Executing queries¶
One of the key properties of the Data Manager task is the possibility to execute SQL-like queries on the underlying dataset through simple drag and drop operations.
All these operations are performed in the query panel. General overview about this pane has been given in the data tab page.
Here we are going to concentrate on the general approach to query construction and to a more detailed description of the five areas of the query panel.
Follow the procedure below to execute SQL-like queries:
Procedure
Select a list of attributes from the Attribute list.
Drag the selected attributes onto one of the five areas of the query panel. Attributes are going to be displayed in the selected area.
If Autocommit is enabled, the query will be automatically executed; otherwise you have to click the Play button to execute it.
Click Clear to reset the query or Make persistent to permanently apply it, by cutting off all the not displayed lines and by re-ordering the whole dataset.
Once query is executed, the total number of displayed rows may differ, as well as their order.
Take into account that any of the presented operations can be undone and redone at any moment.
Filter query¶
In Pre-filter and Post-filter areas, the user is able to construct complex rules to filter the Data Manager underlying dataset.
Note
The only difference between these two areas is the computation order. While, properties and interactions are the same.
When an attribute is dragged from the Attribute list, and it is dropped in one of these areas, a new line is created next to the dropped position. When hovering onto the attribute, the background color changes highlighting the point of the new created condition.
Each line contains a single attribute, indicated by the attribute chip and contains a single condition.
Tip
When hovering with the mouse on an attribute chip, a tooltip containing the code of the underlying condition, if any, is shown.
Conditions can be combined using AND / OR logical operators to construct more complicated rules.
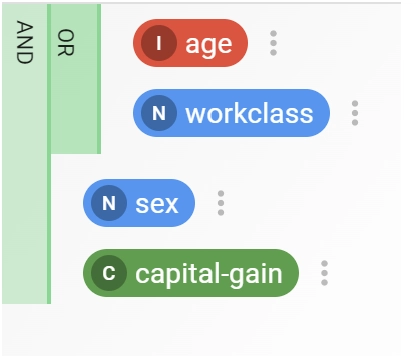
Filter condition nesting¶
To perform even more complicated nested constraints, condition lines are organized in nested levels, as in figure Filter condition nesting. Each level contains a set of conditions linked together by an AND or OR operator. The type of operator connecting a single level is presented at the left-side of the block itself (see figure Filter condition nesting).
Note
To change the type of operator of a single level, you can click on it. At any click, it switches between the AND, and the OR operators.
Once a single new attribute is dropped, a condition panel will appear on the screen. In this panel the user can configure all the properties of the single condition. Once defined the condition, the user can confirm its addition to the constraint tree.
Condition panels¶
The graphical structure of the condition panel changes according to the attribute data type:
For time attributes.
Conditions already created on the tree can be selected by clicking on any point of their connection line. A green background will highlight the lines effectively selected.
Tip
By pressing Del key with an active selection, you can delete in bulk all the selected condition lines.
Group query¶
When a list of attributes is dragged from the Attribute list, and it is dropped in the Group area, the same list of attribute chips will be shown inside the Group area performing a group operation on the underlying dataset.
By dropping a list of n attributes onto the Group area, Rulex Factory performs an operation which mimics the behavior of the SQL GROUP clause: it retains, as displayed, a single row for any occurrence of distinct n-tuple of values coming from the considered columns.
Note
Differently from SQL GROUP clause, anything is applied directly on the dataset. Rulex Factory Group operation performs a filtering operation reducing only the number of displayed rows and modifying the ordering to group together same value rows.
Since any formula operation only applies to the displayed set of rows, there are situations where the user may need to expand the group operation to show all the lines simply reordered to manage the grouping definition. In these situations you can click on the left sidebar of the Group area to change the Expand mode:
 Expanded mode: only the first row of each group is displayed.
Expanded mode: only the first row of each group is displayed. Contracted mode: all the lines are displayed in groups.
Contracted mode: all the lines are displayed in groups.
By right-clicking on any attribute populating the Group area, you will open the following context menu:
Disable: it disables all the selected attributes which are going to appear greyed out in the Group area. This could be useful to study some what-if scenario.
Delete: it removes all the selected attributes from the Group area.
Tip
By pressing the Del key with an active selection, you are going to delete in a bulk operation all the attributes.
Apply query¶
When an attribute is dropped onto the Apply area, a new line is added to the list already present.
Rulex Factory Apply operation applies an aggregator function to the selected column, by taking automatically into account eventual grouping mechanism or row filtering.
Once the attribute is dropped onto the Apply area, a dedicated panel will appear to allow the user to select the proper aggregator function.
Note
Available function differs according to the attribute type.
For nominal and binary attributes, they are:
For integer, continuous, percentage and currency attributes, they are:
For date, week, month, quarter, time and datetime attributes, they are:
The aggregator function chosen is displayed with an acronym on the left side of the attribute line. By clicking on it, the same panel is re-opened to enable the user to modify it once the attribute line has already been created.
Tip
By pressing the Del key with an active selection, you are going to delete in a bulk operation all the attributes.
If you are right-clicking on any attribute populating the Apply area, you will open the following context menu:
Open: it opens the aggregator function panel.
Disable: it disables all the selected attributes which are going to appear greyed out in the Apply area. This could be useful to study some what-if scenario.
Delete: it removes all the selected attributes from the Apply area.
Sort query¶
When a list of attributes is dragged from the Attribute list, and it is dropped into the Sort area, the same list of attribute chips will be shown inside the Sort area performing a sort operation on the underlying dataset.
By dropping a list of n attributes onto the Sort area, Rulex Factory performs a sort operation on the whole dataset: the dataset is ordered according to the first attribute, then it orders the same value ranges according to the second attribute and so on.
For any sort operation you are free to decide the sorting order (descending or ascending). The order is then displayed on the left side of each attribute line:
 Ascending
Ascending Descending
Descending
By clicking on these icons in the Sort area, you can invert the sorting order for one specific attribute.
Tip
By pressing the Del key with an active selection, you are going to delete in a bulk operation all the attributes.
If you are right-clicking on any attribute populating the Sort area, you will open the following context menu:
Sort ascending: it changes the sorting order of all the selected attributes to ascending.
Sort descending: it changes the sorting order of all the selected attributes to descending.
Disable: it disables all the selected attributes which are going to appear greyed out in the Sort area. This could be useful to study some what-if scenario.
Delete: it removes all the selected attributes from the Sort area.
Note
You can immediately understand which attributes are sorted even by looking at header row in the main spreadsheet. A sort icon will be shown at the right end of any header chip of a sorted attribute.