Concatenate¶
The Concatenate task in Rulex merges datasets by their columns, creating a single table with all the data.
There is no limit on the number of datasets you can concatenate.
If your tables contain different subsets of a set of records, you should concatenate your tables by their columns.
For example, table 1 may contain full details on clients whose names begin with A > M, while table 2 contains full details from N > Z. The resulting merged table would contain information on all clients from A >Z.
The Concatenate task has an essential interface, made of the Options tab only.
The Options tab¶
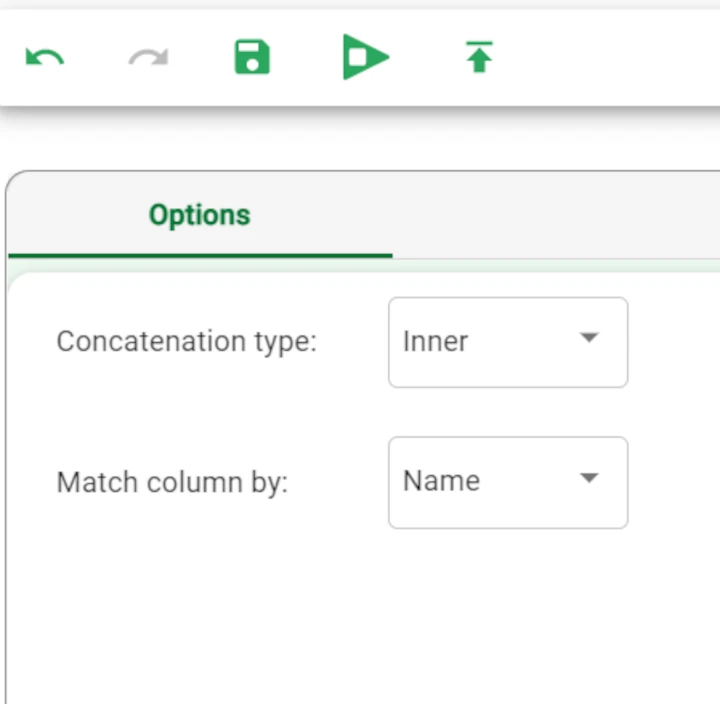
The Options tab contains all the settings available to customize the datasets’ concatenation. It has two drop-down lists:
- The Concatenation type: choose the concatenation type you want to use. The possible values are:
Inner: only attributes existing in both tables are included in the final merged table.
Outer: all attributes are copied, filling in any missing values if necessary. This is the default value.
- The Match column by: choose how the columns will be matched. The possible values are:
Position: all attributes in the same position are considered equal.
Name: attributes with the same name are considered equal. This is the default value.
Example¶
The following example uses the Northwind orders and the Northwind orders 1 datasets.
In the example here, after having imported the datasets, drag the Concatenate task onto the stage and link it to the datasets.
The first dataset contains 830 rows, while the second one 415. Double-click the task to open it.
Select inner concatenation, matching the attributes by name. Then, save and compute the task.
Right-click on the task to see the results and select the Take a look entry: there are 1245 rows in the dataset now, that correspond to the sum of the two previous datasets, that is 830+415.
