Logistic¶
The Logistic task solves classification problems according to the logistic regression approach, i.e. by approximating the probabilities associated with the different classes through a logistic function:
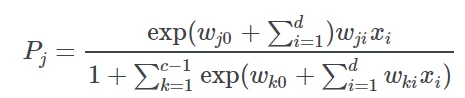
where
c is the number of output classes
j is the index of the class, ranging from 1 to c−1,
d is the number of inputs and
𝓌ji is the weight for class j and input i.
The probability for the c -th class is obtained as
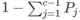
The optimal weight matrix 𝓌ji is retrieved by means of a Maximum Likelihood Estimation (MLE) approach that makes use of the Newton-Raphson procedure to find the minimum of the log-like function.
The output of the task is the weights matrix 𝓌ji, which can be employed by an Apply Model task to perform the Logistic forecast on a set of examples.
The task is divided into three tabs:
The Options tab¶
The Options tab contains all the options you can customize to perform the analysis.
It is divided into three main sections:
The Available attributes section, where you will find the dataset’s attributes, which can be dragged onto the attribute drop area. More information on the attribute list can be found at the corresponding page.
The attribute drop area, where you can drag the attributes. Instead of manually dragging and dropping attributes onto the Input attributes area, they can be defined via a filtered list.
- The last panel contains the customization options available:
Normalization for input attributes: the type of normalization to use when treating ordered (discrete or continuous) variables. Possible methods are:
None: no normalization is performed (default)
Normal: data are normalized according to the Gaussian distribution, where μ is the average of x and σ is its standard deviation.
Minmax [0,1]: data are normalized to be comprised in the range [0,1].
Minmax [-1, 1]: data are normalized to be included in the range [-1, 1]. Every attribute can have its own value for this option, which can be set in the Data Manager task. These choices are preserved if Attribute is selected in the Normalization of input variables option; otherwise any selections made here overwrite previous selections made.
Output attribute: select the attribute which will be used to identify the output.
P-value confidence (%): specify the value of the required confidence coefficient.
Weight attribute: if specified, this attribute represents the relevance (weight) of each sample (i.e., of each row).
Regularization parameter: specify the value of the regularization parameter which is added to the diagonal of the matrix.
Initialize random generator with seed: if selected, a seed, which defines the starting point in the sequence, is used during random generation operations. Consequently, using the same seed each time will make each execution reproducible. Otherwise, each execution of the same task (with same options) may produce dissimilar results due to different random numbers being generated in some phases of the process.
Aggregate data before processing: if selected, identical patterns are aggregated and considered as a single pattern during the training phase.
Append results: if selected, the results of this computation are appended to the dataset, otherwise they replace the results of previous computations.
The Coefficients tab¶
The Coefficients tab contains the resulting coefficients from the analysis, displayed in a spreadsheet format.
The coefficients are used to evaluate the conditional probability to belong to a specified class, as the logistic model is usually a binary classification, obtained using a sigmoid function.
In the first column, the Constant term is displayed, representing the value when all the characteristics are null, along with the Coefficient (attname) related to each input attribute, which has been specified in the Options tab.
The generated Coefficient (attname) displays the weight of the specified variable in the model and how much its variation can affect the probability to belong to one class or another.
The Results tab¶
The results tab provides information on the computation. It is divided into two sections:
- In the General info section you will find:
The Task Label, which is the task’s name on the interface.
The Elapsed time, which indicates how long it took to complete the computation
The Number of input attributes
The Maximum coefficient (absolute value)
The Value of the McFadden’s pseudo-R squared
- In the Result Quantities section, you will find:
The Number of samples obtained, divided by the following sets:
Train
Test
Valid
Whole
Example¶
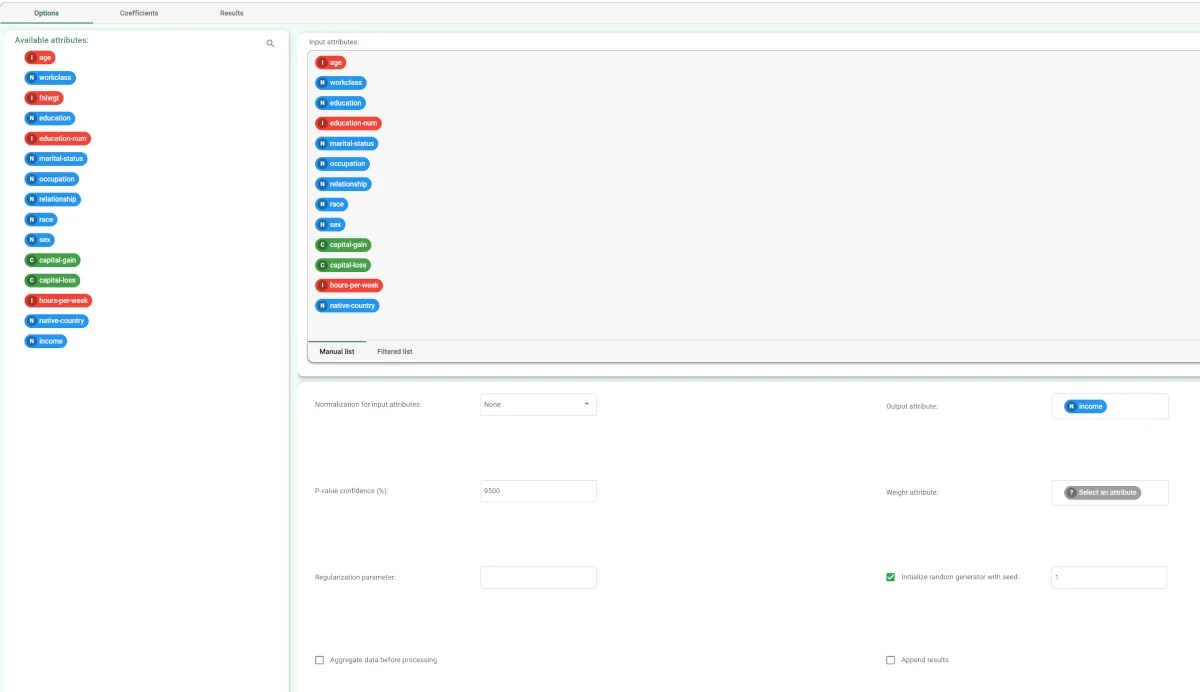
- After having imported the dataset with the Import from Text File task and splitting the dataset into test and training sets (30% test and 70% training) with the Split Data task, add a Logistic task to the flow and configure the following options:
Normalization for input variables: None
Output attribute: Income
Drag and drop all remaining attributes onto the Selected input attributes list.
Leave the remaining options with their default values and compute the task.
Once computation has completed, in the coefficients tab we have a single row containing the coefficients relative to the output class ≤50K.
In a case with c>2 output classes, the weight matrix contains c−1 rows each containing the coefficients relative to an output class.

The Results tab contains a summary of the computation.
Then add an Apply Model task to forecast the output associated with each pattern of the dataset.

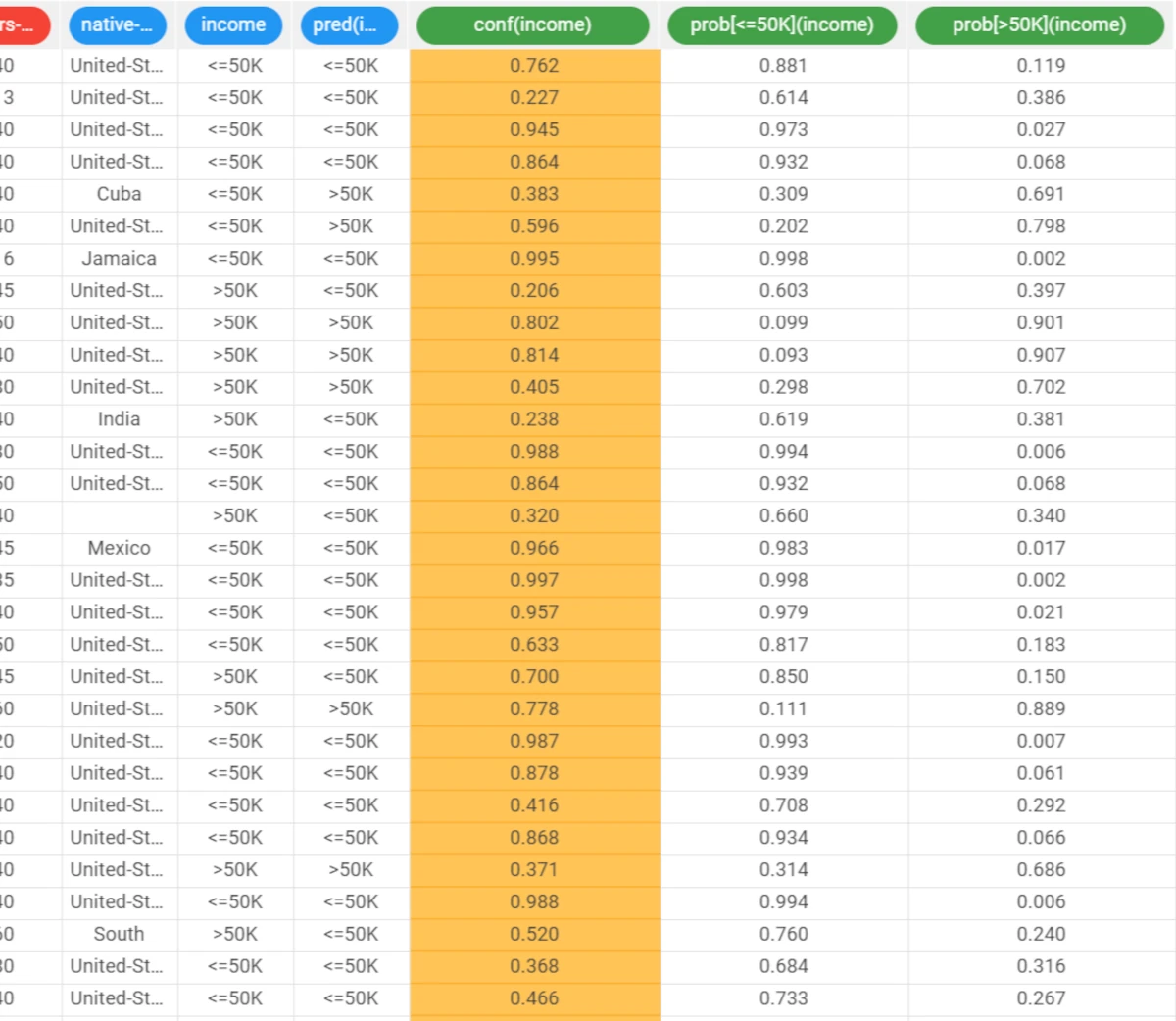
To check how the model built by Logistic model has been applied to our dataset, right-click the Apply Model task and select Take a look.
- Two result columns have been added:
The pred(income) column contains the output forecast generated by the Logistic model.
The err(income) column contains the error, which corresponds to the difference between the predicted output and the real one. If the actual output is missing, this field is also left empty.