Data Functions¶
Data functions operate on the data types or values.
The following functions are available:
—
cast¶
The cast function casts the type of the selected attribute to the specified data type.
This function can also be used when the attribute is empty, to ensure the correct data type is assigned to the column, as an empty column will be otherwise be assigned the nominal data type.
Parameters
cast(column, newtype, forced)
Parameter |
Description |
|---|---|
column |
The attribute whose values we want to cast. The column parameter is mandatory. |
newtype |
The datatype the attribute will be cast to. The newtype parameter is mandatory.Possible values, for this parameter are: “integer”, “nominal”, “continuous”, “long”, “double”, “binary”, “ordinal”, “percentage”, “currency”, “date”, “week”, “month”, “quarter”, “datetime”, “time”, “index”, “boolean”, “int”, “float”, “short”, “string”. |
forced |
If set to |
Example - cast(column, newtype, forced)
The following example uses the Car Sales dataset.
In the car_sales dataset, the Sales_in_thousands attribute contains continuous values with detailed numbers.
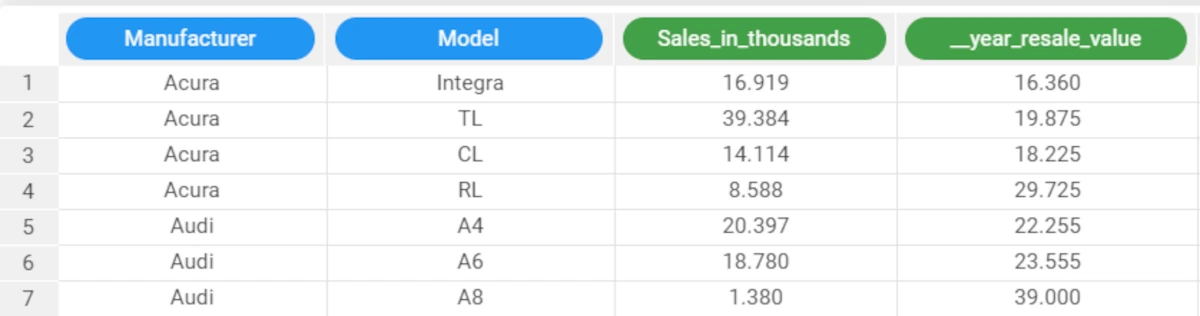
If we cast this continuous attribute to an integer we will round off the number into the nearest a thousand.
The required formula is
cast($"Sales_in_thousands", "integer").

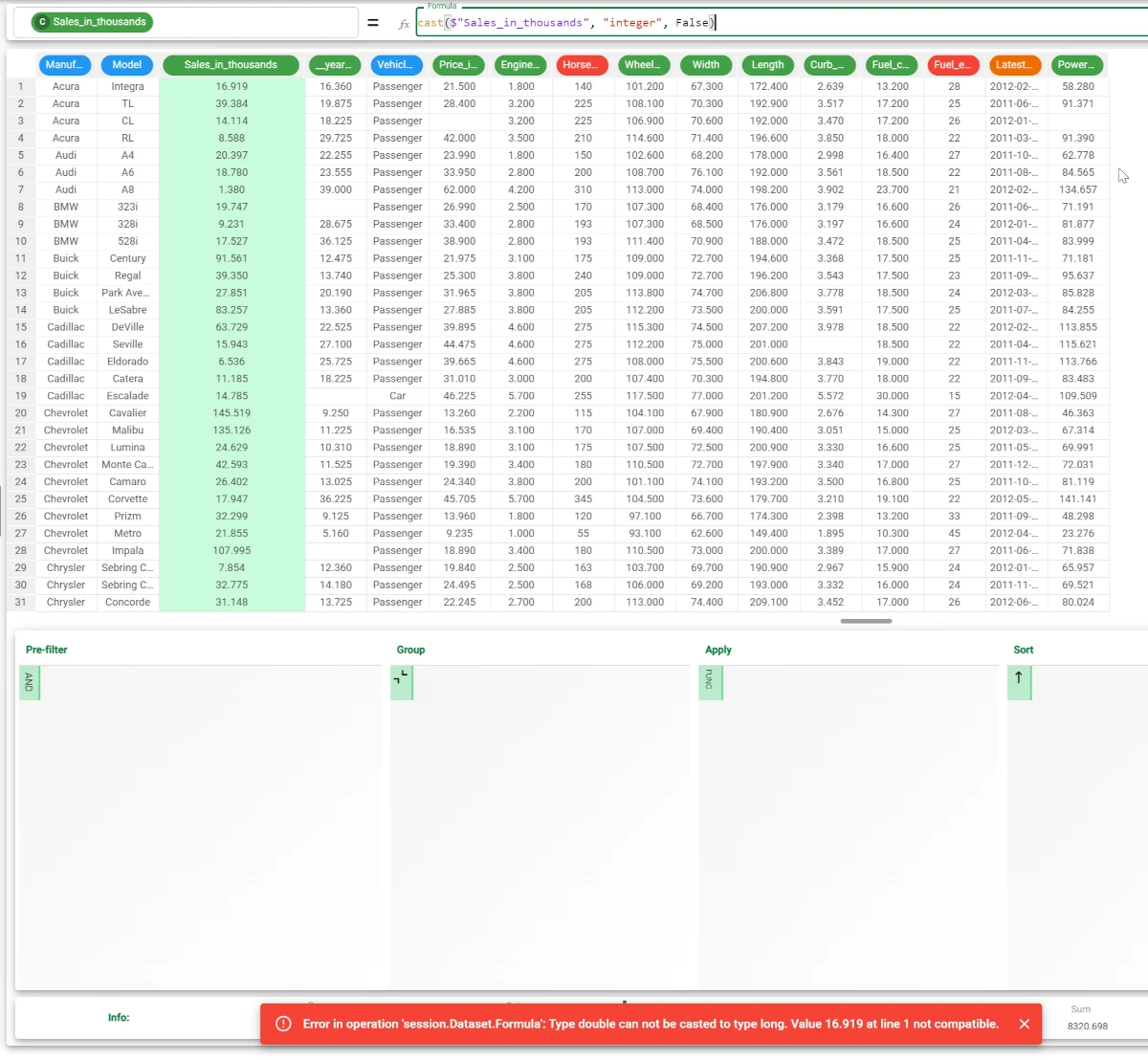
If we entered the value False for the forced parameter, the cast operation would not be performed, as it results in a loss of data precision of the continuous attribute values.
The formula used in this case is
cast($"Sales_in_thousands", "integer", False). An error message will be displayed at the bottom of the screen.
catNames¶
The catNames function searches for values in specific attributes, and returns the headers of the attributes where the values were found. All the corresponding headers are concatenated.
This function is useful for finding values in very large datasets.
Parameters
catNames(indatt, values, separator, negate)
Parameter |
Description |
|---|---|
indatt |
The attributes whose values we want to search in. Multiple attributes must be included in square brackets, such as |
values |
The values which will be searched for in the attributes indicated in the indatt parameter. The newtype parameter is mandatory. |
separator |
The required separator to divide the returned headers. Symbols or strings can be used, for example |
negate |
If set to |
Example - catNames(indatt, values)
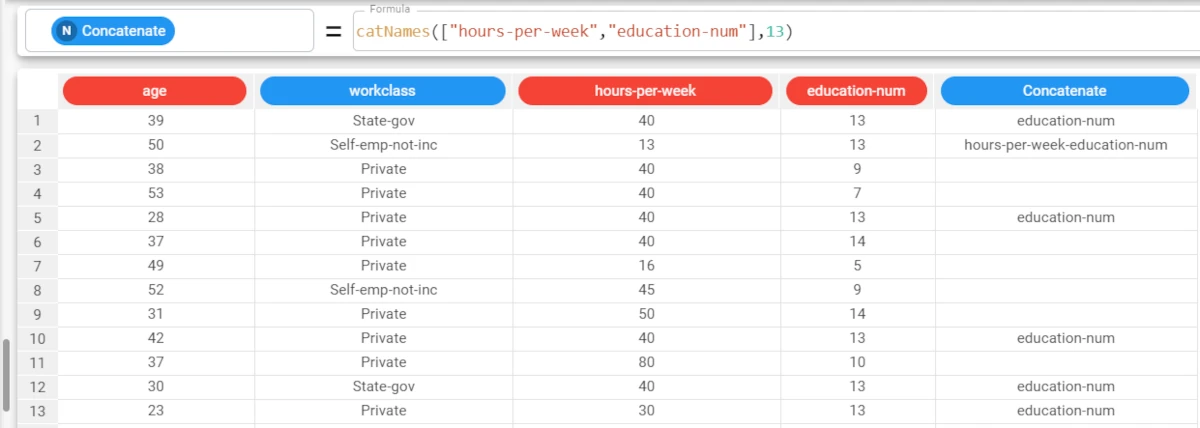
The following example uses the Adult dataset.
In the adult dataset, we are looking for the value “13” in the two attributes hours-per-week and education-num. We have added a new attribute, called Concatenate, to contain the results.
The formula will consequently be:
catNames(["hours-per-week","education-num"],13).
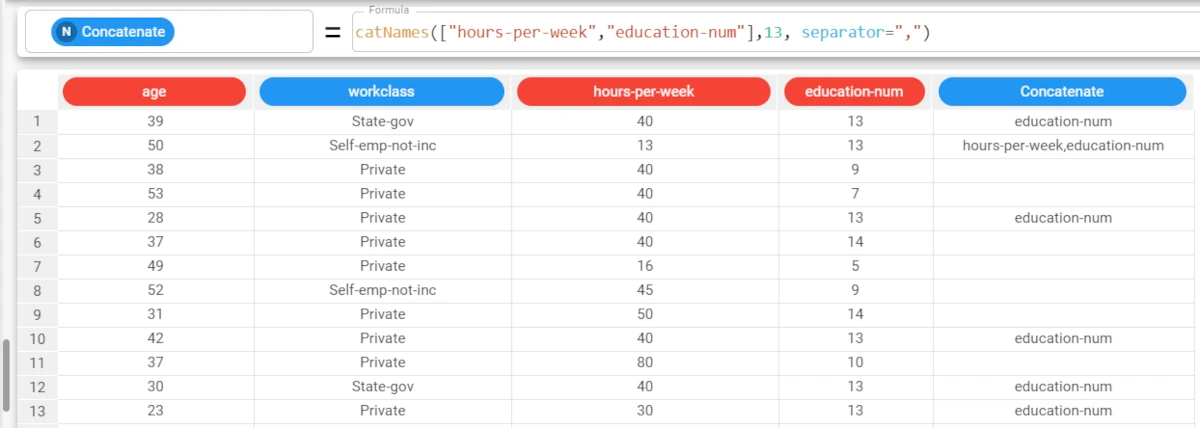
Example - catNames(indatt, values, separator)
The following example uses the Adult dataset.
In the second example, we will then change the default “-” symbol to concatenate values to “,”.
The formula will now be :
catNames(["hours-per-week","education-num"],13, separator=",")
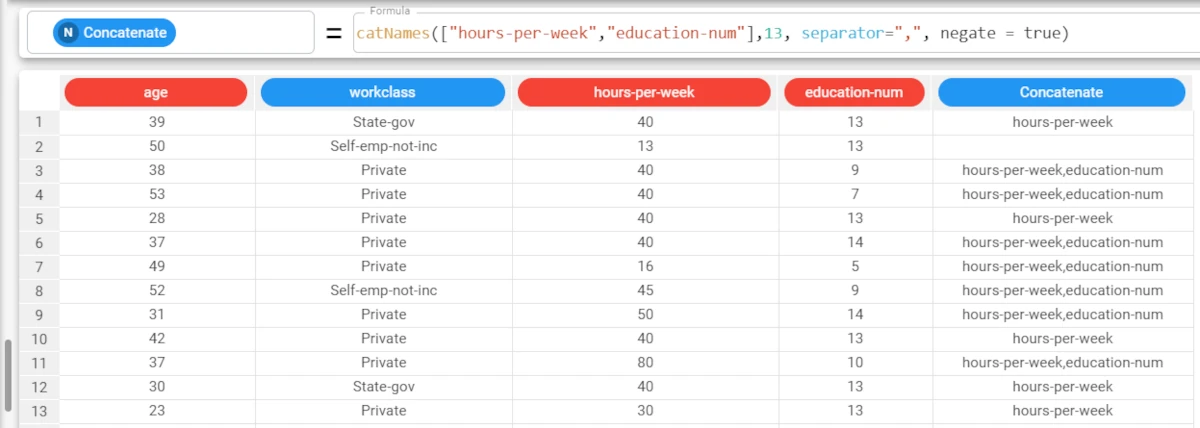
Example - catNames(indatt, values, separator, negate)
The following example uses the Adult dataset.
In this last example, we want to return the headers of the attributes where the value 13 is not present in any of them.
The formula will now be:
catNames(["hours-per-week","education-num"],13, separator=",", negate = true)
decideType¶
Assigns the correct data type to an attribute, depending on the values it contains.
Parameters
decideType(column)
Parameter |
Description |
|---|---|
column |
The attribute for which we want to define the correct data type. The column parameter is mandatory. |
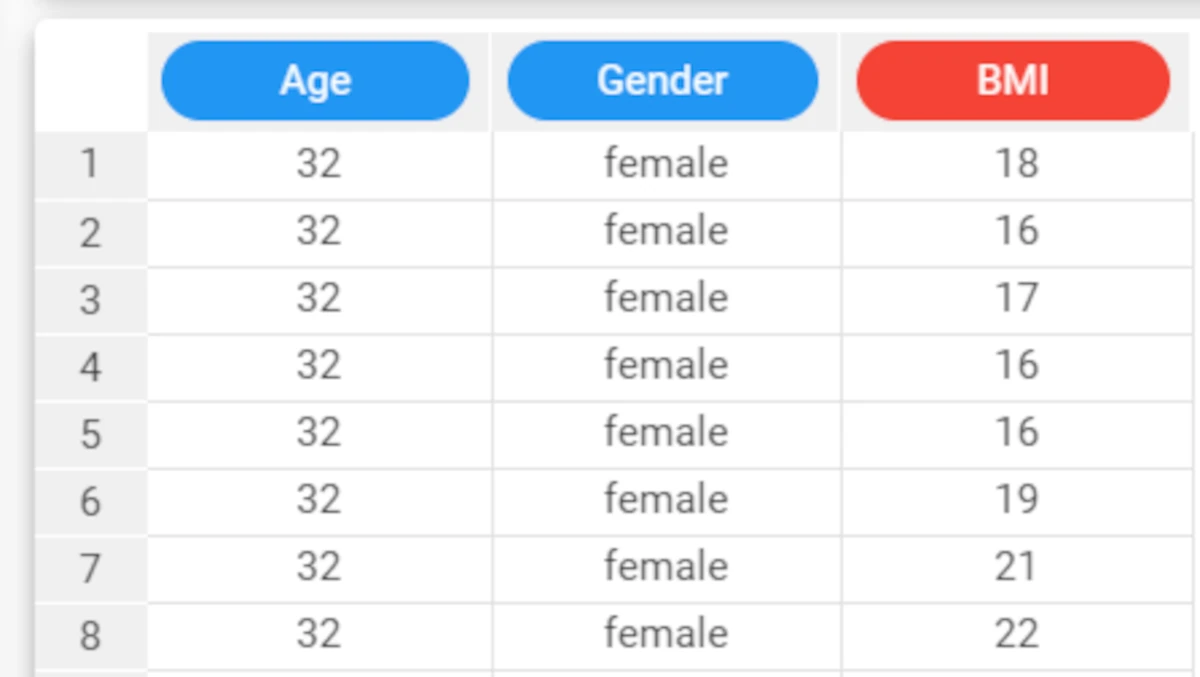
Example - decideType(column)
The following example uses the Age_BMI dataset.
In the Age_BMI dataset, we have changed the data type of the Age attribute to nominal, for the sake of the exercise.
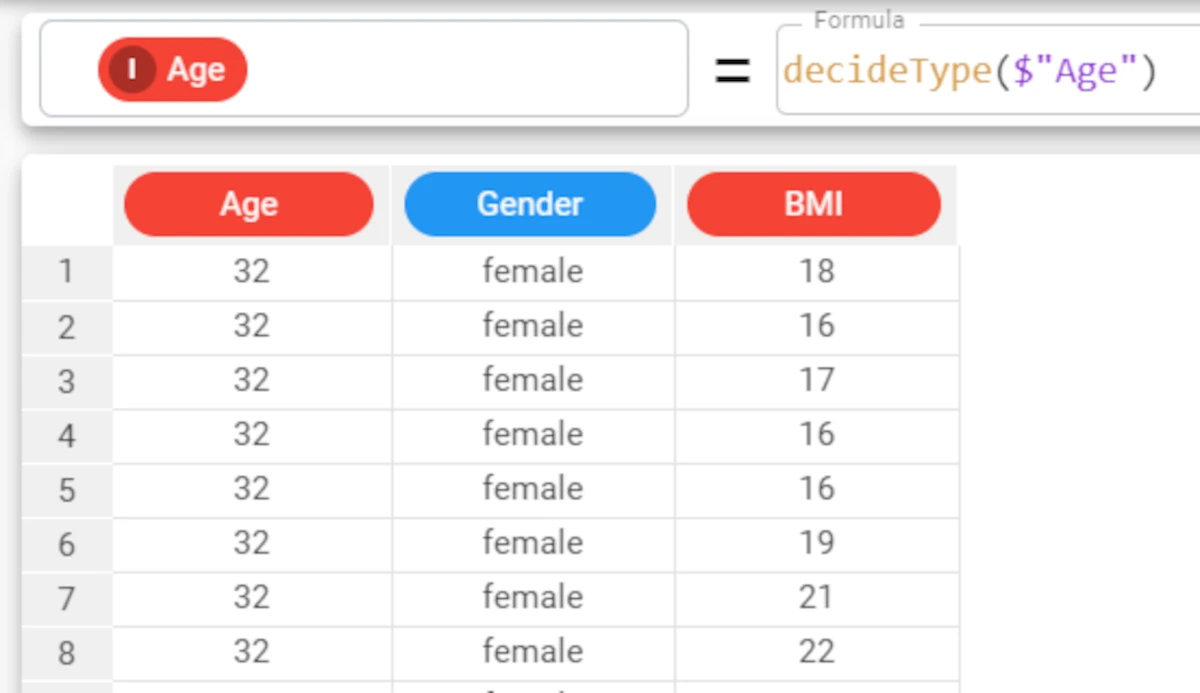
We can now use the decideType function to define the correct data type for the attribute, according to the values it contains.
The function is simply
decideType($"Age").The integer data type has been correctly redefined.
disc¶
The disc function discretizes data values into ranges defined by cutoff values.
Parameters
disc(column, cutoffs, rank)
Parameter |
Description |
|---|---|
column |
The attribute whose values we want to discretize. The column parameter is mandatory. |
cutoffs |
The cutoff values that will be used to discretize values into ranges. All cutoff points must be enclosed in square brackets. The cutoffs parameter is mandatory. |
rank |
By default, the central value of each range is displayed. If instead we want to display a ranking number for each range, the rank value must be set to |
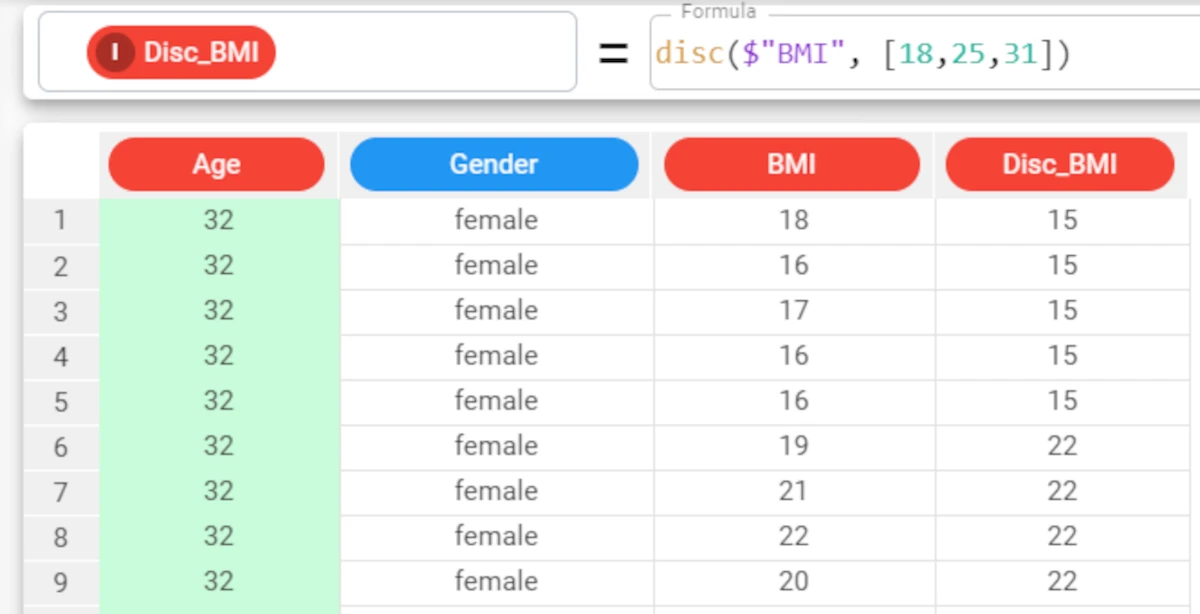
Example - disc(column, cutoffs)
The following example uses the Age_BMI dataset. This dataset has been extracted from the public Hepatitis C Virus (HCV) for Egyptian patients dataset available on Kaggle.
In the Age_BMI dataset, we have added a new attribute, called Disc_BMI, to the dataset to contain the discretized values of the BMI attribute.
In this new attribute we have divided the BMI values into 4 different ranges, using the cutoff values 18, 25 and 31, with the formula
disc($"BMI", [18, 25, 31]).The resulting 4 groups display the central value for each range.
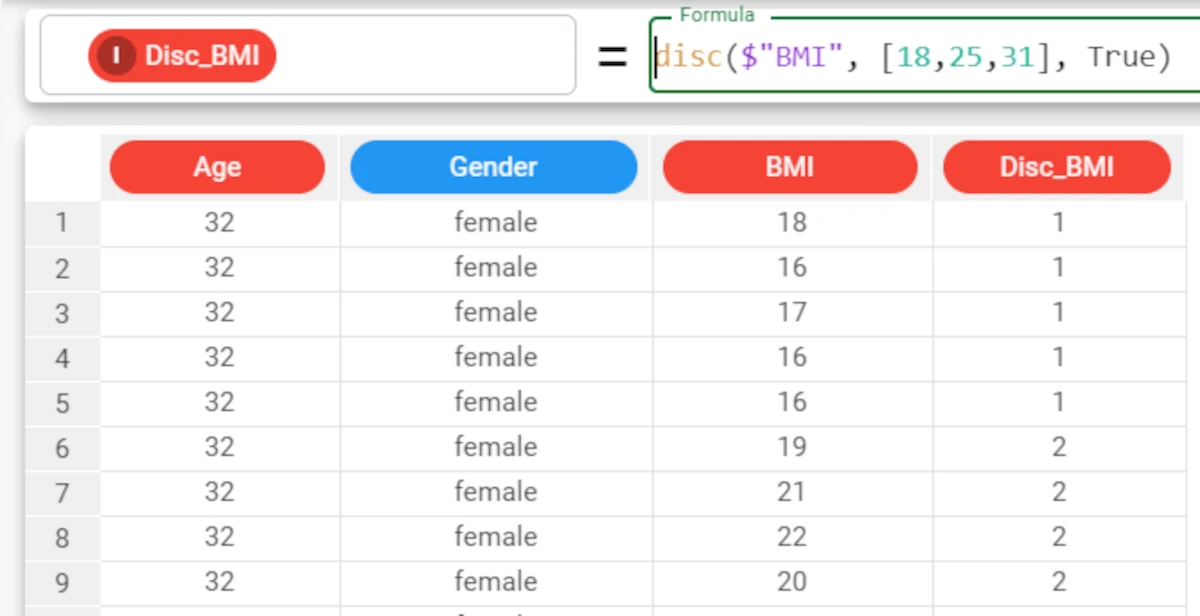
Example - disc(column, cutoffs, rank)
The following example uses the Age_BMI dataset. This dataset has been extracted from the public Hepatitis C Virus (HCV) for Egyptian patients dataset available on Kaggle.
If we want to display a ranking number for each range, we simply set the rank parameter to True, instead of leaving its default value.
The formula will consequently be:
disc($"BMI", [18, 25. 31], True).
discEqualFrequency¶
The discEqualFrequency function discretizes data values into bins which contain the same number of values in each.
Parameters
discEqualFrequency(column, nvalue, rank, quantile)
Parameter |
Description |
|---|---|
column |
The attribute whose values we want to discretize. The column parameter is mandatory. |
nvalue |
The number of bins you want to create. cutoff values that will be used to discretize values into ranges. All cutoff points must be enclosed in square brackets. The nvalue parameter is mandatory. |
rank |
By default, the central value of each range is displayed. If instead we want to display a ranking number for each range, the rank value must be set to |
quantile |
If set to |
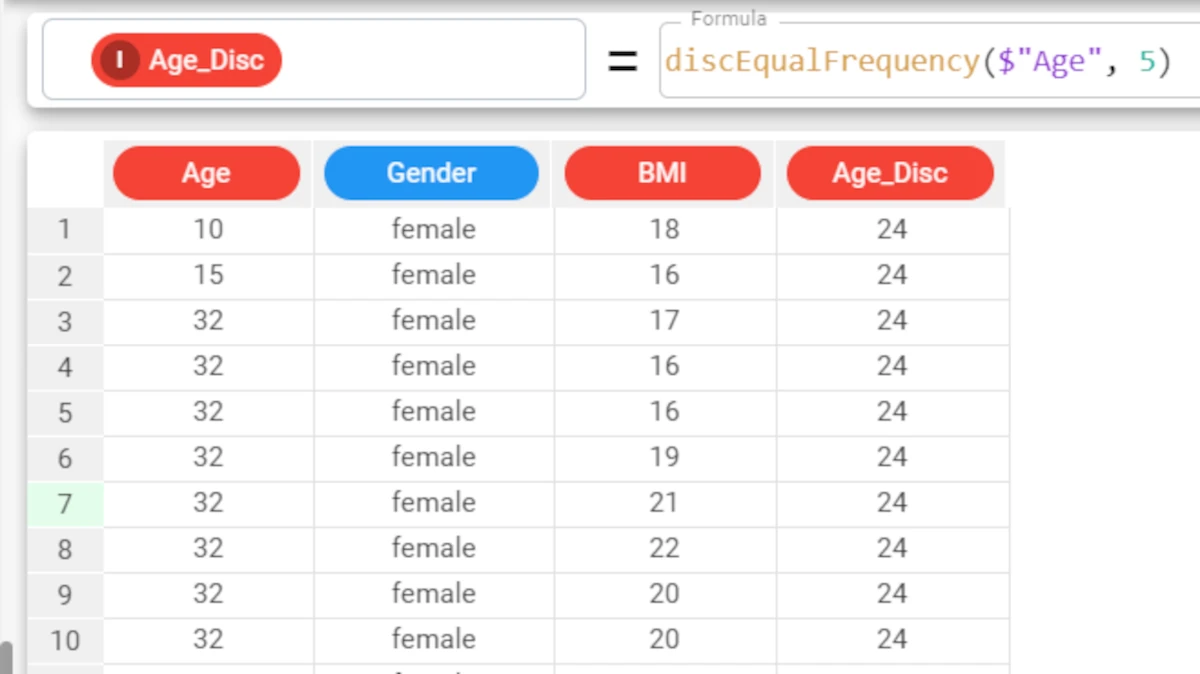
Example - discEqualFrequency(column, nvalue)
The following example uses the Age_BMI dataset. This dataset has been extracted from the public Hepatitis C Virus (HCV) for Egyptian patients dataset available on Kaggle.
In the Age_BMI dataset, we have added a new attribute, called Disc_Age, to the dataset to contain the discretized values of the Age attribute.
In this new attribute we have divided the Age values into 5 different bins, which each contain the same number of values, with the formula
discEqualFrequency($"Age", 5).The resulting 5 groups display the central value for each bin: 35, 40, 46, 52, 58.
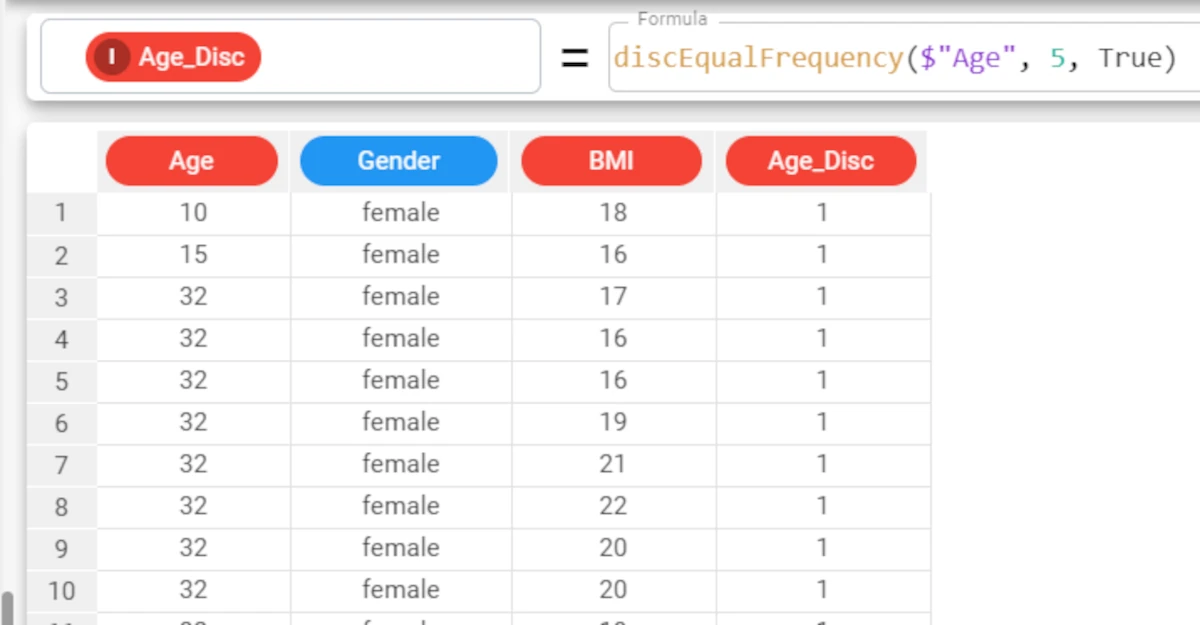
Example - discEqualFrequency(column, nvalue, nrank)
The following example uses the Age_BMI dataset. This dataset has been extracted from the public Hepatitis C Virus (HCV) for Egyptian patients dataset available on Kaggle.
If we want to display a ranking number for each range, we simply set the rank parameter to
True, instead of leaving its default value.The formula will consequently be:
discEqualFrequency($"Age", 5, True).The resulting 5 bins will now have a ranking number from 1 to 5.
discEqualWidth¶
The discEqualWidth function discretizes data values into bins of equal width.
Parameters
discEqualWidth(column, nvalue, rank, min, max)
Parameter |
Description |
|---|---|
column |
The attribute whose values we want to discretize. The column parameter is mandatory. |
nvalue |
The number of bins you want to create. cutoff values that will be used to discretize values into ranges. All cutoff points must be enclosed in square brackets. The nvalue parameter is mandatory. |
rank |
By default, the central value of each range is displayed. If instead we want to display a ranking number for each range, the rank value must be set to |
min |
If required, you can set a minimum value, which may not correspond to the values currently present in the dataset. For example, in our dataset the minimum value for the age attribute is currently 32, but we would like to create bins that range from 18 years of age, as this is the potential age range of our survey. In this case, you can set the minimum value to 18. |
max |
If required, you can set a maximum value, which may not correspond to the values currently present in the dataset. For example, in our dataset the maximum value for the age attribute is currently 61, but we would like to create bins that range up to 80, as this is the potential age range of our survey. In this case, you can set the maximum value to 75. |
Example - discEqualWidth(column, nvalue)
The following example uses the Age_BMI dataset. This dataset has been extracted from the public Hepatitis C Virus (HCV) for Egyptian patients dataset available on Kaggle.
In the Age_BMI dataset, we have added a new attribute, called Age_Disc, to the dataset to contain the discretized values of the Age attribute.
In this new attribute we have divided the Age values into 5 different bins of equal width, with the formula
discEqualWidth($"Age", 5).The resulting 5 groups display the central value for each bin: 35, 41, 47, 52, 58.
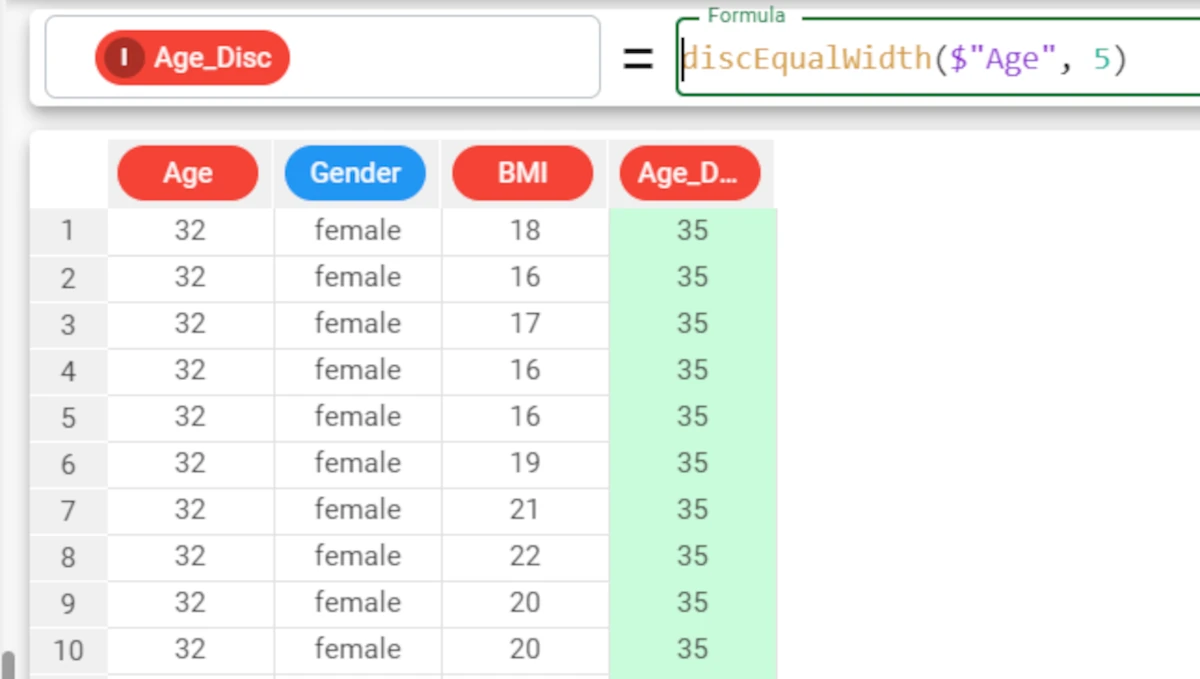
Example - discEqualWidth(column, nvalue, rank)
The following example uses the Age_BMI dataset. This dataset has been extracted from the public Hepatitis C Virus (HCV) for Egyptian patients dataset available on Kaggle.
If we want to display a ranking number for each range, we simply set the rank parameter to True, instead of leaving its default value.
The formula will consequently be:
discEqualWidth($"Age", 5, True).The resulting 5 bins will now have a ranking number from 1 to 5.
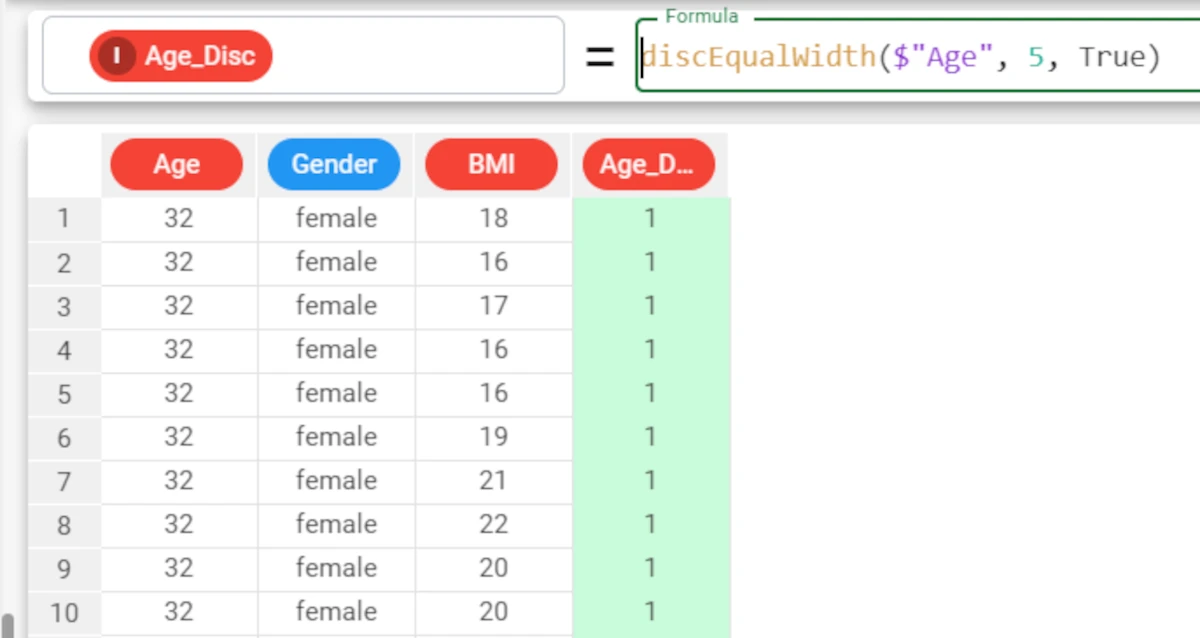
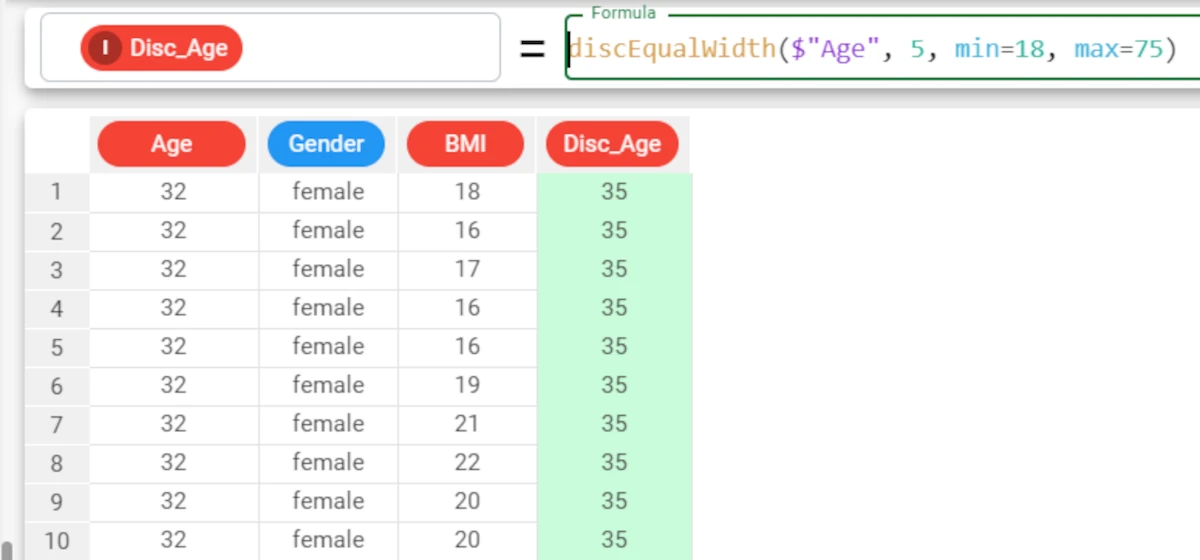
Example - discEqualWidth(column, nvalue, rank, min, max)
The following example uses the Age_BMI dataset. This dataset has been extracted from the public Hepatitis C Virus (HCV) for Egyptian patients dataset available on Kaggle.
We can change the range of values considered when defining bins, by setting values for the minimum and maximum values.
For example, in our dataset the range of values for our Age attribute is from 32 to 61 years, but we would like to create bins that range from 18 years up to 75, as this is the potential age range of our survey.
In this case, you can set the min parameter to 18, and the max to 75. The formula in this case would be
discEqualWidth($"Age", 5, False, 18, 75). If you want to leave the default value for the rank parameter, and just set the last two min and max parameters, you do not need to specify a rank value, but by doing this you are no longer able to identify parameters by their position, otherwise 18 would appear to be the value for the rank. To get around this, you simply need to add the name of the parameter you are defining to the function, after the skipped parameter:discEqualWidth($"Age", 5, min=18, max=75).In our example, 5 bins have been created, but there are only values currently available for 3 of the 5 groups (no values in the lowest and highest value bins, for example from 18 to 30, and from 65 to 75).
discretize¶
The discretize function discretizes values of a selected attribute into bins of equal width, or with the same number of values or according to cutoff values.
See also
For more details on each specific discretization method, check out the specific topics:
disc (with cutoffs)
Parameters
discretize(column, nvalue, cutoffs, mode, rank, quantile, min, max)
Parameter |
Description |
|---|---|
column |
The attribute whose values we want to discretize. The column parameter is mandatory. |
nvalue |
The number of bins you want to create. This value can be any number, up to the number of rows in the dataset. The nvalue parameter is mandatory if the mode parameter is ef (Equal Frequency) or ew (Equal Width). |
cutoffs |
The cutoff values that will be used to discretize values into ranges. All cutoff points must be enclosed in square brackets. |
mode |
The method you want to use to discretize values. Possible values are: |
rank |
By default, the central value of each range is displayed. If instead we want to display a ranking number for each range, the rank value must be set to |
quantile |
If set to |
min |
If required, you can set a minimum value, which may not correspond to the values currently present in the dataset. For example, in our dataset the minimum value for the age attribute is currently 32, but we would like to create bins that range from 18 years of age, as this is the potential age range of our survey. In this case, you can set the minimum value to 18. |
max |
If required, you can set a maximum value, which may not correspond to the values currently present in the dataset. For example, in our dataset the maximum value for the age attribute is currently 61, but we would like to create bins that range up to 80, as this is the potential age range of our survey. In this case, you can set the maximum value to 75. |
Example - discretize(column, nvalue, mode=mode)
The following example uses the Age_BMI dataset. This dataset has been extracted from the public Hepatitis C Virus (HCV) for Egyptian patients dataset available on Kaggle.
Note
Given the high number of parameters in the task, it is important to use keywords to identify the parameters we are providing values for (e.g. mode=”ef”), so we do not need to include them all in every function.
In the Age_BMI dataset, we have added a new attribute, called Age_Disc, to the dataset to contain the discretized values of the Age attribute.
In this new attribute we have divided the Age values into 5 different bins of equal width, with the formula
discretize($"Age", 5, mode="ef").The resulting 5 bins display the central value for each bin: 35, 40, 46, 52, 58.
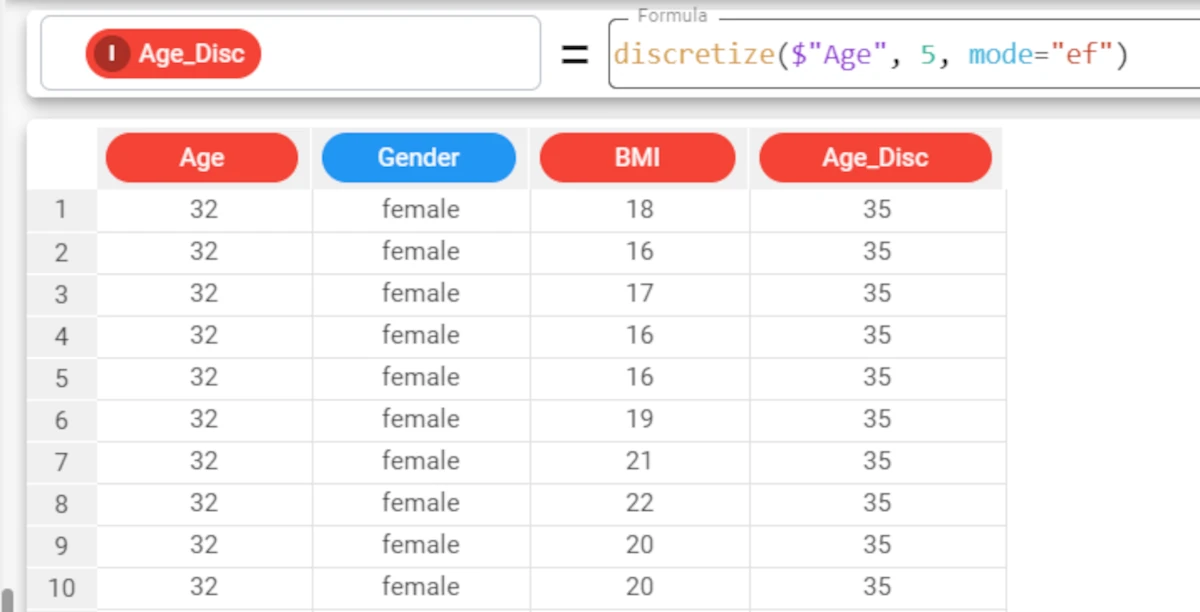
Example - discretize(column, nvalue, mode=mode)
The following example uses the Age_BMI dataset. This dataset has been extracted from the public Hepatitis C Virus (HCV) for Egyptian patients dataset available on Kaggle.
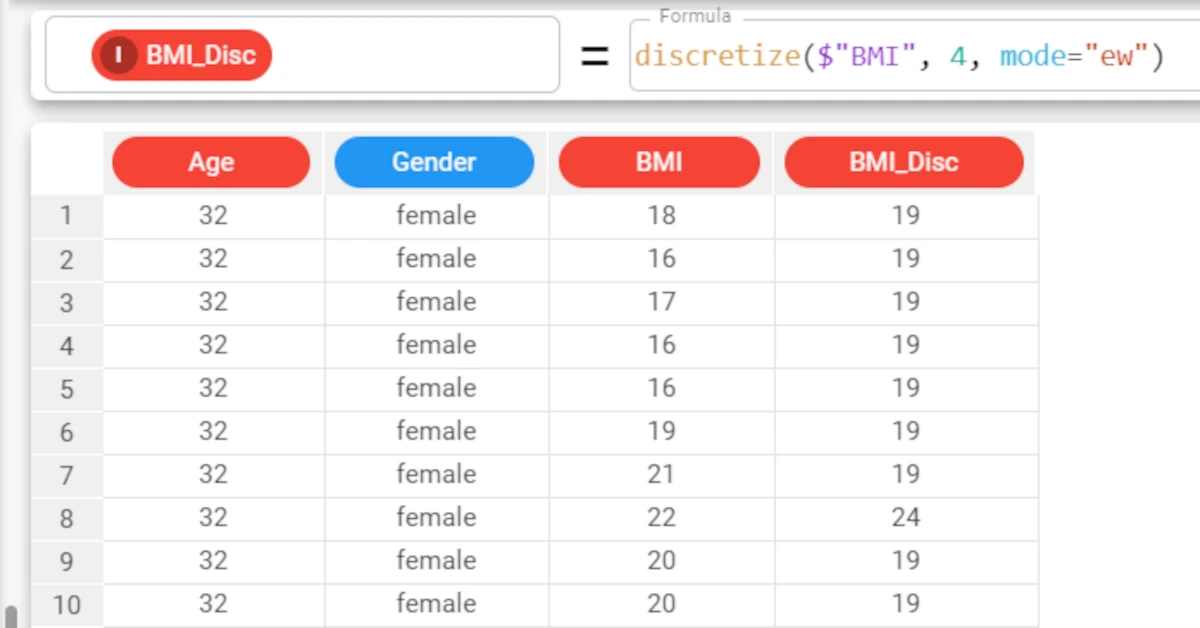
In this example, we will create another attribute, called BMI_Disc, which we can use to display the results of the discretized values of the BMI attribute.
This time we will use the Equal Width discretization method to create 4 bins with the same range of values.
The formula will consequently be:
discretize($"BMI", 4, mode="ew").The resulting 4 bins will display the central values for each bin: 19, 24, 30, 35.
Example - discretize(column, nvalue, cutoffs)
The following example uses the Age_BMI dataset. This dataset has been extracted from the public Hepatitis C Virus (HCV) for Egyptian patients dataset available on Kaggle.
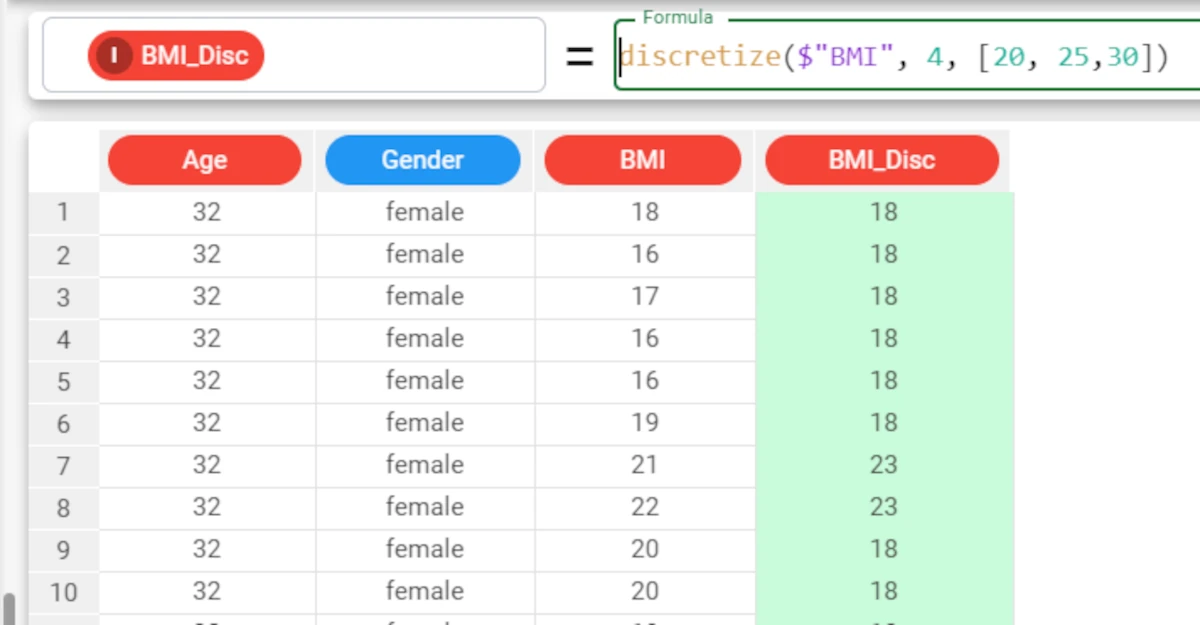
In the final example, we will again divide the BMI attribute into 4 bins, using the Disc_BMI attribute to display the results, but this time using cutoff values that we will insert into the formula.
To create 4 bins we must enter three cut-off points, which in our example are 20, 25 and 30.
The formula will consequently be:
discretize($"BMI", 4, [20,25,30]).The results display the central value for each range created using the cut-off values we supplied.
isAttribute¶
The isAttribute function checks whether a specified attribute is present in the dataset. The result can either be returned as a Boolean (True / False) or binary (0/1) result.
This function is useful for large datasets.
Parameters
isAttribute(name, binary)
Parameter |
Description |
|---|---|
name |
The name of the attribute we are looking for. The name parameter is mandatory. |
binary |
If set to |
Example - isAttribute(name)
The following example uses the Adult dataset.
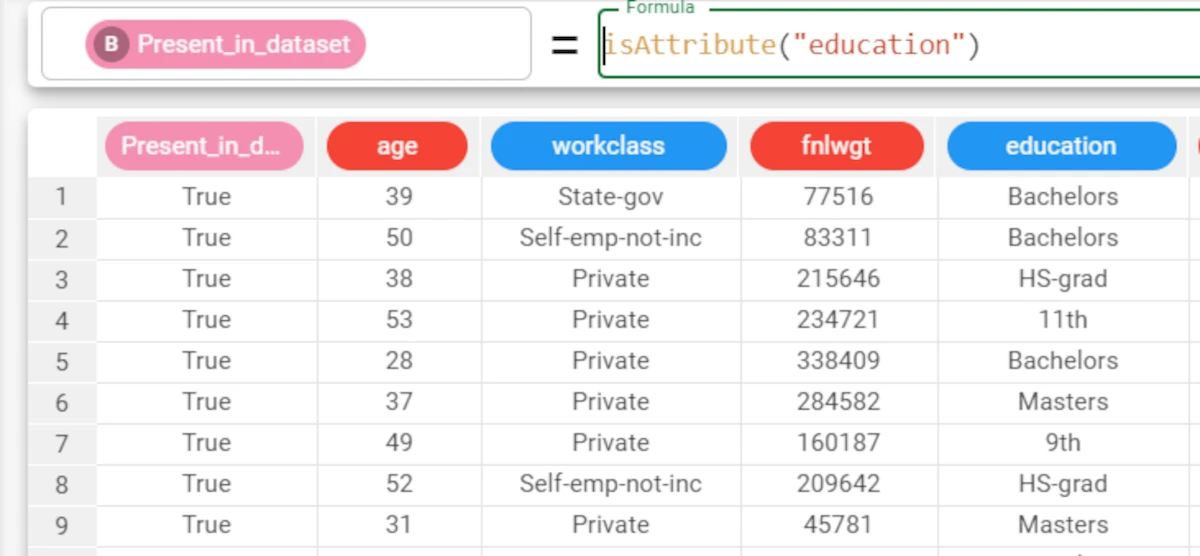
In the adult dataset, we have added a new attribute, called Present_in_dataset, where the results of the isAttribute function will be saved.
We will then check to see whether there is an attribute called education in the dataset, with the formula
isAttribute("education").As we have not specified a value for the binary parameter, the results will be expressed as a Boolean value: True in this specific case.
Example - isAttribute(name, binary)
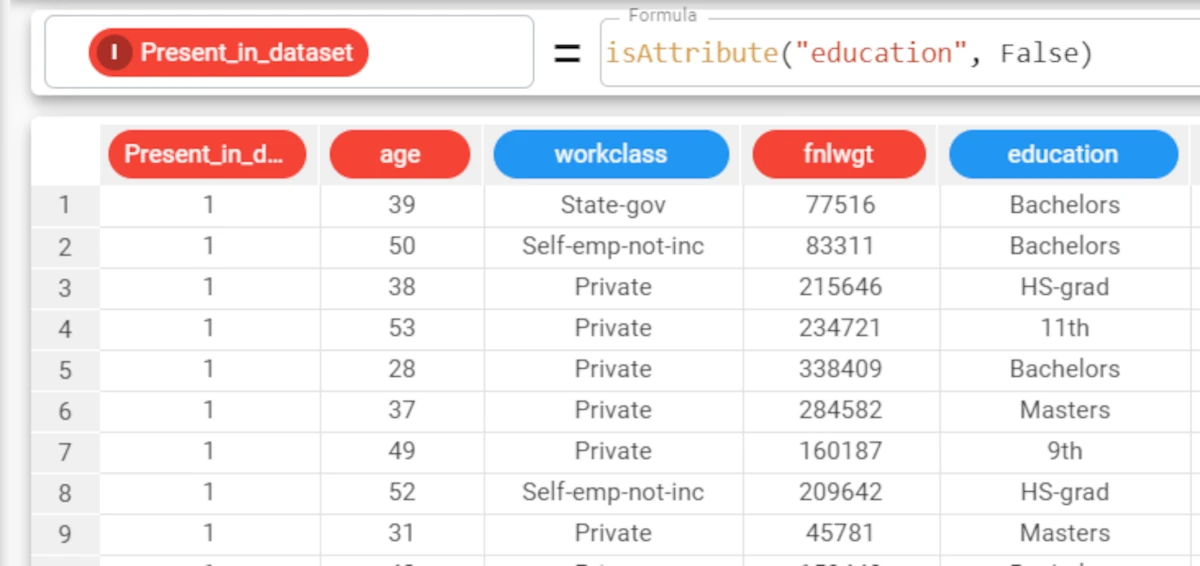
The following example uses the Adult dataset.
If we wanted to receive the result in boolean
0/1value form instead of aTrue/False, we would need to specify that the binary parameter should be False, with the following formula:isAttribute("education", False).
isFloat¶
The isFloat function checks whether the data type of the attribute specified in the string parameter is continuous.
Parameters
isFloat(string, binary)
Parameter |
Description |
|---|---|
string |
The nominal attribute to be tested. The string parameter is mandatory. |
binary |
If it is |
Example - isFloat(string, binary)
The following example uses the Sales Videogames dataset.
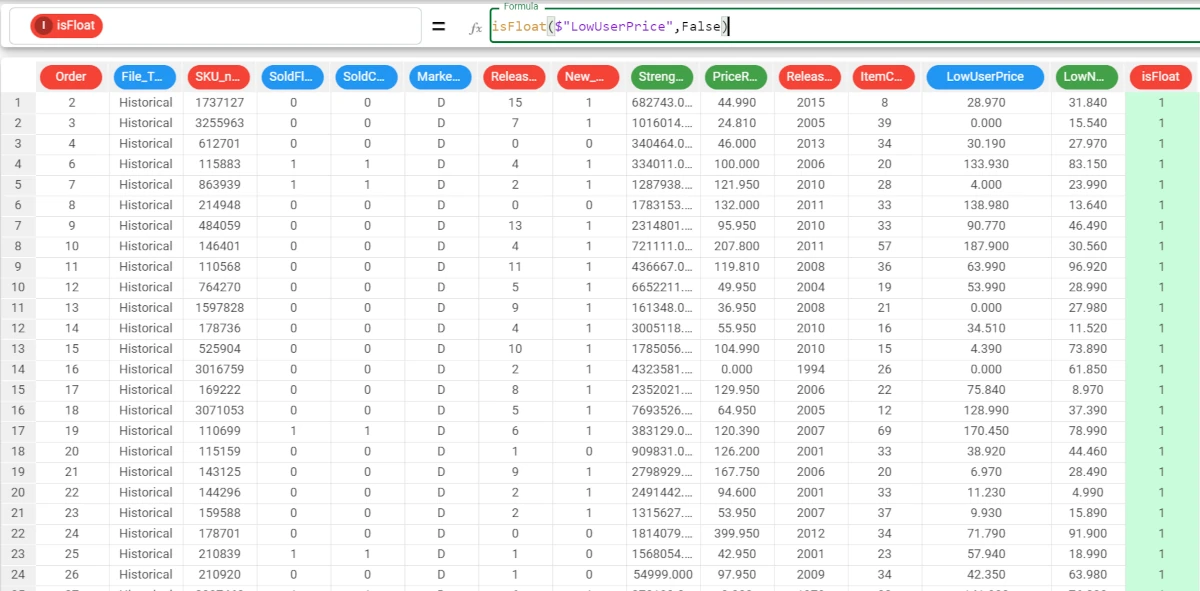
In this example, we want to check if the attribute LowUserPrice is a Float attribute.
We add a new attribute and write the following formula:
isFloat($"LowUserPrice",False).We specified
Falseas binary parameter, so the results will be provided as 1 (True) or 0 (False).
isType¶
The isType function checks whether the data type of the attribute specified in the string parameter corresponds to the data type specified in the type parameter.
Parameters
isType(string, type, binary)
Parameter |
Description |
|---|---|
string |
The nominal attribute to be tested. The string parameter is mandatory. |
type |
The attribute type we want to verify on the string. The type parameter is mandatory. |
binary |
If the optional binary parameter is True, or not specified, results will be provided as boolean values ( |
Note
- Attribute types you can verify in this function:
nominal
integer
continuous
binary
percentage
currency
date
datetime
month
week
quarter
time
Example - isType(string, type)
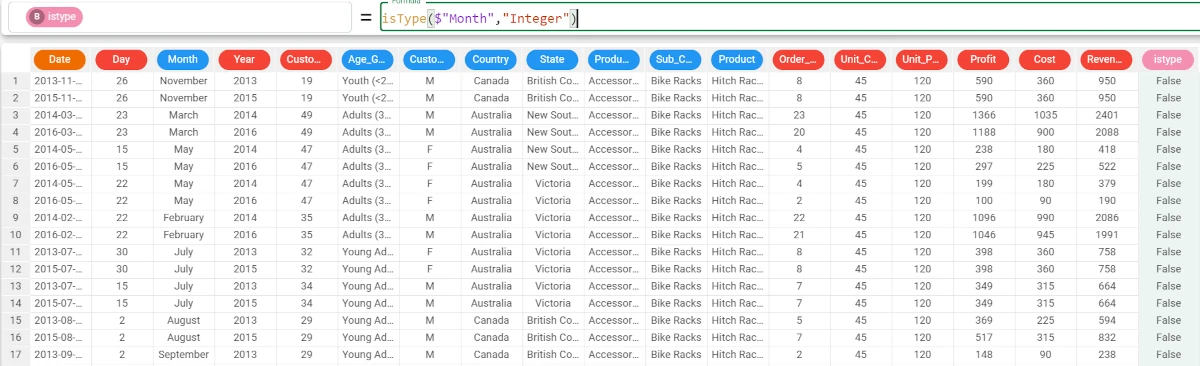
The following example uses the IsFunctions dataset.
In this example, we want to check if the Month attribute is an integer attribute.
Add a new attribute where we can use the isType function.
The function has returned False, because the attribute Month hasn’t got numeral values.
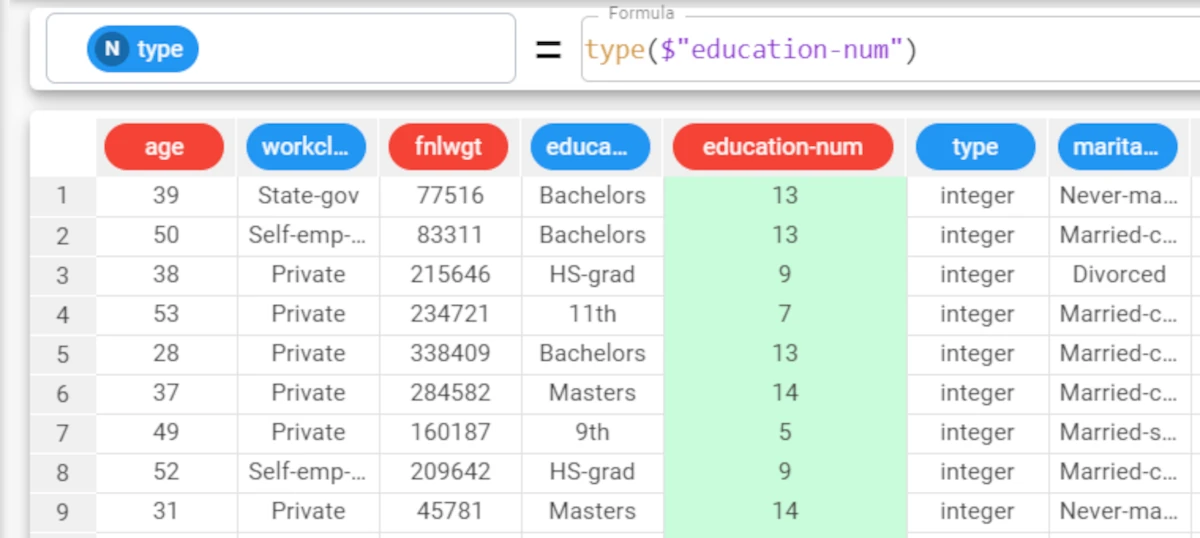
type¶
The type function returns the data type of the selected column as a nominal value.
Parameters
type(column)
Parameter |
Description |
|---|---|
column |
The attribute whose data type we want to return. The column parameter is mandatory. |
Example - type(string, type)
The following example uses the Adult dataset.
In the adult dataset, we have added a new type attribute, where the data type of the education-num attribute has been retrieved, using the formula
type($"education_num").The data type has been correctly returned as integer (expressed as a nominal attribute as “integer” is a string value).