Module Task Configuration¶
Module tasks are among Rulex Factory’s flow functions. Users can use them to store their important routines, so that they can use them in any other flow where they’re needed.
There are three main concepts in this page:
the parent flow is the flow containing the module task.
the module task is the task containing the module.
the module is the flow to be executed within the module task.
Important
In this page, reference to the flow containing the module task is made through the word parent flow, while reference to the flow executed inside the parent flow is made through the word module.
As modules execute an external flow within the parent flow, the following options need to be set:
Configure links to state where the module task inputs the source data inside the module itself via the mapping configuration operation.
Configure the flow variables which will be inherited by the module during the computation.
Rulex Factory provides users with two module tasks:
the Execute Rulex Flow File task, and the
the Rulex Flow File Source task.
Module selection¶
The first operation to perform when configuring a module task is selecting the module which will be executed inside it.
To perform this activity, it is required to use the Source controller, located in the Options tab in all module tasks.
To know more about the Source controller, refer to the import tasks page.
Note
The only difference between the module tasks’ Source controller and the import tasks Source controller is that in the former only one file can be selected, while in import tasks users can import multiple files through a single operation.
Once the file is selected, the selection graphical elements are greyed out until the current choice has been deleted.
Module mapping¶
Warning
To perform mapping operations, the module to be executed must be selected.
As just said, a module task inserted in the parent flow executes a module which may contain tasks which need to be connected with the ones in the parent flow of the module task.
This operation of connection between the external flow (the parent flow) and the internal flow (root tasks in the module) can be performed in two ways:
By using the Mapping configuration tab
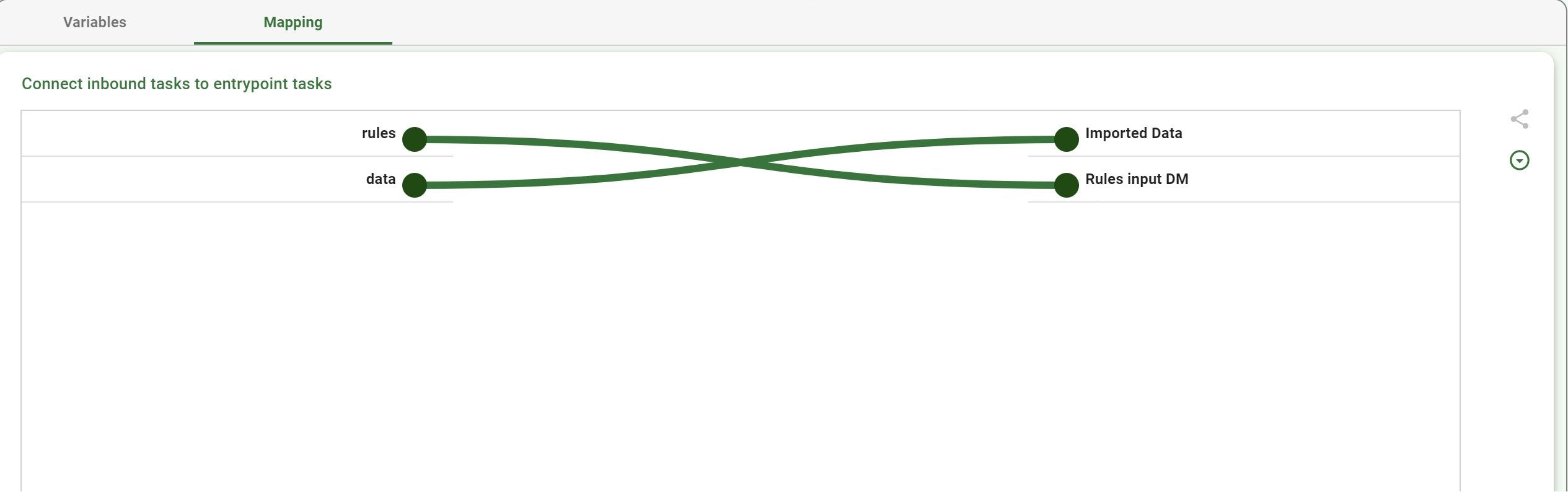
By expanding the module on the stage and by performing the connection directly from the stage.
The mapping configuration tab, along with the text area provided in the parametric visualization mode, allows users to configure the module using two visualization modes:
Tree view: draw the links between all the tasks defined as parents of the module task in the parent flow (on the left) and all the roots of the module (on the right).
Link view: select line by line using drop down menus to perform the connection. To define a new connection, you need to: #. Select from the drop-down menu, located on the right, the root in the module you want to connect; #. Select the corresponding parent task, located on the left, which is going to send the root the input data.
Note
Tree view can be cumbersome when the number of entering tasks and roots overcomes 5. For this reason above this threshold the List visualization becomes the default visualization in the task.
When on the stage, users always have the possibility to expand a module by clicking on the Plus icon button located on the left side of any module task node. Once the module is expanded, users should be able to see all its internal tasks on the stage, inserted into a green square box. It is possible to go back to the module task visualization by clicking the minus button next to the expanded module. After having performed this operation, it is possible to connect any task in the parent flow to any module internal task. Rulex Factory’s system automatically updates the mapping options according to the changes made.
All the data structures contained in the input tasks of the parent flow are forwarded to the connected task inside the module. The same operation is performed when dealing with the output from the configured module endpoint to the child tasks in the parent flow.
Module variables¶
Flow variables (both code and vault variables) are inherited by the module, which can use them to slightly modify its internal logic structure according to the parent flow configuration options.
There are three variables sources, listed below by following their hierarchical order from the less important to the most important one:
The module itself
The parent flow
A dedicated module task option called procvars
The variable controller in all the module task interfaces allows users to decide in any case the value to be used by the module. The variable controller, indeed, is drawn in its Standard visualization as a three column table:
In the first column, the names of the variables defined in the module are shown.
In the second column, the current variables’ values are defined. If a code variable with the same name is present in both the module and the parent flow, the parent flow values overwrite the module variables values.
If a code variable with the same name is present in the module task, the module itself and the parent flow, then the module task values overwrite both the module and the parent flow values.
If a variable is present in the parent flow, the current module task variable value will show@<variable_name>. This column can be edited, so that the user can define variable values with a few clicks, if needed. This way, the customized variable overwrites the corresponding flow variable.In the third column the default value, hence the value contained in the module, is always shown.
A magnifier icon, located next to the first column header, enables users to select inside the variables list the ones they’re looking for.
Module computation¶
Module task computation performs the execution of an external module: since also the module is a flow, its computation has the same behavior of a complete flow, computed using the in-memory computation mode.
Therefore, in Rulex Platform Cloud version, the module execution is balanced on the resource of the cluster in the same way of the standard flow computation. It can be executed in a different node than the one of the original flow. In Rulex Platform Standalone version, too, the module is executed in a separate sub-flow compared to the original parent flow.
This implementation allows the system to recover any issue occurring during the module’s computation and to manage reactions on them (for example by performing automatic retries). This increases the stability and the maintenance of module tasks computation.
Since the two computations are widely separated, not all the information are shared between the parent flow and the module.
Attention
The division between the parent flow and the module has some important implications:
Only the input data structures and the variables (following the hierarchy explained in the section above) are sent to the module and only the output data structures are gathered back.
Editing performed on the variables received as input by the module (for example by using a runtime variable task) is not visible outside the module where the original value is still standing.
Inside the module, the shortcut __this__, used also in the import from task task, refers to the module itself. It can not be used to import data from the parent flow from inside.
Module computation can be configured to be executed several times: this loop interaction is called module loop computation.
Loop computation can be performed by configuring the following options in the Configuration tab within the Execute Rulex Flow File task:
Number of executions: the total number of module executions we want to perform. If its value is 1, the other options are automatically greyed out.
Maximum parallelization: the number of iterations which can be executed in parallel (the default value is 1, so that it works if data needs to be re-entered).
Iterator: the process variable of the parent flow which is used as iterator of our loop computation. You can configure the increment/decrement of the variable value at each iteration.
- For each execution: specify whether specific flow variables (selected from the list) should be incremented or decremented with each iteration. Possible values are:
Increment
Decrement
Feedback entrypoint: the task in the linked process where the output of the iteration will be used as input.
Accumulate iterations data: if selected, the results of successive iterations are all saved and not overwritten.
Consider the output of each iteration as the input for the following one: if selected, the output of each iteration is used as the input of the following iteration. If selected, the In case of error in iteration option will behave as if the raise error operation has been chosen, even though a different one is specified.
- In case of error in iteration: choose from the drop-down list how errors in module computation should be managed, when performing loop iterations. The possible values are:
raise error: if an error occurs during one of the iterations, the module task computation is stopped and an error is returned.
continue and raise warning at the end: if an error occurs during one of the iterations, the task continues computing the module until it reaches the established Number of executions, returning an error at the end of the computation, reporting details about iteration(s) where the error occurred.
Iteration of a loop execution as shown directly in the module task node is explained here.
Hint
It is possible to stop the loop execution by inserting the breakLoop function in a Data Manager task inside the module.
Hint
In the Standalone version an extra option Prevent loop parallelization can be used to force the Maximum parallelization to 1 and to speed up the full computation since all the iterations are executed by the same sub-process which is then prepared only once.
This is not a complete description of a specific module task. The rest of the options available in the two tasks are explained in detail in their dedicated pages, the Execute Rulex Flow File task page, and the Rulex Flow File Source page.