Assortment Optimizer¶
Rulex extracts and generates replacement rules from frequent itemsets via the Assortment Optimizer task. The task provides a list of replacement rules, which can be used to understand how to replace items with equivalent items to the best advantage. These rules, denoted as (A):B (i.e. item A replaced by item B), are qualified by different scores, according to available data, such as the cost of items.
A typical use case for this task could be when retailers need to reduce the inventory in specific categories of products, removing some products while minimizing loss of revenue. Rulex enables them to optimize assortment without losing customers, taking into account that clients may switch (together with all their purchases) to competitors if one of their favorite items is removed and it is not replaced by an equivalent product, thanks to replacement rules.
Warning
A Frequent Itemsets Mining task task must have generated a set of frequent itemsets as input for the Assortment Optimizer task.
The task is divided into three tabs:
the Options tab
the Results tab
The Options tab¶
The Options tab contains all the task’s features that can be customized to obtain the desired output.
The following configuration options are provided:
Maximum replaced item support #: the maximum number of occurrences in the dataset for items selected for replacement. If this value is set to 0, all items are considered as selected for replacement.
Minimum replacing item support #: the minimum number of occurrences in the dataset for items selected to replace other items.
Category attribute: select the attribute which represents the category to which item belongs from the drop-down list. It is then possible to look for potential replacement items only within the same category as the item you are replacing. This improves accuracy, together with computational efficiency.
Item price attribute: select the attribute which represents the price of each item from the drop-down list. It specified, it is then possible to calculate the Minimum revenue replacement score.
Item cost attribute: select the attribute which represents the production cost of each item from the drop-down list. If specified, it is then possible to calculate the Minimum margin replacement score.
Items to replace: drag the attribute containing the rows to be considered during the analysis, even though they have been excluded while setting the range. Rules to replace items satisfying this criterion are not discarded, regardless of the Maximum replaced item support # threshold. To know more about attribute filters go to the corresponding page.
- Minimum alternativeness coefficient: the degree of alternativeness between the purchase of two items:
1 (max) if they are never sold together
0 (min) if one item is always sold with the other one.
If a pair of items ensures the Minimum alternativeness coefficient, the corresponding replacement rule is discarded.
Minimum volume replacement score %: the minimum percentage of orders in which a replaced item is expected to be replaceable by the replacing item. If this minimum threshold is not satisfied by a replacement rule, it is discarded.
Minimum revenue replacement score %: the minimum percentage of revenue guaranteed by replaced item, which the replacing item is expected to obtain. If this minimum threshold is not satisfied by a replacement rule, it is discarded.
Minimum margin replacement score %: the minimum percentage of gain guaranteed by the replaced item, which the replacing item is are expected to obtain. If this minimum threshold is not overcome by a replacement rule, it is discarded.
The Replacement rules tab¶
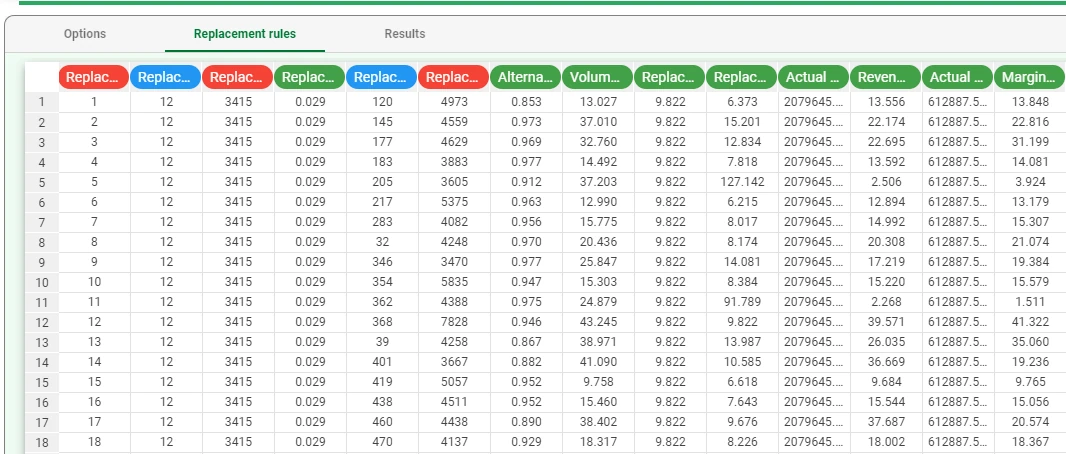
The Replacement rules tab displays the generated itemsets, displayed in a spreadsheet format.
The following attributes are shown in the spreadsheet:
Replacement rule ID: the sequential ID number for replacement rules.
Replaced item ID: identifier of items selected to be replaced.
Replaced item support #: the number of occurrences in the dataset for items selected to be replaced.
Replaced item loneliness %: percentage of transactions constituted only by the replaced item, with respect to all the transactions involving it.
Replacing item ID: identifiers of replacing items.
Replacing item support #: number of occurrences in the dataset for replacing items.
Alternativeness coefficient: alternativeness between the purchase of the replaced and the replacing items.
Volume replacement score %: percentage of orders in which the replaced item is expected to be replaceable by replacing item.
Replaced item revenue pulling factor: ratio between revenues guaranteed by orders involving the replaced items and revenues guaranteed by the replaced items themselves.
Replacing item revenue pulling factor: ratio between revenues guaranteed by orders involving the replacing items and revenues guaranteed by the replacing items themselves.
Actual total revenue related to replaced item: whole revenue guaranteed by orders involving the replaced items.
Revenue replacement score %: percentage of revenue guaranteed by the replaced item, which the replacing item is expected to obtain.
Actual total margin related to replaced item: whole margin guaranteed by orders involving the replaced items.
Margin replacement score %: percentage of revenue guaranteed by replaced item, which the replacing item is expected to obtain.
The Results tab¶
The Results tab provides information on the computation. It is divided into two sections:
- The General Info tab, where the following information can be found:
Task Label: the task’s name.
Elapsed time (sec): the time required for latest computation (in seconds).
- The Result Quantities tab contains the data quantities: check the results to be visualized, then open them by clicking on the arrow button to visualize the quantities’ values. The following information is provided:
Number of generated replacement rules: the number of replacement rules generated by the task. This quantity contains the counts of the Replacement.
Example¶
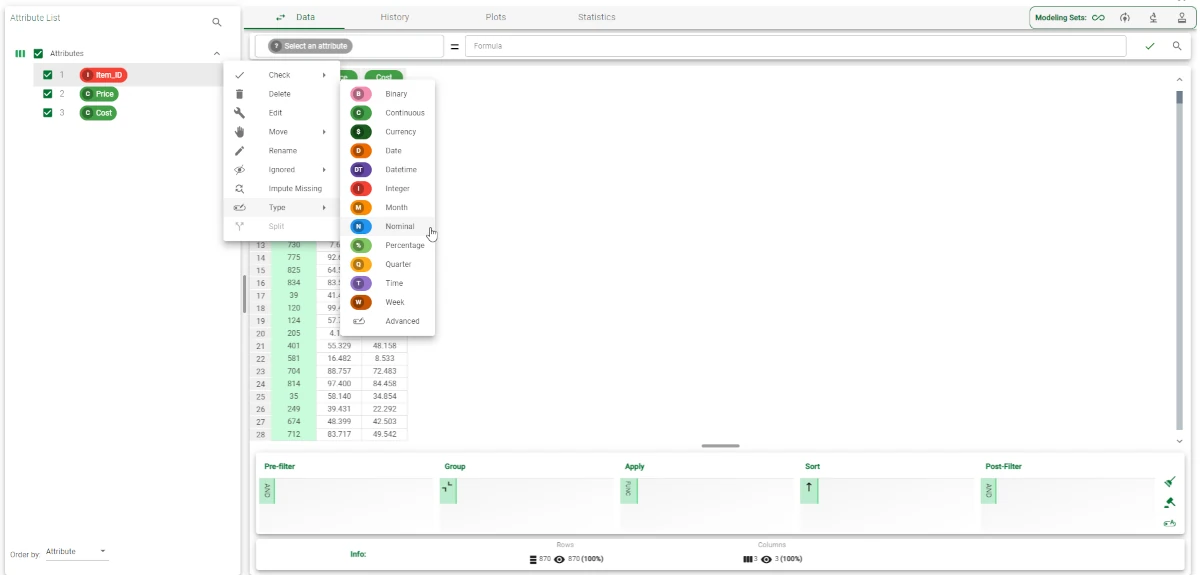
After having imported the dataset with an Import from Text File task, add a Data Manager task and change all the attribute types to nominal (using shift) by right-clicking onto the attribute, then selecting Type>Nominal.

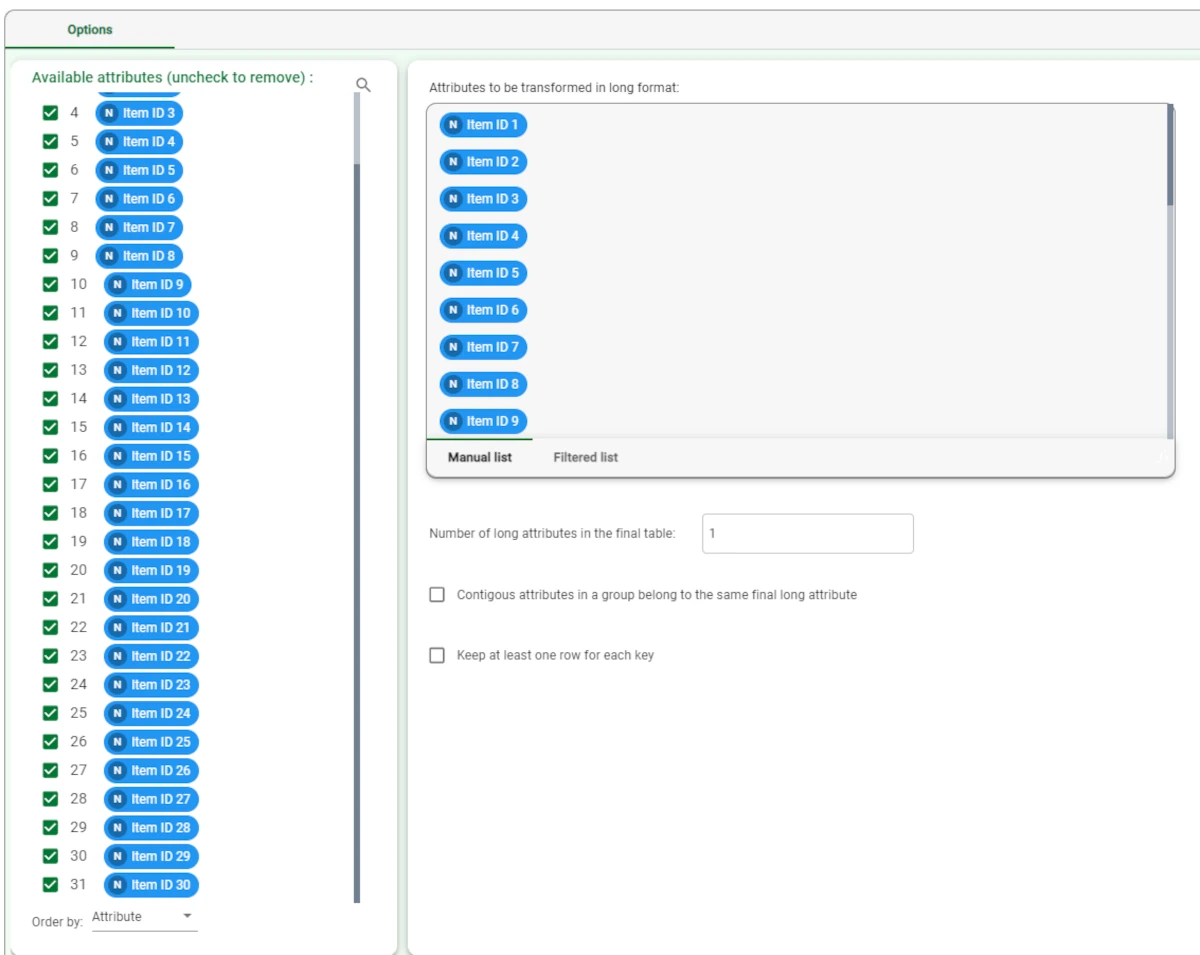
Add a Reshape to Long task to the flow to restructure the data so that the information concerning a purchase of N items is distributed over N rows, each one including a couple Order ID/Item ID.
To do this drag and drop all the Item_ID xx attributes onto the Attributes to be transformed in long format edit box, then save and compute the task.
We then import the hba-test-prices-costs dataset with an Import from Text File task, and add another Data Manager to set the Item_ID attribute to Nominal.
The data type of the price and cost attributes must remain continuous.
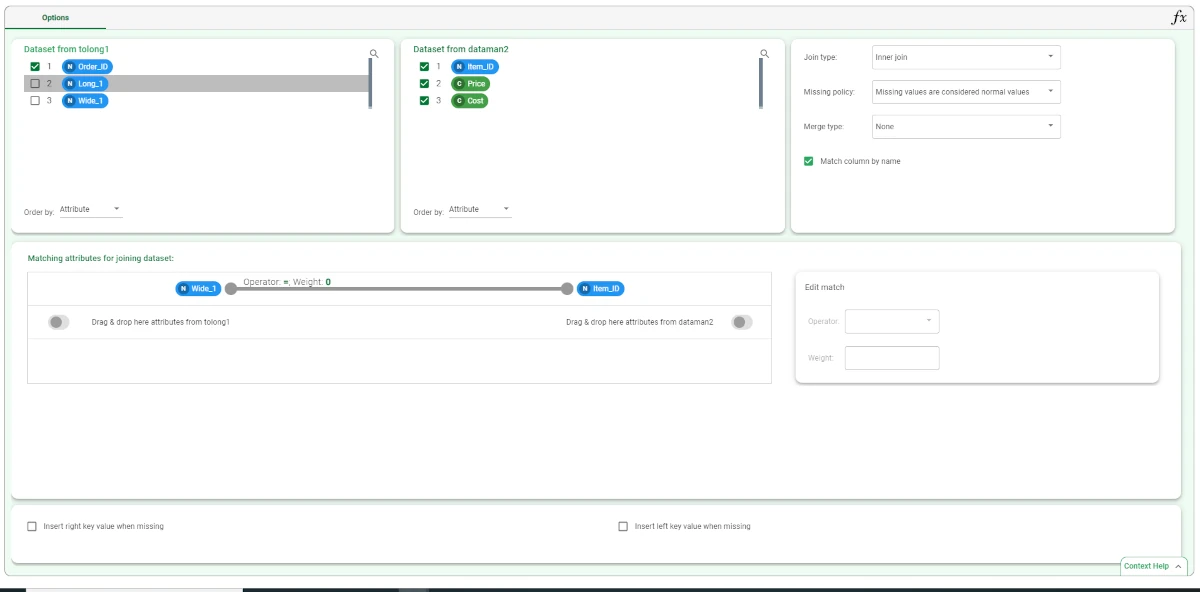
- We then add a Join task to the flow to merge this new dataset with the hba-test dataset, and configure it as follows:
select the Order_ID attribute in the ReshapeToLong task output.
select all the attributes in the hba-test-prices-costs dataset.
match the Wide_1 attribute from the ReshapeToLong task output with the Item_ID column in the hba-test-prices-costs dataset.
uncheck the Long_1 attribute.
uncheck the Wide_1 attribute or the Item_ID attribute.
Save and compute the task.
- We then add a Frequent Itemsets Mining task, and configure it as follows:
set the Order_Id as Order key attribute.
set Item_ID as the Item child attribute.
set Maximum itemset cardinality to 3.
select the Auto (specify #items) checkbox.
set # Items to consider to 50.
Save and compute the task.
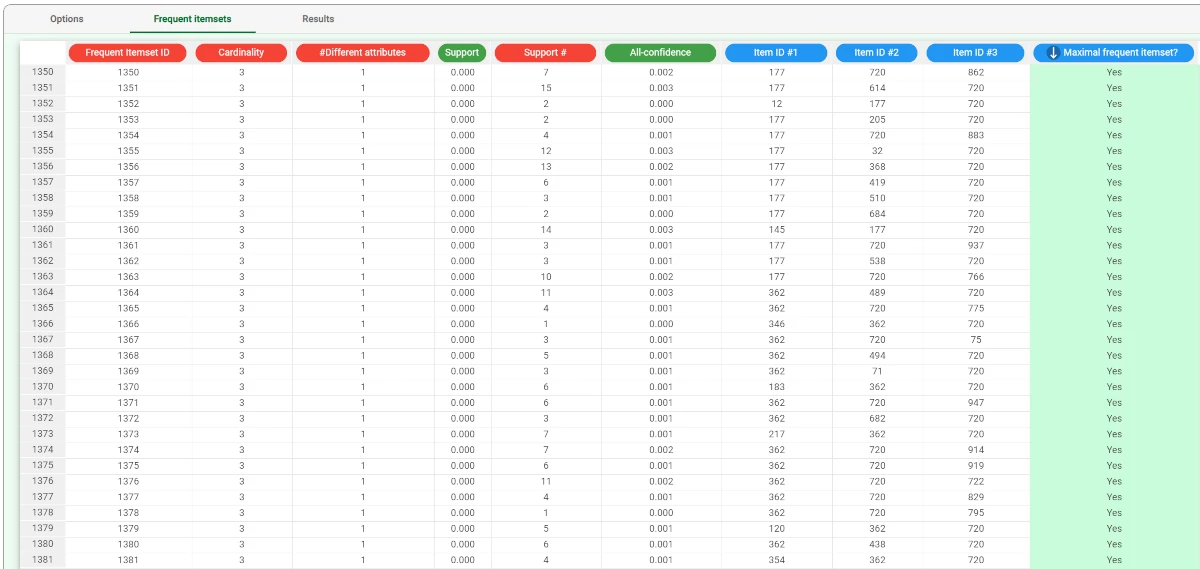
The identified frequent itemsets are displayed in the corresponding tab.
We now add an Assortment Optimizer task, and select the Price attribute as the Item price attribute and the Cost attribute as the Item cost attribute.
Save and compute the task
The results can be visualized by clicking on the Replacement rules tab.