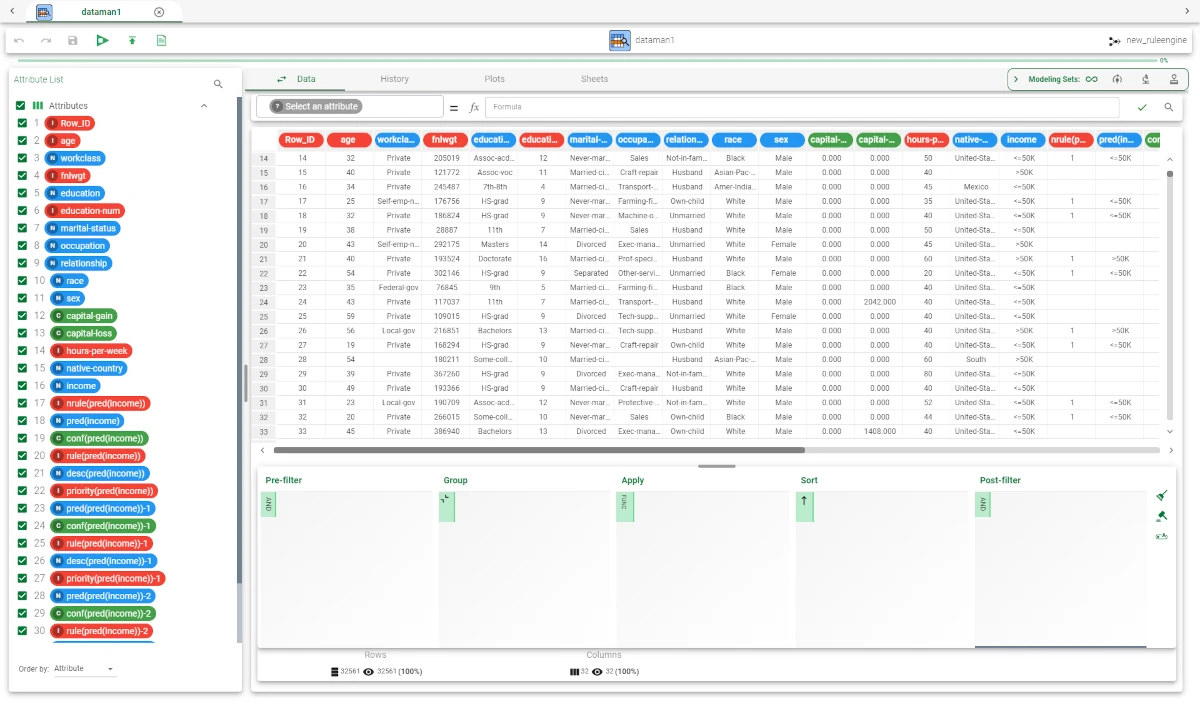
Add a Data Manager task to the flow, then link it to the computed Rule Engine task. Alternatively, right-click on the Rule Engine task and select Take a look.
As the checkbox Add columns for identify the most important rule has been selected, the columns Row_ID, pred(income), nrule(pred(income)), rule(pred(income)), desc(pred(income)), priority(pred(income)) have been added.
As the checkbox Add all verified rules (only when score is present) has been selected, the columns mentioned above have been replicated for each verified rule.
Without scoring
The following example uses the Adult and the Rules no scoring datasets.
Import both the rule configuration file and the dataset into the flow by using two import tasks. The configuration file has been filled according to the rules listed above.
Add a Rule Engine task to the flow, and link the two source files to it. Then, double-click the Rule Engine task to open it.
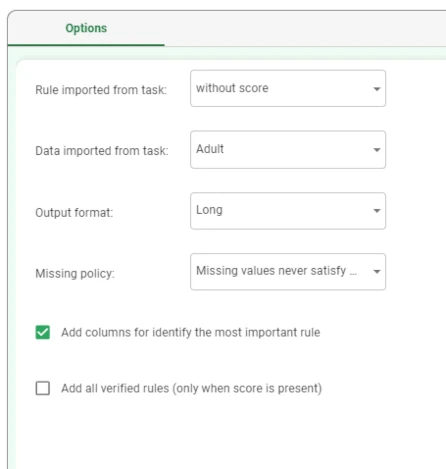
Configure the Rule Engine task as follows:
Rule imported from task: without score
Data imported from task: Adult
Output format: Long
Missing policy: Missing values never satisfy conditions
Select the Add columns for identify the most important rule option.
Save and compute the task.
Add a Data Manager task to the flow, then link it to the computed Rule Engine task. Alternatively, right-click on the Rule Engine task and select Take a look.
As the score is not present in the rules configuration file and the Add columns for identify the most important rule option has been selected, the Row_ID, output, pred, rule, desc, priority columns have been added to the dataset, along with additional rows to display each rule.