Sequence Analysis¶
Rulex Factory extracts frequent sequences from event logs with the Sequence Analysis task.
The task is divided into three tabs:
the Options tab, where you can set Basic and Advanced task configuration options;
the Frequent sequences tab, where you can analyze the generated frequent sequences;
the Results tab, where you will find general computation info.
The Options tab¶
The Options tab contains all the task’s features that can be customized to obtain the desired output.
It is divided into two tabs: the Basic and the Advanced tabs.
The Available attributes list is always displayed, no matter which Options tab is opened.
Basic tab
In the Basic tab, you will find a full range of options: it is divided into two sections: the attribute drop area and the basic options.
In the attribute drop area you will find the following panels:
Sequence ID attributes (NOMINAL): drag the nominal attributes which identify the sequences. Instead of manually dragging and dropping attributes, they can be defined via a filtered list.
Event ID attributes (NOMINAL): drag the nominal attributes which characterize the events. Instead of manually dragging and dropping attributes, they can be defined via a filtered list.
The following basic configuration options are provided:
Minimum event support (# samples): all events which appear in orders fewer times than this threshold are discarded. This value is relevant only if the Auto (specify #events) option is not selected.
Auto (specify #events): if this option is selected, the minimum support for events is automatically computed: the user shall specify the number of events to take into account (most frequent first).
# Events to consider: number of events to take into account (most frequent first). This value is relevant only if the Auto (specify #events) option is selected.
Minimum sequence support (# samples): all sequences which are verified fewer times than this threshold are discarded. This value is relevant only if the Auto (above average) option is not selected.
Auto (above average): if this option is selected, the minimum sequence support is set to the average support of sequences with the same dimension (i.e. constituted by the same number of events).
Maximum sequence cardinality: maximum cardinality of generated sequences.
No maximum sequence cardinality: if selected, all sequences with higher support than the specified threshold are generated, regardless of their cardinality.
Time attribute, measurement unit: attribute including the timestamp for each of the events.
The reference time unit can be specified via the drop-down menu.
Advanced tab
The Advanced tab is divided into two sections: the attribute drop area and the advanced options.
In the attribute drop area the following panel is provided:
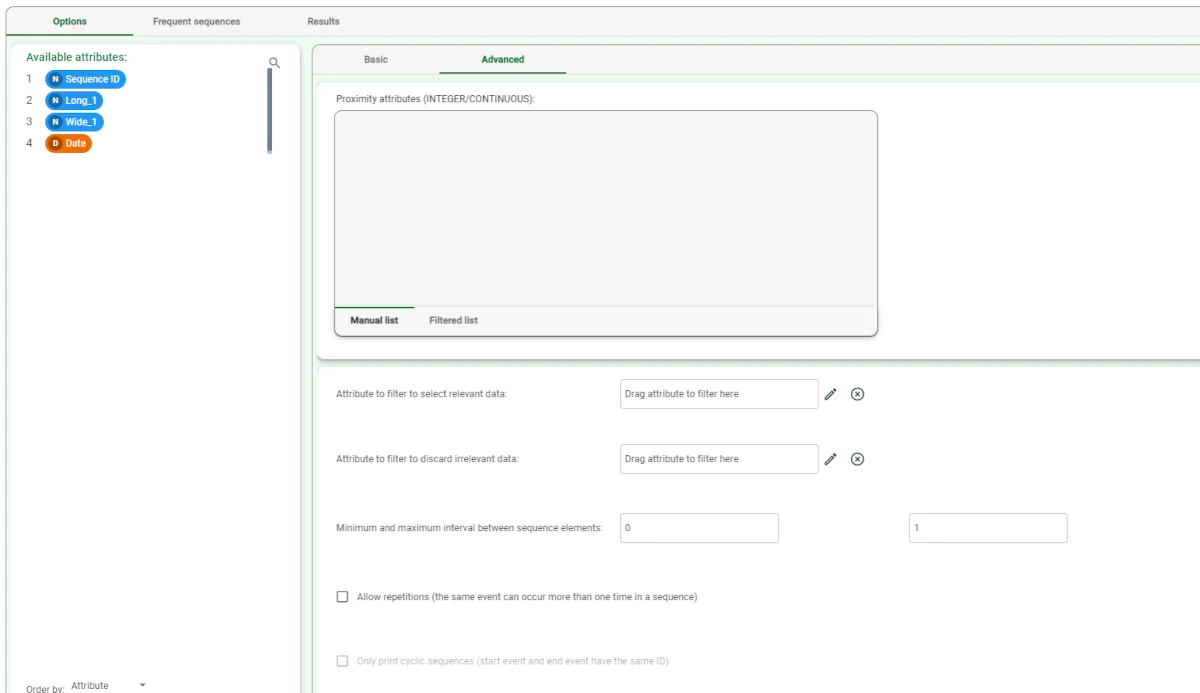
Proximity attributes (INTEGER/CONTINUOUS): the ordered item attributes which characterize the proximity among events together with time, and the corresponding thresholds in the Minimum-maximum proximity thresholds edit box can be set. Attributes can be defined also via a filtered list.
For example, if you need to mine frequent sub-sequences of events which occur in locations close to each other, spatial coordinates shall be dragged in this list.
The following options are provided:
Attribute to filter to select relevant data: drag the attribute containing relevant rows to add to the existing parameters to perform the analysis, regardless the number of transactions in which the item appears, that is its support. To know more about attribute filters go to the corresponding page.
Attribute to filter to discard irrelevant data: drag the attribute containing the irrelevant rows to exclude from the analysis, regardless the number of transactions in which the item appears, that is its support. To know more about attribute filters go to the corresponding page.
Minimum and maximum interval between sequence elements: consecutive events in sequences are bound to these minimum and maximum thresholds of temporal distance.
Allow repetitions (the same event can occur more than one time in a sequence): if selected, repetitions of the same event in a single sequence are allowed.
Only print cyclic sequences (start event and event have the same ID): if selected, the output is constituted only by the sequences in which the first event is characterized by the same ID as the last one.
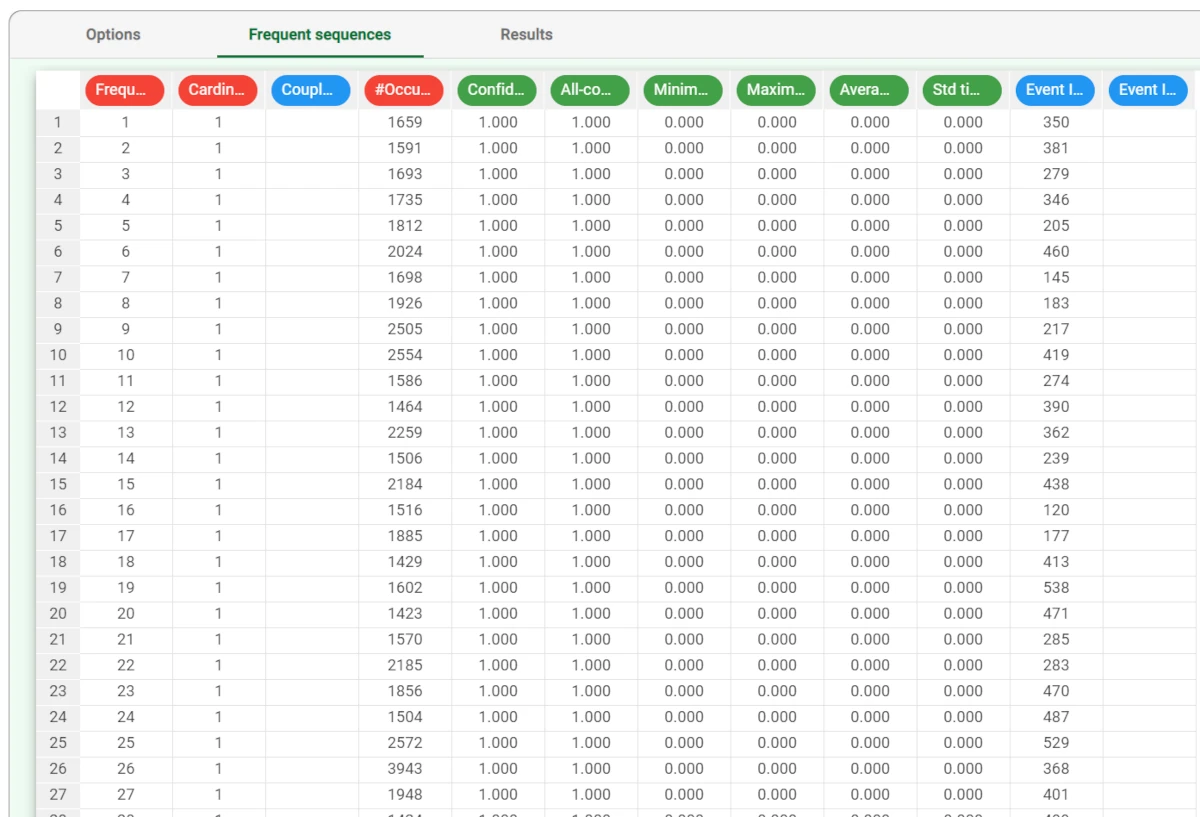
The Frequent sequences tab¶
In the Frequent sequences tab, a spreadsheet showing the sequence analysis is created.
The following attributes can be found:
Frequent sequence ID: sequential ID number for the frequent sequence.
Cardinality: number of events that make up the frequent sequence.
- Couple characterization: Qualitative characterization of the behavior for the sequence of two events A-B. The possible outcomes are:
Weak sequence - B is likely to follow A, A is indifferent to B,
Strong sequence - B is likely to follow A, A is unlikely to follow B,
Complements - B is likely to follow A and vice-versa,
Substitutes - B is unlikely to follow A and vice-versa,
Independents - B is indifferent to A and vice-versa, or
Not enough information to determine.
#Occurrences: number of times in which the sequence is retrieved in the data.
Confidence (with respect to initial event): ratio of cases (0-1 value) in which, if the initial part of the sequence is verified, the final part follows. The first column of confidence is referred to the initial event, i.e. measures how often, if the initial event happens, the rest of the sequence follows. If a Maximum sequence cardinality higher than 2 is set, other columns are also generated, representing how often if the first two events are verified the other follow and so on. It considers the time range between the first event and the others.
All-confidence: ratio between the number of occurrences of the whole sequence and the number of occurrences of the least frequent event included in the sequence.
Minimum time interval [time measurement unit]: minimum interval of occurrences associated to the frequent sequence.
Maximum time interval [time measurement unit]: maximum interval of occurrences associated to the frequent sequence.
Average time interval [time measurement unit]: average interval of occurrences associated to the frequent sequence.
Event ID #: IDs of the events constituting the frequent sequence.
The Results tab¶
The Results tab provides information on the computation. It is divided into two sections:
- The General info section, where the following information can be found:
Task label: the task’s name.
Elapsed time (sec): time required for latest computation (in seconds).
- The Result Quantities section contains the data quantities: check the results to be visualized, then open them by clicking on the arrow button to visualize the quantities’ values. The following information is provided:
Number of different events in input: number of distinct events which were fed to the task during the latest computation. It is divided into Events, Sequences, Frequent.
Number of different sequences in input: number of distinct sequences which were fed to the task during the latest computation. It is divided into Events, Sequences, Frequent.
Number of generated frequent sequences: number of sequences which were found to be frequent, according to the support threshold. It is divided into Events, Sequences, Frequent.
Minimum event support#: minimum number of occurrences for frequent events. It is divided into Events only.
Example¶
After having imported the dataset with an Import from Text File task, add a Reshape to Long task and drag all the Event_ID (from 1 to 10) attributes onto the Attributes to be transformed in long format area.
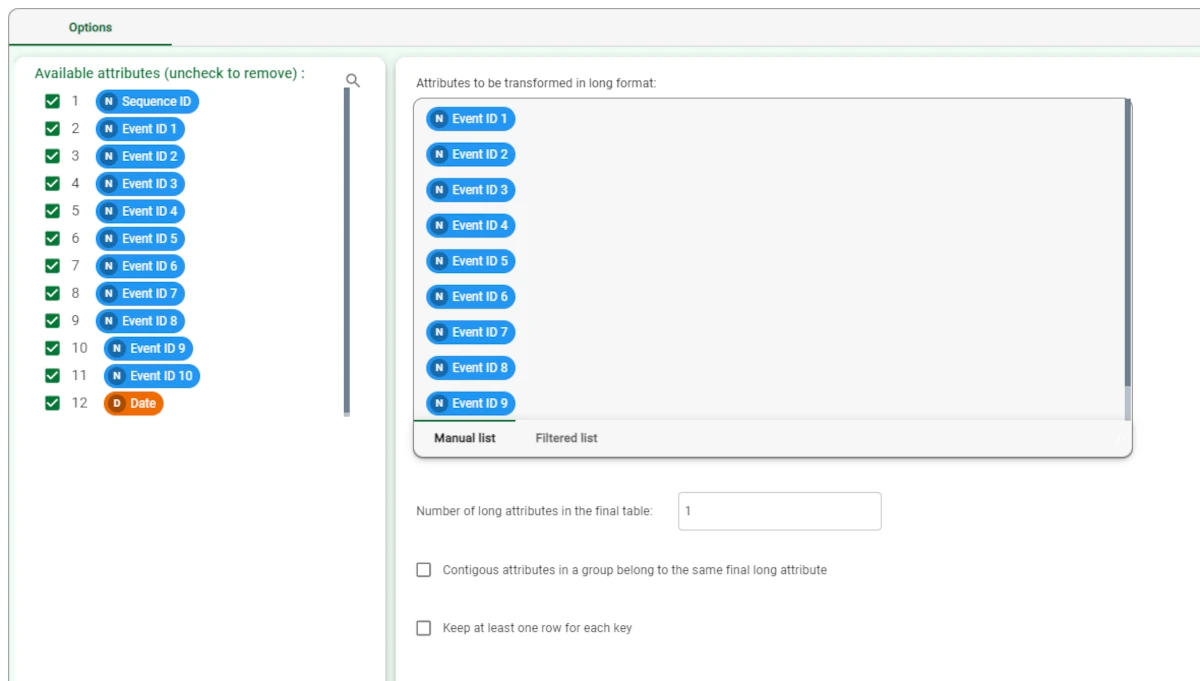
Then, we connect the Sequence Analysis task to the Reshape to Long task. Configure the task as follows:
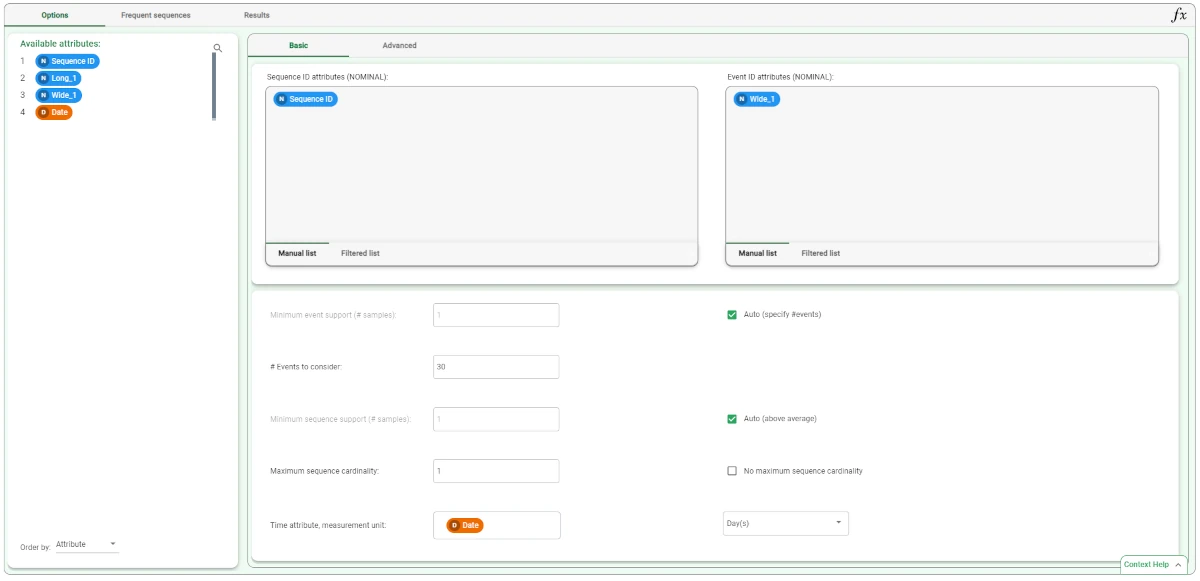
Drag and drop the Sequence ID attribute in the Sequence ID attributes list and the Wide_1 attribute in the Event ID attributes list.
Select the Auto option (to the right) for the Minimum event support.
Set the #Events to consider to 30 (if you have problems setting this number deselect and reselect the Auto option above).
Deselect the Auto (above average) option for Minimum sequence support (#samples) and set the value to 10.
Set the Maximum sequence cardinality to 2.
Select Date as the Time attribute (and day as the unit of measure).
Set the Minimum and maximum interval between sequence elements respectively to 0 and 1.
The extracted frequent sequences can be seen in the Frequent Sequences tab.