Rule Engine¶
Warning
This task is only available on specific request. Contact us for specific pricing.
The Rule Engine task can be used to apply validation rules to data, and it can be set so that it highlights anomalies or generates new columns.
The validation rules can be provided in natural language, by filling a configuration file.
The Configuration File¶
The configuration file must follow a strict configuration: it can have any format, (the most commonly used is MS Excel) and it must contain the following columns:
Warning
The columns’ headers must be the same as the ones listed below, but the column order can be different.
Description (mandatory parameter): describes what the rule is checking.
Cycle: defines when each rule is applied. It must be filled with integer values. It allows to use the outputs of the rules of the first cycle as inputs for the rules in the second cycle. If the column is empty, all the rules will be applied in the first cycle.
Priority: defines the priority of each rule when a record from the dataset to which rules will be applied has more than one match. It must be filled with integer values. The value 1 indicates the highest priority, and it is also the default value when the priority is not specified.
- Status: defines the status of each rule. This parameter can be used by the user to track the rule creation status. The possible values are:
Implemented
Not Implemented
On hold
Only the rules with status set as Implemented are considered in the analysis.
Rule (mandatory parameter): contains the rule written using the correct syntax. More information on it can be found in the paragraph below.
Sheetname: it is not necessary to fill this column, as the task automatically fills it. If the configuration file contains more sheets, it is important that the sheet names are coherent with what they contain.
Rule syntax
Rules written in the Rule column in the configuration file must be written following specific constraints.
A rule is made up of two elements:
Condition: it describes a particular situation.
Output: it is the result of the connected conditions.
Two rule output formats are possible, and the syntax of conditions changes, according to the selected type of output.
The available output formats are:
- Anomaly: in the anomaly rule output, the output of the rule might have three values.
Valid: when the record violates the invalidity condition.
Invalid: when the invalidity condition is satisfied.
Not Applicable: when the admissibility condition isn’t matched. This normally occurs when the ‘WHEN` parameter is inserted in the formula and it isn’t satisfied.
Assignment: the assignment rule output can be either a new attribute, which will be filled with the assignment values, or an existing attribute, whose values will be replaced with the assignment ones, if the condition is satisfied.
See also
The admissibility condition has priority over the conditions, and it must be validated before verifying any other connected conditions. It is basically another layer in the rule, so before verifying that the condition is true or not, it makes sure the admissibility condition is verified, otherwise the entire rule wouldn’t make sense.
Depending on the output of the rule, there are two different types of rule condition syntax:
Anomaly rule syntax:
IF "invalidity condition" WHEN "admissibility condition" THEN 'INVALID'Assignment rule syntax:
IF "condition" WHEN "Assignment attribute" in {'Assignment value'}
Warning
Apart from the rule syntax listed below, it is important to notice that you must follow the rules below to insert text strings, attribute names and so on in rules:
All the attributes must be enclosed in double quotes “attribute_name”.
Every time an attribute is specified in a rule, a blank space must follow the final double quotes.
Values must be enclosed in single quotes, surrounded by curly brackets {‘value’}.
When an empty value must be verified in the conditions, it must be specified as {‘MISS’}.
When checking if a nominal attribute is equal or not equal to certain value(s), the syntax must be in or not in. If this syntax is also used with numeric attributes, the numeric attribute’s type will be cast to nominal.
When checking if a numeric attribute is equal or not equal to certain values(s), the syntax must be written as a formula, using the available operators.
There are different rule types, which will be analyzed in the next paragraphs:
the IF+THEN rule
IF+THEN rule
The first basic rule which can be built is the IF+THEN rule, which is the most basic one: it checks if an attribute has a certain value which classifies a record as invalid. As there is no admissibility condition in this rule, it can’t return a ‘Not Applicable’ output.
An example of an IF+THEN rule can be:
IF "Attribute_Name1" not in {'apartment'} THEN 'INVALID'
IF "Attribute_Name1" not in {'apartment'} THEN "Output" in {'Yes'}.
This means that, in the first rule, if the value ‘apartment’ isn’t found in the attribute “Attribute_Name1”, the Output attribute will be filled with the ‘INVALID’ value. The other values will not be left empty, they will be filled with the ‘VALID’ or ‘NOT APPLICABLE’ values, according to the output characteristics listed above.
In the second rule, if the value apartment isn’t found in the attribute “Attribute_Name1”, the Output attribute will be filled with the ‘Yes’ value. If the condition is not satisfied, the cells in the conditions’ corresponding rows will be left empty.
Hint
Using the output ‘INVALID’ allows filling all the output column with values, while using the format “attribute” in {‘value’}, fills the cells of the columns corresponding to the records which satisfy the rule only. The other values are left empty. This output choice can have an impact while analyzing the results.
IF+WHEN>THEN rule
Rules can also be validated onto a specific subset of data: the WHEN parameter, which must be added to the rule mentioned above.
Basically, the WHEN parameter defines the admissibility condition.
An example of an IF+WHEN>THEN rule can be:
IF "Attribute_Name1" in {'apartment'} WHEN "Location" in {'City'} THEN 'INVALID'
This means that if the value ‘apartment’ is found in the “Attribute_Name1” attribute, and the admissibility condition is satisfied, so the value ‘City’ of the “Location” attribute is present in the record, the output of the rule will be ‘INVALID’.
The output will be ‘VALID’ if the parameter defined in the condition isn’t satisfied.
The output will be ‘NOT APPLICABLE’ if the admissibility condition isn’t satisfied.
IF+AND+WHEN>THEN
When the invalidity/validity condition, preceded by the IF word, involves more than one condition, which must all be satisfied to obtain the chosen output, the word AND is used to join more conditions.
An example of an IF+AND+WHEN>THEN rule can be:
IF "Attribute_Name1" in {'apartment'} AND "Parking" in {'Garage'} WHEN "Location" in {'City'} THEN 'INVALID'
This means that if both conditions are satisfied, and at the same time the admissibility condition is satisfied, the rule output will be ‘INVALID’.
If only one of the conditions is satisfied, the rule output will be ‘VALID’.
If the admissibility condition is violated, the rule output will be ‘NOT APPLICABLE’.
IF+WHEN>THEN+OR+IF+WHEN>THEN
When the invalidity/validity condition involves more conditions, where at least one must be satisfied to obtain the chosen output, the word OR is used in the rule syntax.
An example of an IF+WHEN>THEN+OR+IF+WHEN>THEN rule can be:
IF "Attribute_Name1" in {'apartment'} WHEN "Location" in {'City'} OR "Parking" in 'Garage' WHEN "Location" in {'City'} THEN 'INVALID'
This means that if any of these two conditions is verified, the rule output will be ‘INVALID’.
If both conditions are verified, the rule output will be ‘INVALID’ as well, as more than one condition is satisfied.
If the admissibility condition is violated, the rule output will be ‘NOT APPLICABLE’.
Hint
The ‘OR’ word can be substituted by a | in the rule syntax. It must be preceded and followed by a blank space. Add the keyword [f] after the last condition.
IF+FORMULA+WHEN>THEN
When complex conditions need to be verified in a rule, functions can be integrated in the conditions.
You can add as many formulas as you want in the rule, but it is important to specify the [f] parameter after each formula.
Note
To know more about the supported functions in rules, go to the functions page.
An example of an IF+FORMULA+WHEN>THEN rule can be:
IF head("Order_type",7) [f] in {'Premium'} WHEN "Total" >= 100 THEN 'INVALID'
This means that the function returns the first seven characters of the values in the “Order_ID” attribute. If the first seven characters correspond to the string ‘Premium’, and the admissibility condition is satisfied, so the value in “Total” in the corresponding record is >= 100, the corresponding output value will be ‘INVALID’.
If the condition isn’t satisfied, the output will be ‘VALID’.
If the admissibility condition is violated, the rule output will be ‘NOT APPLICABLE’.
Once the rule configuration file has been configured, it is ready to be imported and linked to a Rule Engine task, along with the dataset containing the values to be verified.
The Options tab¶
Once the Rule Engine task has been dragged onto the stage, it must receive two inputs:
the rule configuration file
the values to be verified
The task has a simple interface, made of only one tab, that is the Options tab.
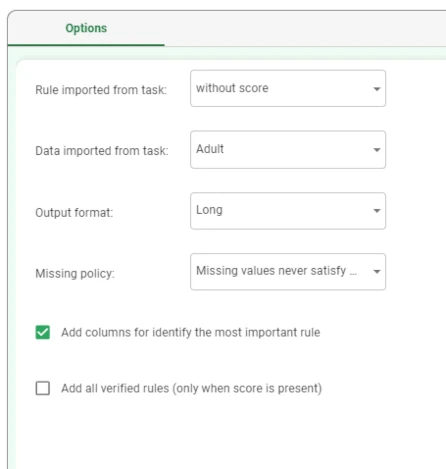
The following configuration options are available:
Rule imported from task: specify the task containing the rules.
Data imported from task: specify the task containing the values which will be verified by the rules.
- Output format: select how the rule output will be displayed. Possible values are:
Wide: the output is shown with additional columns, that are the columns specified after the THEN in the assignment rules. A new column called PRED(Rule Status) will be added. If more than one rule is matched in the same record, the final value in the PRED(Rule Status) attribute will be assigned according to the rule priority specified in the configuration file.
Long: one row is shown for each verified rule for each entry on data.
Long compact: one row is shown for each verified rule for each entry on data, while entries which don’t verify any rule will not be shown.
Warning
The output format must be specified as a flow variable, called “output_format”: to know more on variables and on how to configure them, go to the corresponding page.
Example¶
Import both the rule configuration file and the cars dataset into the flow by using two import tasks. The configuration file has been filled according to the rules listed above.
In the screenshot below, the Rules MS Excel configuration file is displayed,
Add a Rule Engine task to the flow, and link the two source files to it. Then, double-click the Rule Engine task to open it.
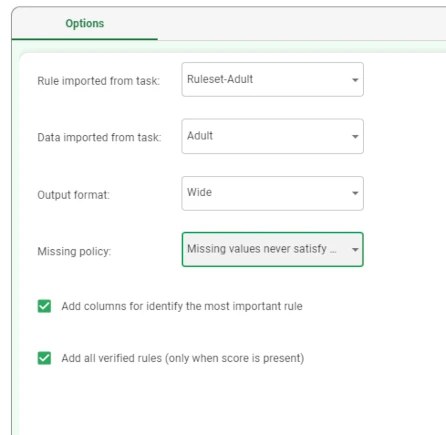
- Configure the Rule Engine task as follows:
Rule imported from task: rules_1
Data imported from task: data_1
Output format: Wide
Save and compute the task.
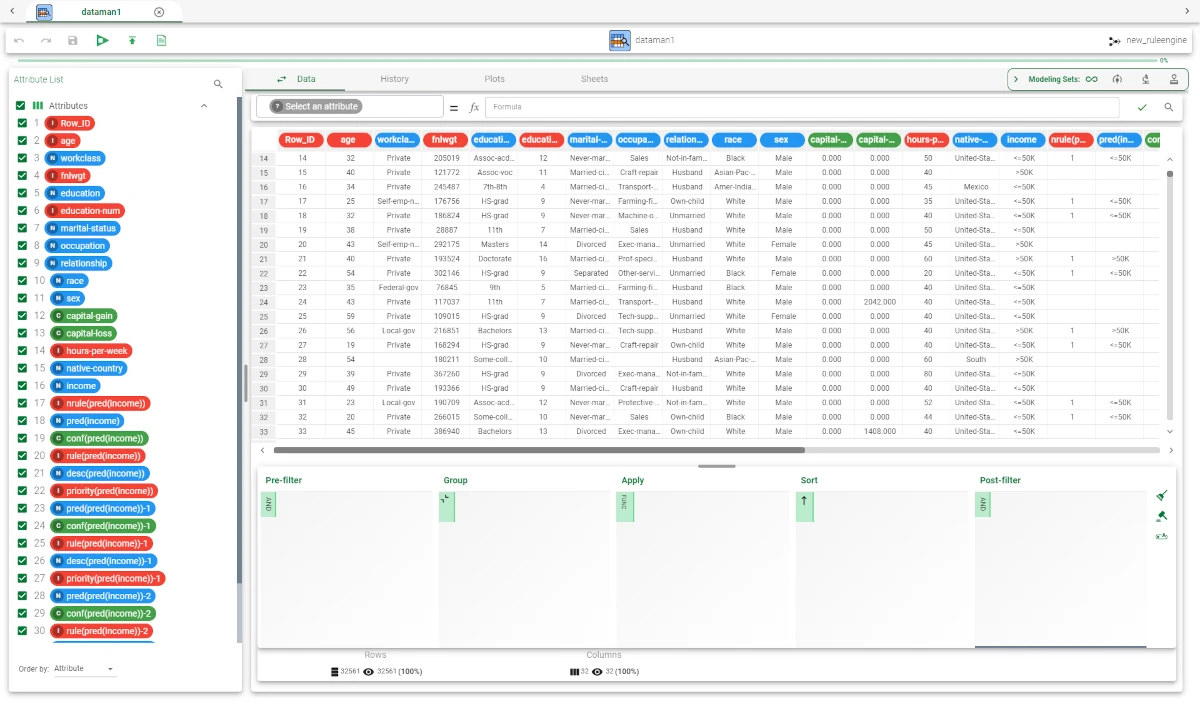
Add a Data Manager task onto the stage and link it to the Rule Engine task to visualize the results: as the Wide output format has been chosen, the attributes PRED(HighDiscount), PRED(LongShip), PRED(DiscountedCar) and PRED(ShippingTime) have been added.
- Each attribute contains the value specified after the THEN parameter:
In row 1, for example, two rules match the same record, namely rule 5 and rule 6 in the configuration file.