Import from PDF File¶
The Import from PDF File allows users to import data stored in a PDF file.
The Import from PDF File task is divided into two tabs:
the Options tab
The Options tab¶
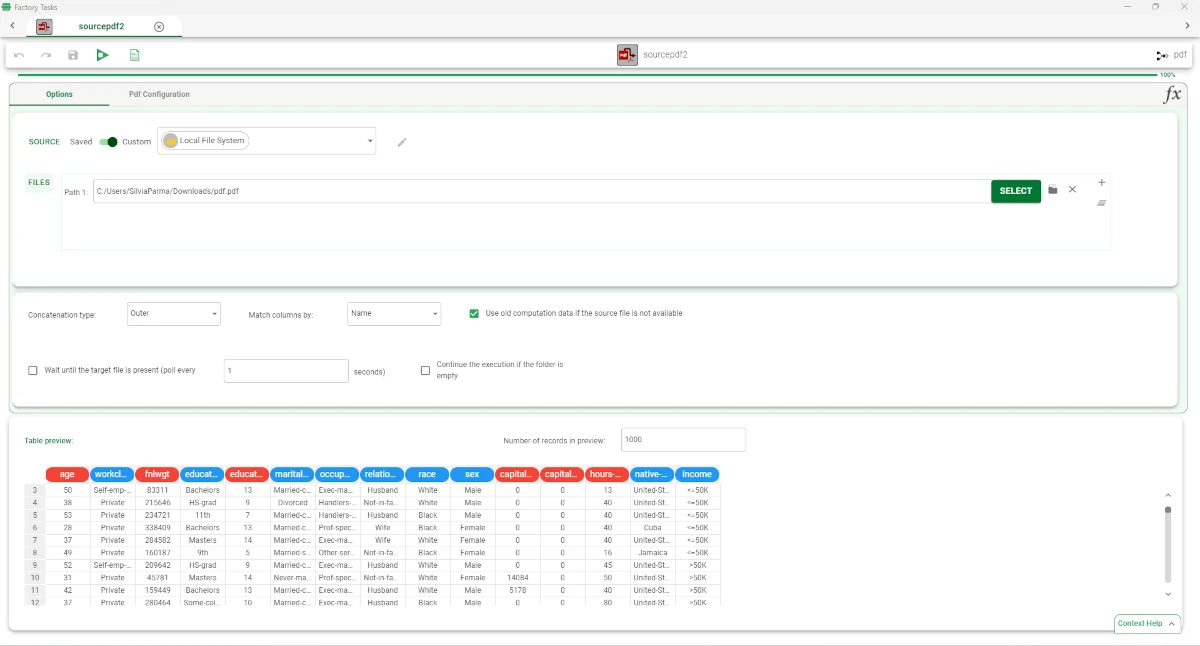
The Options tab follows the structure shown in the Import Overview page.
The PDF Configuration tab¶
The PDF Configuration tab is divided into three panes:
Parsing options: users can find the parsing options.
Import options: users can find the import options.
Table preview: users can visualize a preview of their imported tables.
Parsing options
Within this pane, users can transform the chosen data into a more readable format.
The following options are available:
Data separators: it delimits the values of the data to be imported. Users can select one of the following options:
TABBING
COMMA
SEMICOLON
SPACE
Other
Number separators: users can define symbols to mark thousands and decimals in numbers. You can select the symbols from the Thousands and Decimals drop-down lists.
Missing string: enter the string you want to remove from the dataset.
Text delimiter: users can select ‘ or “ if these symbols have been used as string delimiters. They will not be included in the imported file. For example, the string “apartment” will be imported as apartment. This option will remove all instances of text delimiters in the string, and not only the initial and closing symbols. The only exception to this rule will be if the symbol is proceeded by a backslash. For example, “ad”cb” will be imported as ad”cb, while “ad”cb” will be imported as adcb. The data type for values with string delimiters is nominal, and this data type will not be altered by the removal of text delimiters. For example, “3” will be imported as 3, but will remain a nominal value, instead of being converted to an integer.
Use contiguous separators as a single one: if selected, it forces the parser to consider any possible group of adjacent separators as one. For example, if you select this option, the string ‘1,2,,,3’, with the comma as a separator, it’ll be parsed as 1, 2, 3. If not checked it will be parsed as 1, 2, ‘’, ‘’, 3.
Import Options
Within this pane, users will find the following options:
Start importing from line: the number of the line from which the importing operations will start.
Stop importing at line: the number of the line where the importing operations will end. Leave the value 0 if you want the whole dataset to be imported.
Get names from line: the number of the line from which the names of the columns will be taken.
Get types from line: the number of the line from which the data types will be taken.
Column to be imported (empty for all): the number of columns to be imported. If left empty, all the columns will be imported.
Remove empty rows: if selected, it removes the empty rows from the imported dataset.
Add an attribute containing filename: if selected, it adds an extra column with the name of the file to the dataset.
Strip spaces: if selected, it removes the empty columns from the imported dataset. For example, the string “ class “ will be imported as “class”.
Force number of columns: the number of columns which must be created upon importing, as the PDF file might not have been correctly formatted.
Remove empty columns: if selected,it removes the empty columns from the imported dataset.
Case sensitive: if selected, upper cases are considered different from lower cases.
Compress white spaces: if selected, it compresses contiguous occurrences of white spaces in one single occurrence. For example the string “university program” would be imported as “university program”.
Turn off smart type recognition: if selected, prevents automatic recognition of data types, leaving the generic nominal type. This option is useful when manual identification is preferable, for example when there is the risk of a code being misinterpreted as a date.
Example¶
Drag and drop an Import from PDF File task onto the stage.
Double-click the task to open it.
Select Custom from the Source slider.
Leave the default Local File System value.
Click Select to browse to the file you want to import.
Save and compute the task.
Check the imported table in the Table preview pane.